
The combination of language models that are equipped for retrieval augmented generation can retrieve text from a database to improve their output. Further work extends this capability to retrieve information from any application that comes with an API.
What’s new: Timo Schick and colleagues at Meta and Universitat Pompeu Fabra developed Toolformer, a self-supervised transformer that took advantage of Wikipedia, a calculator, a calendar, and other tools using the corresponding application programming interfaces (APIs).
Key insight: Some language models make API calls to an external program to execute a specific task, such as a chatbot that performs a web search before answering a question. A model can be trained to use multiple tools for a variety of tasks by adding API calls to a text dataset and fine-tuning the model on that dataset.
How it works: The authors used GPT-J to generate calls to external tools including a language model trained for question-answering; a machine translation model; a model that retrieves text snippets from Wikipedia; a calculator; and a calendar. They added the calls to CCNet, a dataset of text scraped from the Internet. Toolformer is GPT-J after fine-tuning on this dataset.
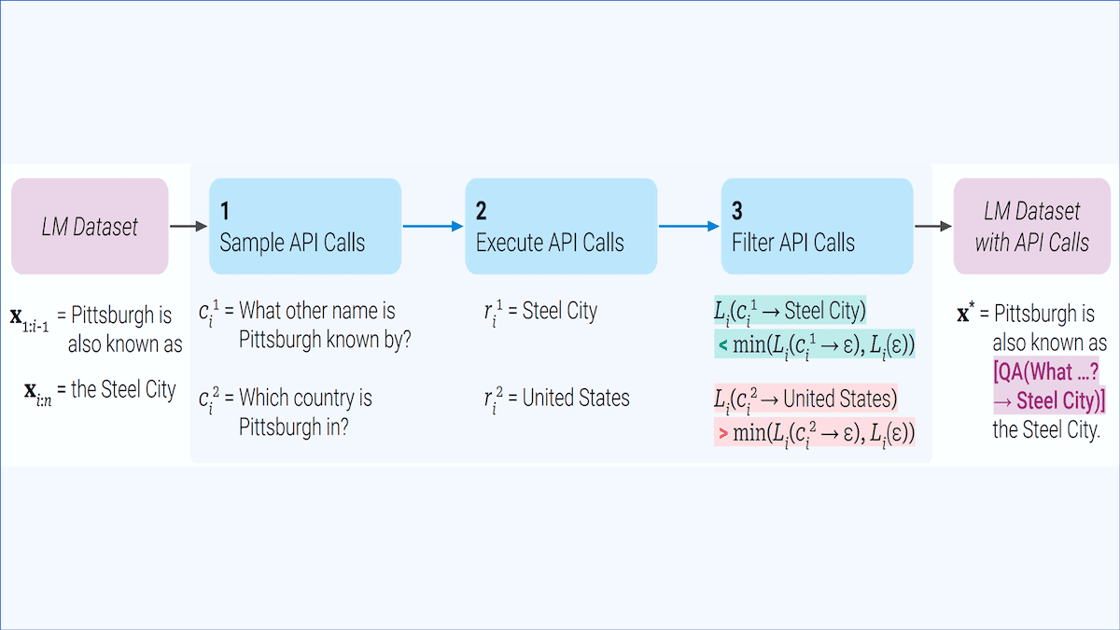
- For each external tool, the authors fed GPT-J a text prompt that encouraged the model to add calls to that tool to a given text, such as “Your task is to add calls to a Question Answering API to a piece of text,” then specifying the syntax for the call as “[QA(question)]”. They provided GPT-J with a few examples that illustrated text before and after adding the calls, such as “Joe Biden was born in Scranton, Pennsylvania” and “Joe Biden was born in [QA("Where was Joe Biden born?")] Scranton, [QA("In which state is Scranton?")] Pennsylvania,” respectively.
- GPT-J automatically added a call to an external tool, as well as the tool’s response, after almost every word in each document in CCNet. For example, given the input “Pittsburgh is also known as,” the model generated a call to ATLAS reading “[QA("What other name is Pittsburgh known by?")]”. The model added ATLAS’s response (“Steel City”), to create the output “Pittsburgh is also known as [QA("What other name is Pittsburgh known by?") → Steel City] the Steel City.”
- The authors kept calls and responses that increased GPT-J’s rate of predicting the next word correctly and discarded those that did not.
- They fine-tuned GPT-J to predict the next word in excerpts from the modified CCNet.
- If GPT-J generated a call, a separate program translated it into a proper API call to the application being addressed.
Results: Given a mathematical reasoning task, such as an elementary school-level word problem, Toolformer (6.7 billion parameters) achieved 40.4 percent accuracy on the ASDiv dataset, while GPT-3 (175 billion parameters) achieved 14.0 percent accuracy. Given a question from Web Questions, Toolformer achieved 26.3 percent accuracy, while OPT (66 billion parameters) achieved 18.6 percent accuracy and GPT-3 achieved 29.0 percent accuracy.
Yes, but: Building the fine-tuning dataset was processing-intensive. It took millions of documents to generate a few thousand useful examples of API calls to a calculator. For many developers, the computational cost of iteratively generating API calls in so many documents may prove prohibitive.
Why it matters: Giving an LLM the ability to hand off some tasks to other programs both improves the user’s experience and allows developers to focus on improving the LLM in specific areas while referring ancillary tasks to more capable systems.
We’re thinking: OpenAI added a similar capability to GPT-4 while this summary was in progress. However, the company didn’t explain how GPT-4 learned to choose which function to call and what arguments to give it. This paper provides a practical method.