Machine Learning Research
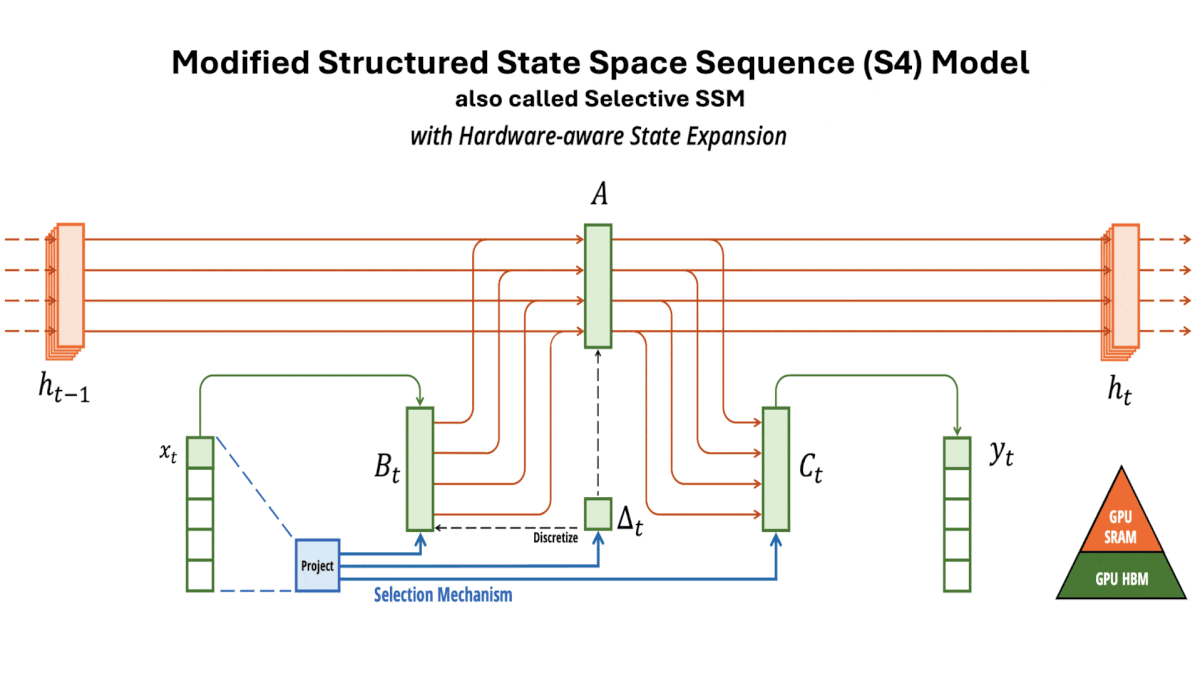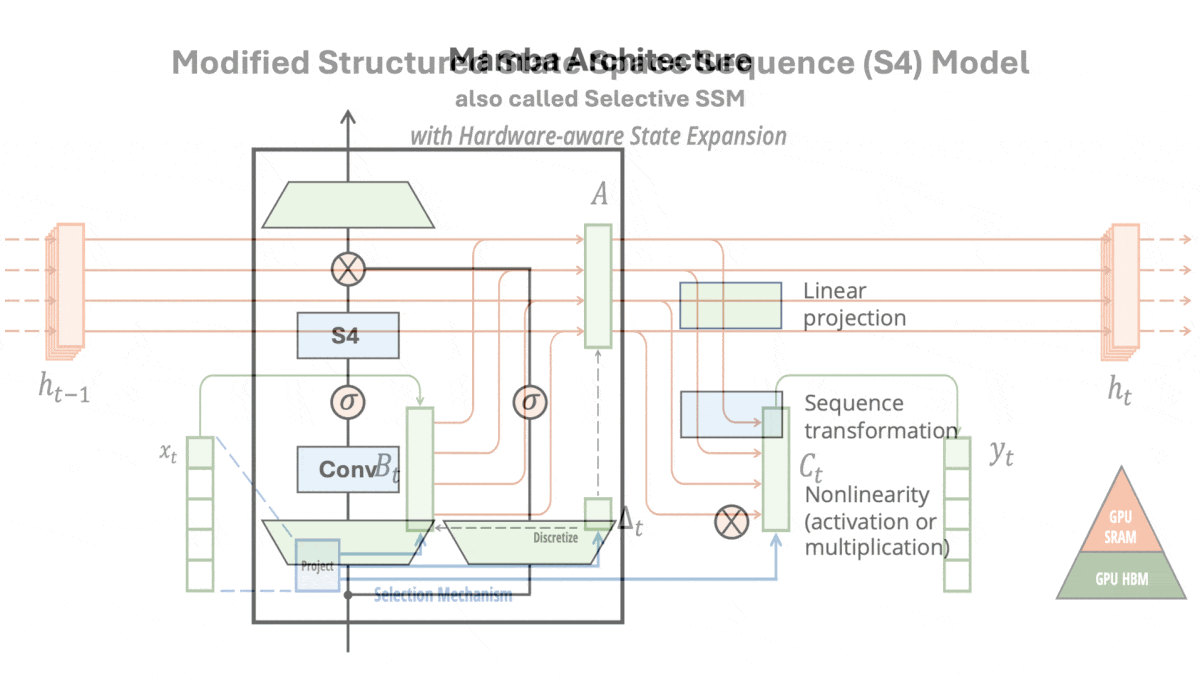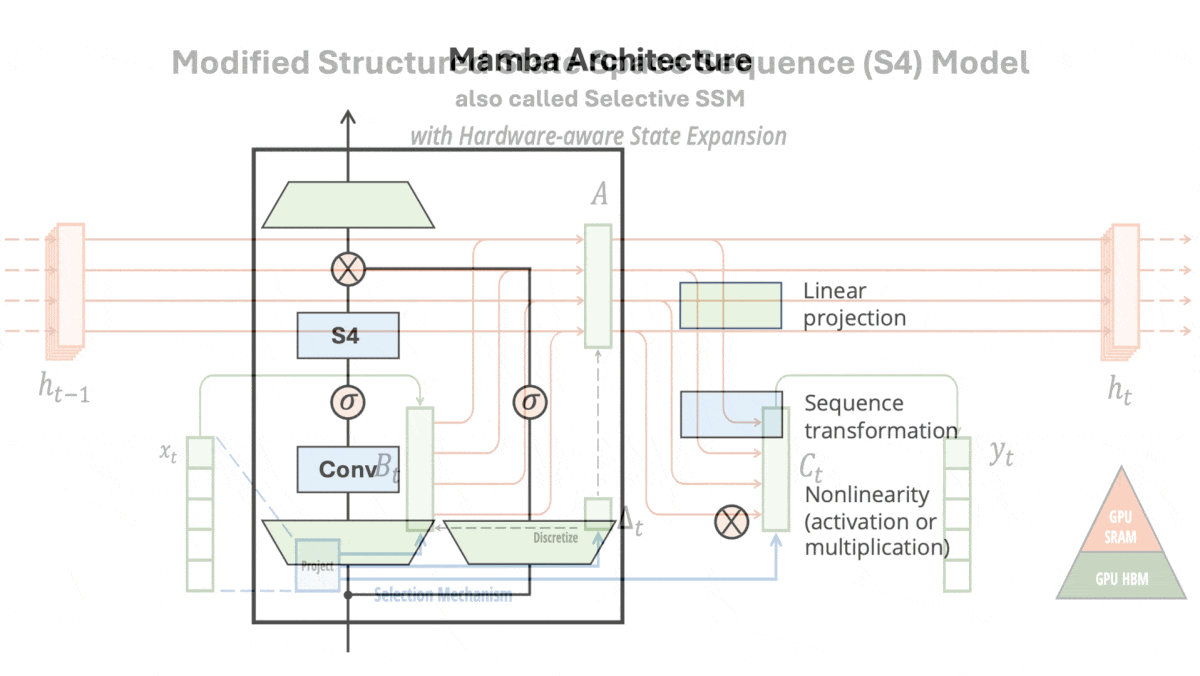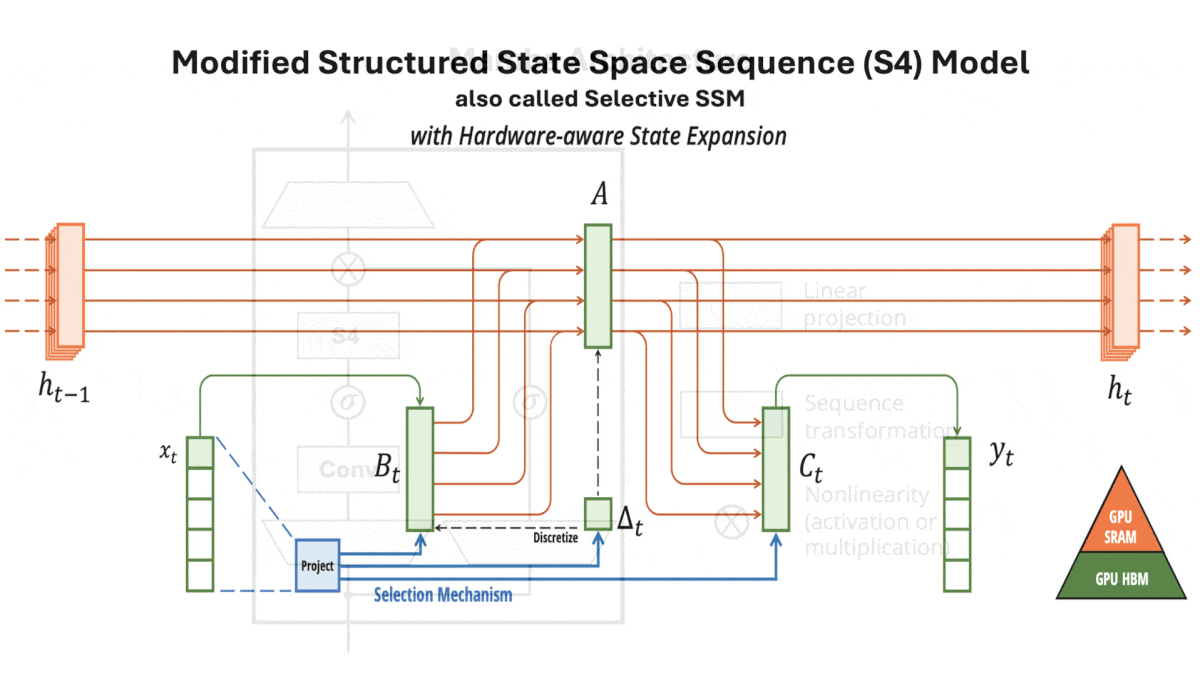
A Transformer Alternative Emerges: Mamba, a new approach that may outperform transformers
An architectural innovation improves upon transformers — up to 2 billion parameters, at least...
313 Posts
Stay updated with weekly AI News and Insights delivered to your inbox