
Researchers devised a way to reduce memory requirements when fine-tuning large language models.
What's new: Kai Lv and colleagues at Fudan University proposed low memory optimization (LOMO), a modification of stochastic gradient descent that stores less data than other optimizers during fine-tuning.
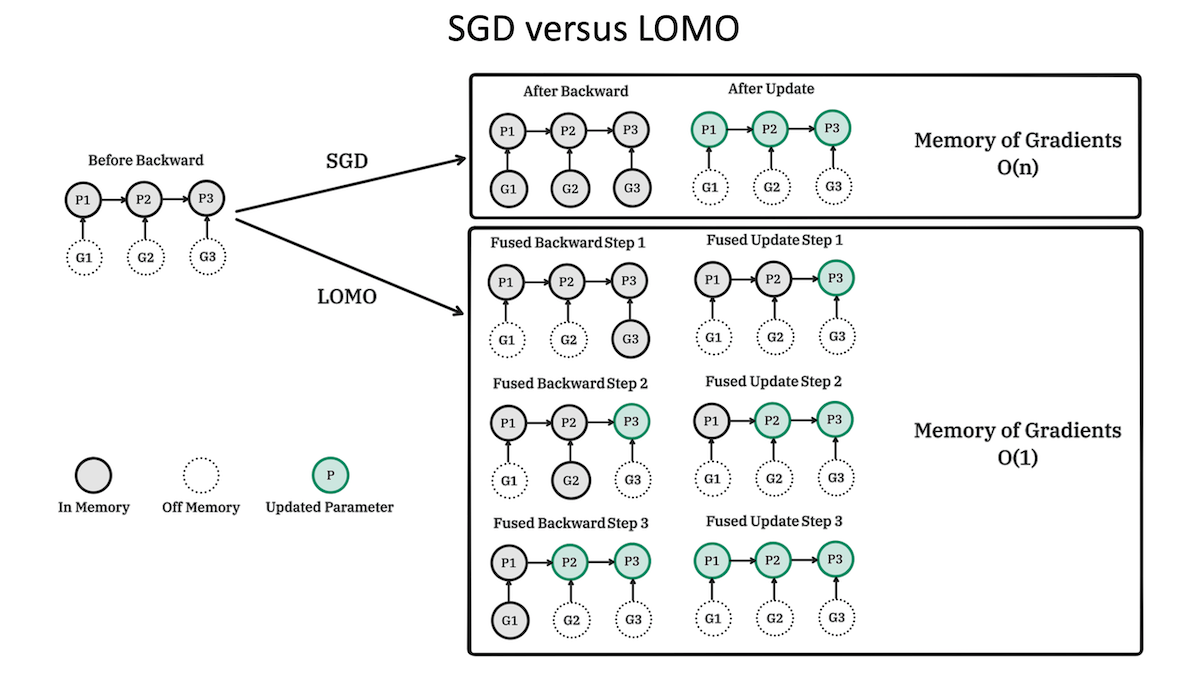
Key insight: Optimizers require a lot of memory to store an entire network’s worth of parameters, gradients, activations, and optimizer states. While Adam has overtaken stochastic gradient descent (SGD) for training, SGD remains a popular choice for fine-tuning partly because it requires less memory (since it stores fewer optimizer states). Nonetheless, SGD must store an entire network’s gradients — which, with state-of-the-art models, can amount to tens or hundreds of gigabytes — before it updates the network all at once. Updating the network layer by layer requires storing only one layer’s gradients — a more memory-efficient twist on typical SGD.
How it works: The authors fine-tuned LLaMA on six datasets in SuperGLUE, a benchmark for language understanding and reasoning that includes tasks such as answering multiple-choice questions.
- The authors modified SGD to compute gradients for one layer and update that layer’s weights before advancing to the next.
- To avoid the potential for exploding or vanishing gradients, in which gradients from later layers either expand or diminish as they backpropagate through the network, LOMO normalized the gradients, scaling them to a predetermined range throughout the network. LOMO used two backward passes: one to compute the magnitude of the gradient for the entire network, and another to scale each layer’s gradient according to the total magnitude and then update its parameters.
Results: LOMO required less memory than popular optimizers and achieved better performance than the popular memory-efficient fine-tuning technique LoRA.
- The authors fine-tuned separate instances of LLaMA-7B using LOMO and two popular optimizers, SGD and AdamW (a modified version of Adam). They required 14.6GB, 52.0GB, and 102.2GB of memory respectively. In particular, they all required the same amount of memory to store model parameters (12.55GB) and activations (1.79GB). However, when it came to gradients, LOMO required only 0.24GB while SGD and AdamW each required 12.55GB. The biggest difference was optimizer state memory: LOMO required 0GB, SGD required 25.1GB, and Adam required 75.31GB.
- The authors also compared LOMO to LoRA, which works with an optimizer (in this case, AdamW) to learn to change each layer’s weight matrix by a product of two smaller matrices. They performed this comparison with LLaMAs of four sizes on six datasets. LOMO achieved better accuracy in 16 of the 24 cases, and its average accuracy across datasets exceeded LoRA’s at each model size. For example, the 65 billion-parameter LOMO-tuned LLaMA averaged 89.9 percent accuracy, and the 65 billion-parameter LoRA/AdamW-tuned LLaMA averaged 89.0 percent accuracy.
Why it matters: Methods like LoRA save memory by fine-tuning a small number of parameters relative to a network’s total parameter count. However, because it adjusts only a small number of parameters, the performance gain from fine-tuning is less than it could be. LOMO fine-tunes all parameters, maximizing performance gain while reducing memory requirements.
We're thinking: SGD’s hunger for memory is surprising. Many developers will find it helpful to have a memory-efficient alternative.