
Dear friends,
Much has been said about many companies’ desire for more compute (as well as data) to train larger foundation models. I think it’s under-appreciated that we have nowhere near enough compute available for inference on foundation models as well.
Years ago, when I was leading teams at Google, Baidu, and Stanford that focused on scaling up deep learning algorithms, many semiconductor manufacturers, data center operators, and academic researchers asked me whether I felt that AI technology would continue to make good use of more compute if they kept on delivering it. For many normal desktop processing workloads, like running a web browser or a text editor, having a faster CPU doesn’t help that much beyond a certain point. So do we really need faster and faster AI processors to train larger and larger models? Each time, I confidently replied “yes!” and encouraged them to keep scaling up compute. (Sometimes, I added half-jokingly that I had never met a machine learning engineer who felt like they had enough compute. 😀)
Fortunately, this prediction has been right so far. However, beyond training, I believe we are also far from exhausting the benefits of faster and higher volumes of inference.
Today, a lot of LLM output is primarily for human consumption. A human might read around 250 words per minute, which is around 6 tokens per second (250 words/min / (0.75 words/token) / (60 secs/min)). So it might initially seem like there’s little value to generating tokens much faster than this.
But in an agentic workflow, an LLM might be prompted repeatedly to reflect on and improve its output, use tools, plan and execute sequences of steps, or implement multiple agents that collaborate with each other. In such settings, we might easily generate hundreds of thousands of tokens or more before showing any output to a user. This makes fast token generation very desirable and makes slower generation a bottleneck to taking better advantage of existing foundation models.
That’s why I’m excited about the work of companies like Groq, which can generate hundreds of tokens per second. Recently, SambaNova published an impressive demo that hit hundreds of tokens per second.
Incidentally, faster, cheaper token generation will also help make running evaluations (evals), a step that can be slow and expensive today since it typically involves iterating over many examples, more palatable. Having better evals will help many developers with the process of tuning models to improve their performance.
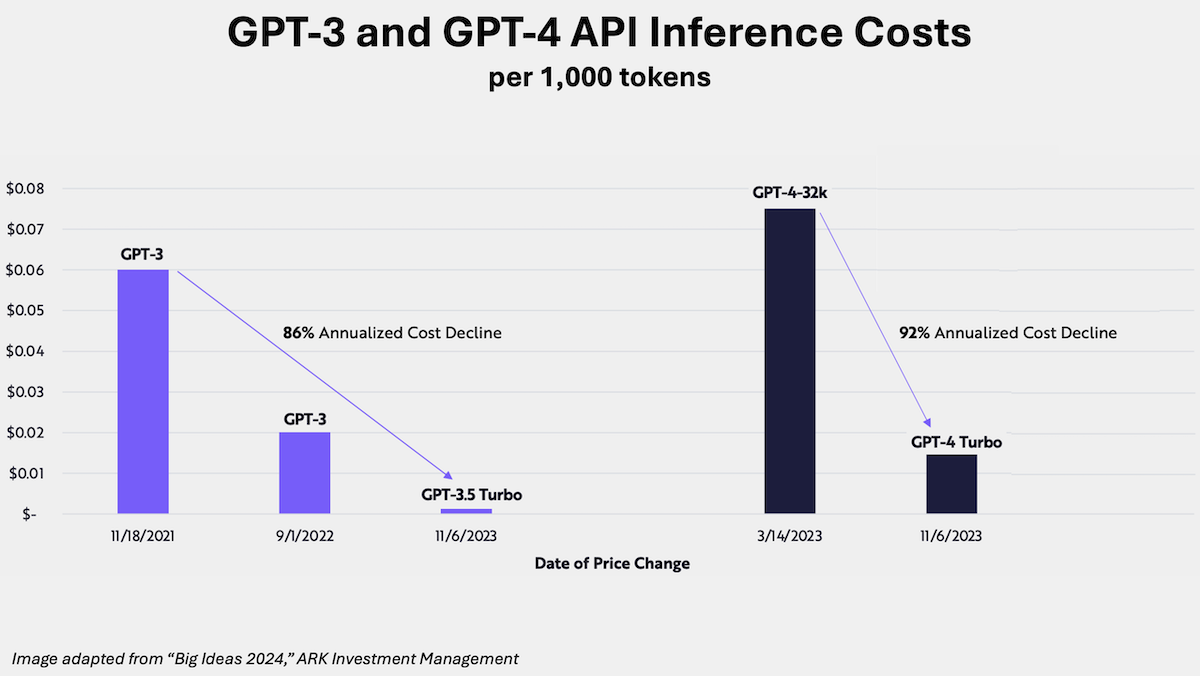
Fortunately, it appears that both training and inference are rapidly becoming cheaper. I recently spoke with Cathie Wood and Charles Roberts of the investment firm ARK, which is famous for its bullish predictions on tech. They estimate that AI training costs are falling at 75% a year. If they are right, a foundation model that costs $100M to train this year might cost only $25M to train next year. Further, they report that for “enterprise scale use cases, inference costs seem to be falling at an annual rate of ~86%, even faster than training costs.”
I don’t know how accurate these specific predictions will turn out to be, but with improvements in both semiconductors and algorithms, I do see training and inference costs falling rapidly. This will be good for application builders and help AI agentic workflows lift off.
Keep learning!
Andrew