CLIP
Different Media, Similar Embeddings: ImageBind, the AI model that binds data from seven data types at once
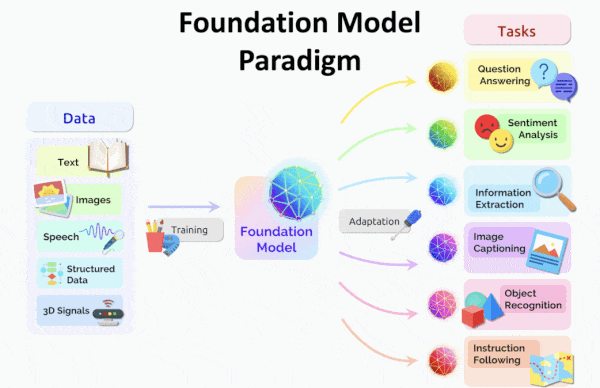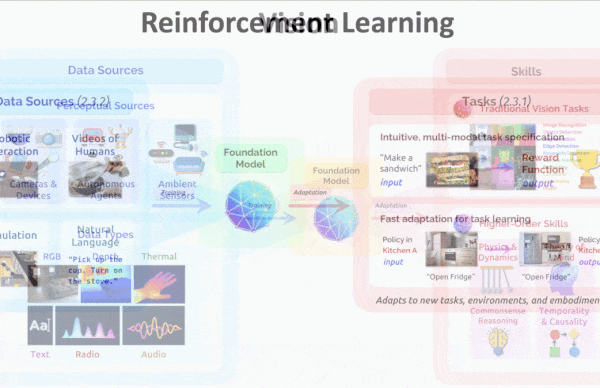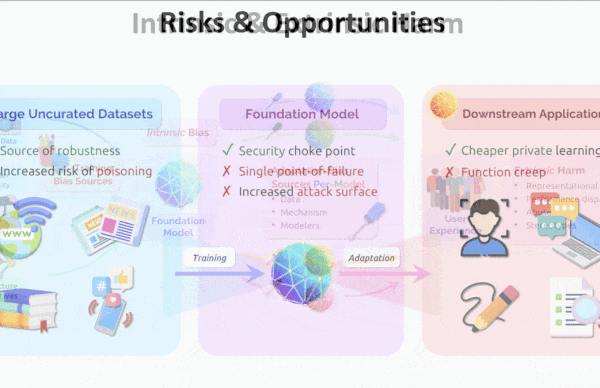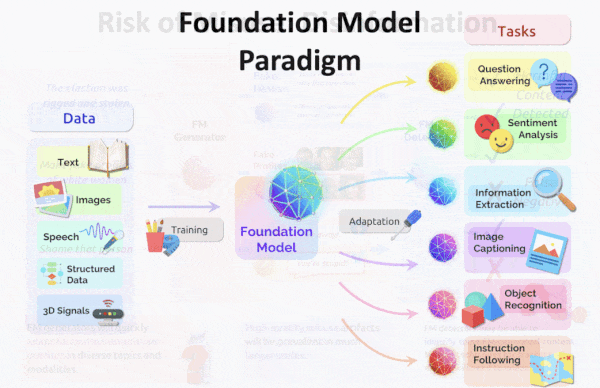
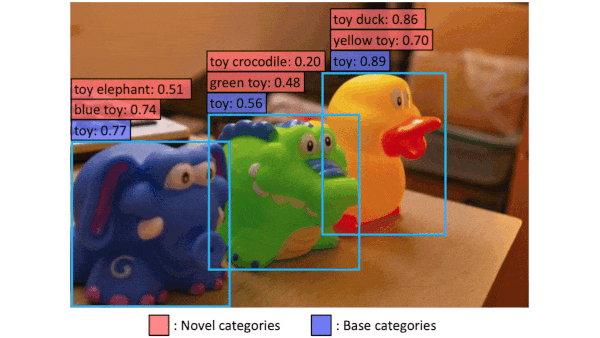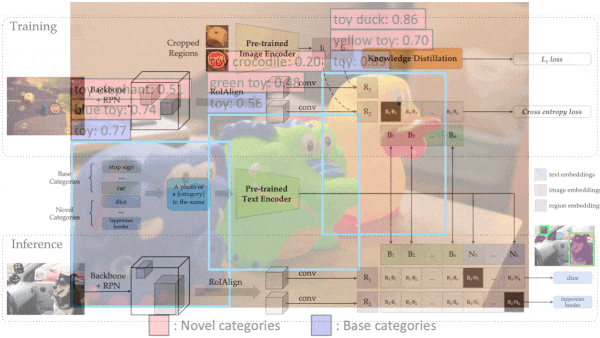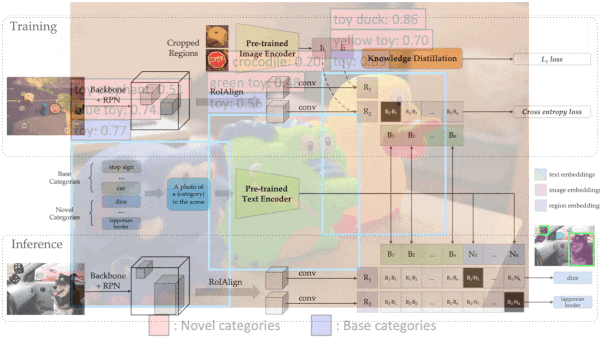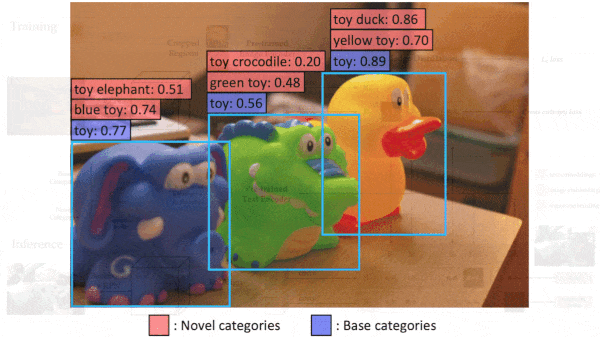
The ability of OpenAI’s CLIP to produce similar embeddings of a text phrase and a matching image opened up applications like classifying images according to labels that weren’t in the training set. A new model extends this capability to seven data types.