
LoRA
Memory-Efficient Optimizer: A method to reduce memory needs when fine-tuning AI models
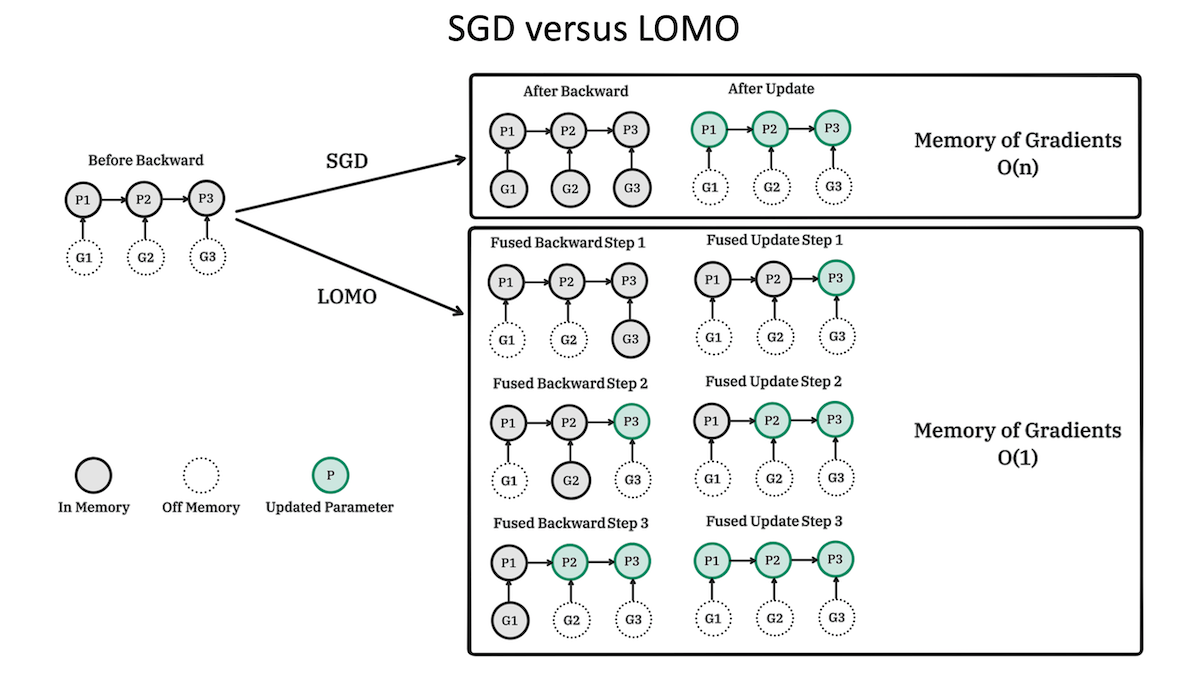
Researchers devised a way to reduce memory requirements when fine-tuning large language models. Kai Lv and colleagues at Fudan University proposed low memory optimization (LOMO), a modification of stochastic gradient descent that stores less data than other optimizers during fine-tuning.