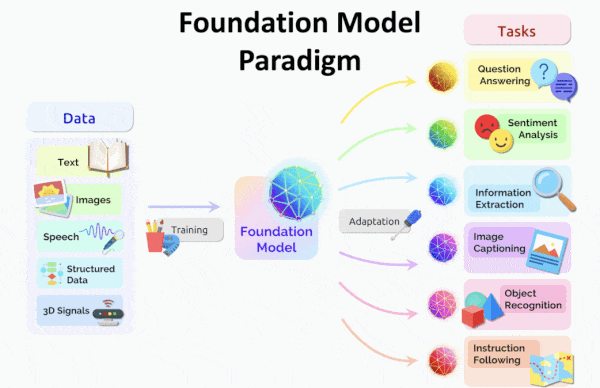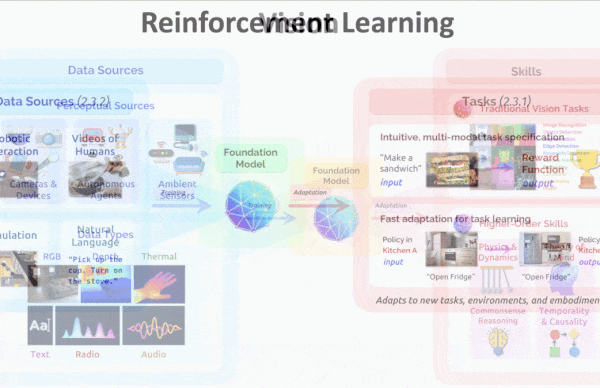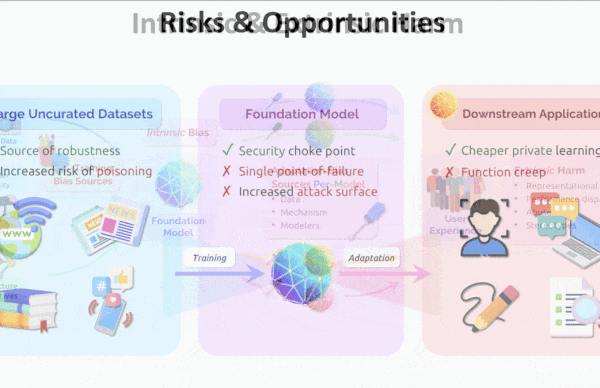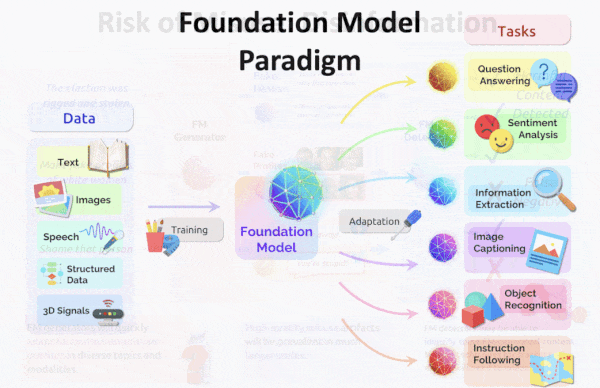
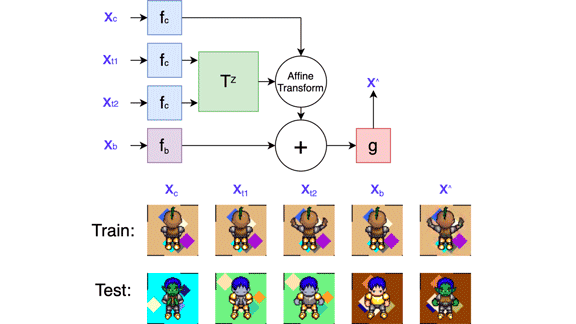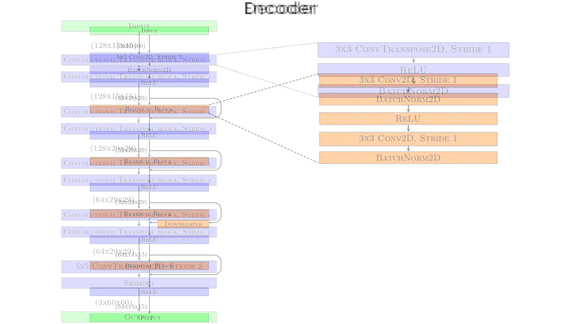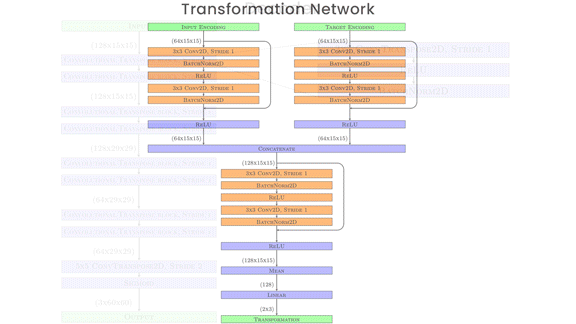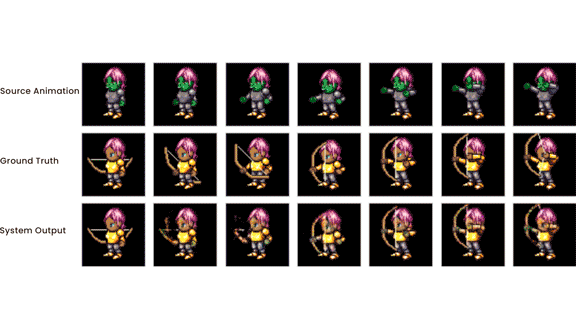
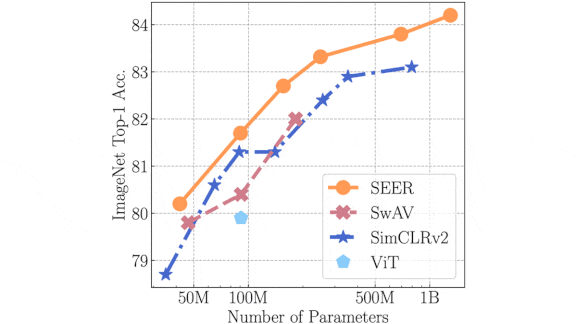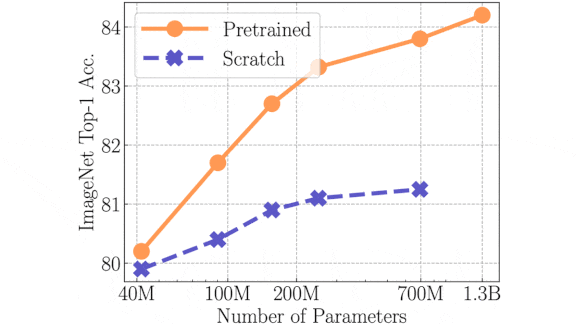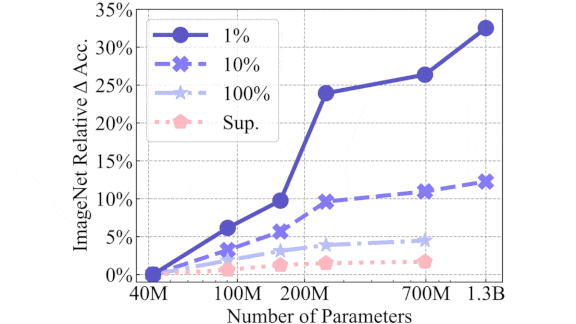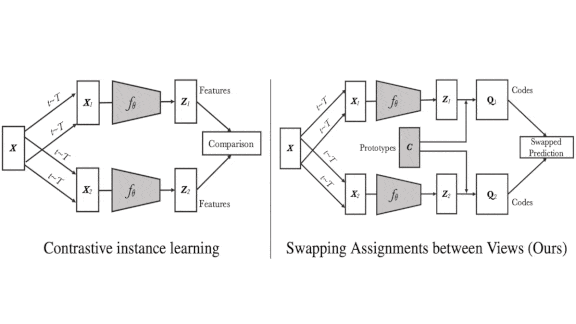
Unsupervised Learning
Unsupervised Data Pruning: New method removes useless machine learning data.
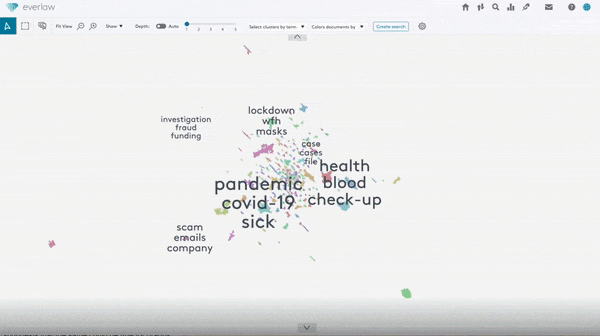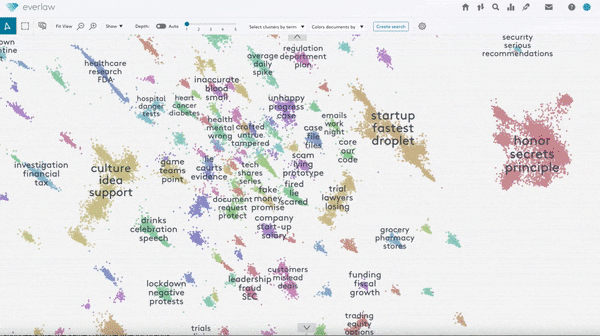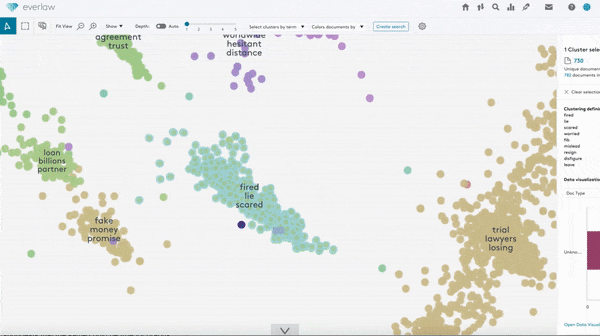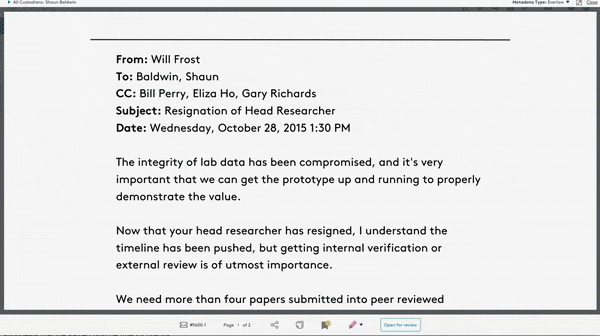
Large datasets often contain overly similar examples that consume training cycles without contributing to learning. A new paper identifies similar training examples, even if they’re not labeled.