
In some animated games, different characters can perform the same actions — say, walking, jumping, or casting spells. A new system learned from unlabeled data to transfer such motions from one character to another.
What’s new: Cinjon Resnick at New York University and colleagues at Nvidia, Technical University of Berlin, and Google developed a system designed to isolate changes in the pose of a two-dimensional figure, or sprite, and apply them to another sprite. While earlier approaches to solving this problem require labeled data, the new system is self-supervised.
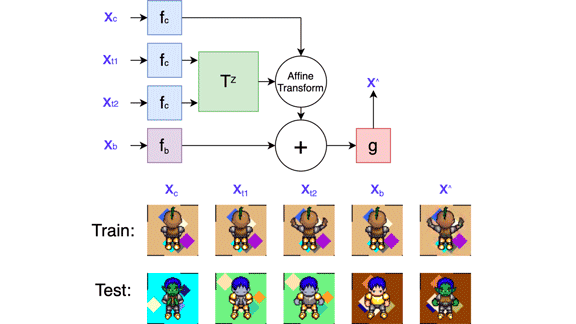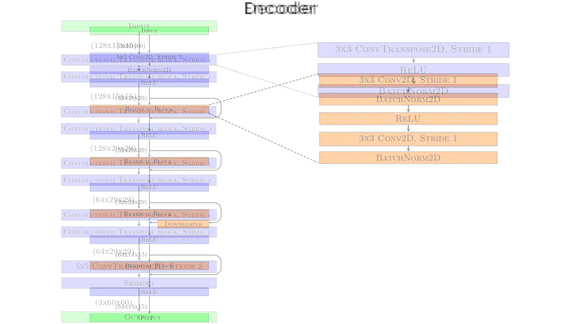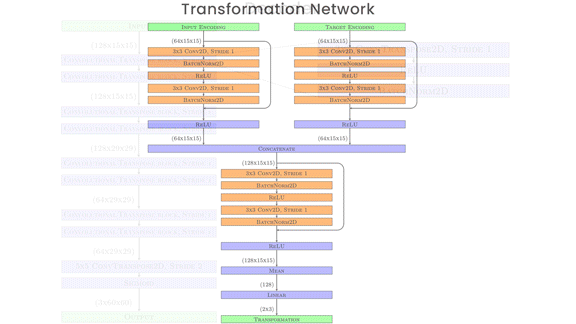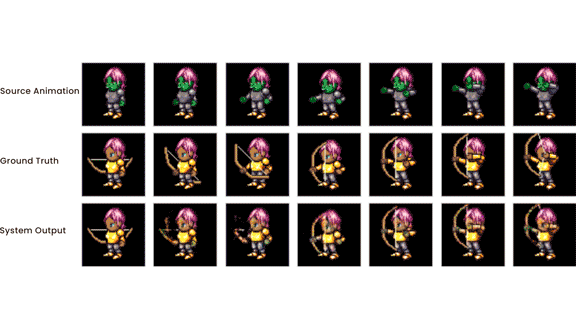
Key insight: A 2D animation consists of three elements: a sprite, the sprite’s motion and any special effects, and a background (which remains static in this work). Separate neural networks optimizing a variety of loss terms can learn to disentangle these elements, compute their changes from frame to frame, and recombine them to produce a novel frame.
How it works: The system comprises four convolutional neural networks: two encoders, a transformation network, and a decoder. It generates a new frame given an image of a target sprite, a background, and two frames of animation showing a source sprite in motion — say, the initial frame and the one showing the pose, position, or other attributes to be mapped onto the target. During training, the images of the target sprite, background, and first frame of the animation were identical. The training and test sets consisted of several hundred animated video game characters performing various motions.
- One encoder generated a representation of the background based on the background reference image. The other generated separate representations of the target sprite and two animation frames.
- The transformation network used the representations of the two animation frames to generate a matrix describing how the sprite changed. The authors combined the various representations by multiplying the matrix by the target sprite’s representation and adding the background representation.
- The decoder used the result to produce an image of the target sprite, against the background, in the source sprite’s position in the second animation frame.
- The authors trained these components at once using a loss function consisting of three terms. The first term encouraged the background representation to remain constant from frame to frame. The second encouraged the transformed representation of the target sprite — that is, the transformation network’s matrix multiplied by the initial target sprite representation — to be similar to that of the source sprite in the second animation frame. The third minimized the pixel difference between the generated image and the second animation frame.
Results: The authors compared their system with Visual Dynamics. It underperformed the competition, achieving a mean squared error of ~20 versus ~16 — but Visual Dynamics is a supervised system that requires labeled training data.
Why it matters: A collection of networks that study different aspects of a dataset, and then compare and combine the representations they generate, can yield valuable information when labels aren’t available.
We’re thinking: Possibly a useful tool for animators. Definitely a new toy for remix culture.