
A new study examines a major strain of recent research: huge models pretrained on immense quantities of uncurated, unlabeled data and then fine-tuned on a smaller, curated corpus. The sprawling 200-page document evaluates the benefits and risks.
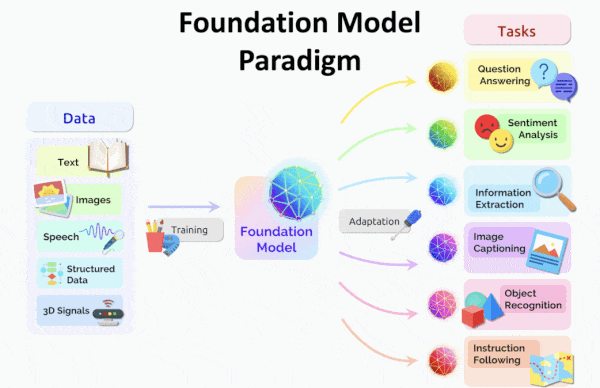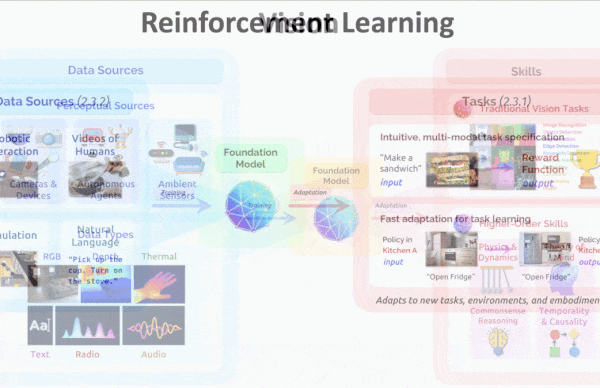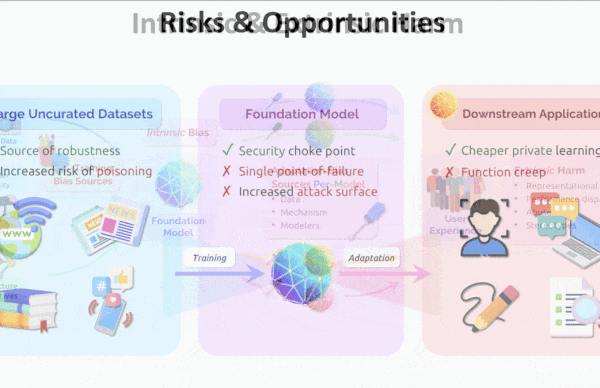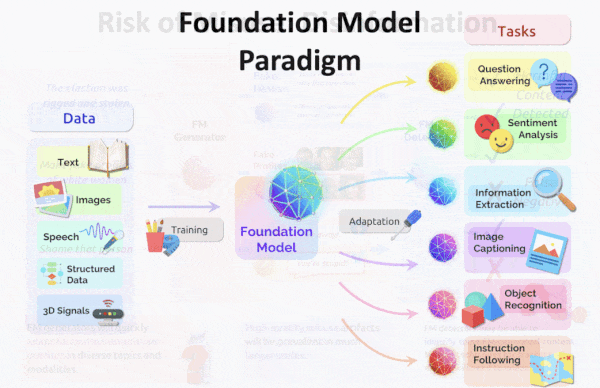
What’s new: Researchers at Stanford’s Human AI Institute proposed ways to prevent large language models like BERT, CLIP, and GPT-3 — which they call foundation models for their ability to support a plethora of high-performance, fine-tuned variations — from manifesting hidden flaws after fine-tuning.
Key insight: The very factors that make large language models so valuable — unsupervised training followed by adaptation to a wide variety of tasks (indeed, some outside the domain of natural language) — make them potential vectors for harm. Defects in the foundation, such as biases learned from uncurated training data, can emerge in fine-tuned versions as challenges to fairness, ethical use, and legal compliance. Moreover, this approach encourages a technological monoculture in which a limited number of architectures, despite their strengths, proliferate their weaknesses across various domains.
Toward solid foundations: The authors recommend ways to minimize unwelcome surprises such as unwitting contributions to social or economic inequality, unemployment, or disinformation:
- Develop metrics that predict ways in which a model may instill harmful behavior in its fine-tuned offspring and standardized ways to document these metrics, for instance data sheets.
- Create incentives for companies that develop large-scale, unsupervised models to publicly test and audit their work. Warn developers of follow-on systems to vet them thoroughly for undesired behaviors prior to deployment.
- Counterbalance the power of deep-pocketed companies by making it easier for academic institutions and independent researchers to develop such models, for instance through a National Research Cloud and crowdsourced efforts to recreate GPT-style language models.
Behind the news: The advent of BERT in 2018 accelerated adoption of unsupervised pretraining in natural language models and spawned ever-larger networks as researchers scaled up the concept and experimented with architectures. The approach has spun off fine-tuned models not only for language tasks like conversation, image captioning, and internet search but also far-flung applications including modeling proteins, testing mathematical theorems, generating computer code, image recognition, image generation, and reinforcement learning.
Why it matters: Such models can cause harm due to intrinsic flaws by, say, propagating data-driven biases against members of particular religions or other groups) and extrinsic flaws, such as energy-intensive training that leaves a large carbon footprint and misuse such as propagating disinformation. Deep learning systems developed without foresight run the risk of becoming a burden rather than a boon.
We’re thinking: The future of AI may well be built on a limited variety of foundation models. In any case, the painstaking work of checking models for flaws beats cleaning up messes caused by neglecting to do so.