
The transformer architecture is astonishingly powerful but notoriously slow. Researchers have developed numerous tweaks to accelerate it — enough to warrant a look at how these alternatives work, their strengths, and their weaknesses.
What’s new: Quentin Fournier, Gaétan Marceau Caron, and Daniel Aloise surveyed variations on the transformer, evaluating methods designed to make it faster and more efficient. This summary focuses on the variations designed to accelerate it.
The cost of attention: The attention mechanism in the original transformer places a huge burden on computation and memory; O(n2) cost where n is the length of the input sequence. As a transformer processes each token (often a word or pixel) in an input sequence, it concurrently processes — or “attends” to — every other token in the sequence. Attention is calculated by multiplying two large matrices of weights before passing the resulting matrix through a softmax function. The softmax function normalizes the matrix values to a probability distribution, bringing higher values closer to 1 and lower values near 0. This enables the transformer, when encoding a token, to use relevant tokens and ignore irrelevant tokens.
(Modified) attention is all you need: The authors identify three approaches to accelerating transformers. Two of them optimize the attention mechanism and the third optimizes other parts of the architecture.
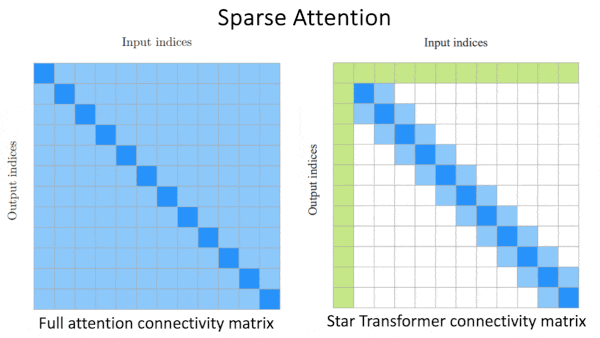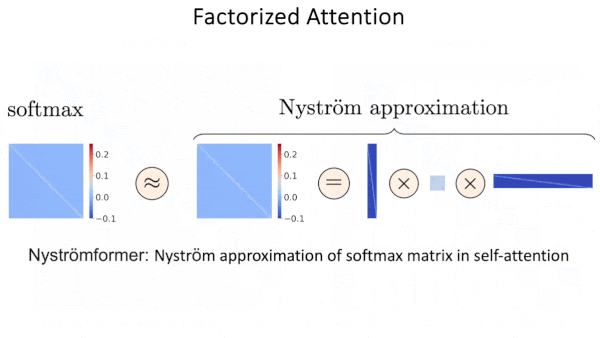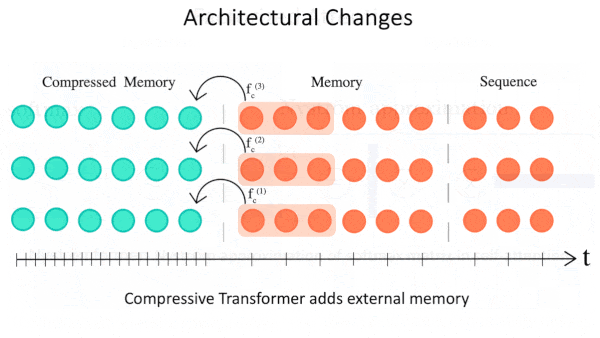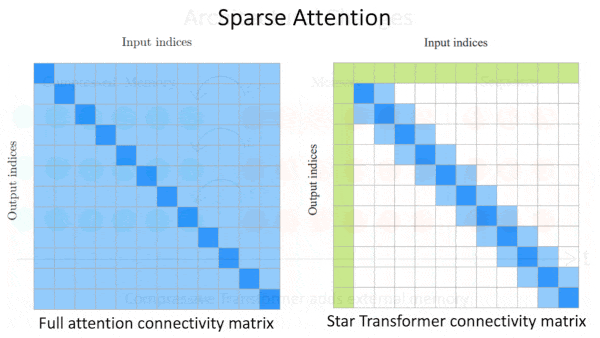
- Sparse attention. These approaches simplify the attention calculation by using a subset of weights and setting the rest to 0. They mix and match three general patterns in which the position of a given token in a sequence determines how it attends to other tokens: (i) a token attends to all other tokens, (ii) a token attends only to directly neighboring tokens, or (iii) a token attends to a random selection of tokens. For instance, in Star Transformer, the first token attends to all other tokens and the other tokens attend only to neighbors. Calculating attention with sparse matrices is faster than usual thanks to fast sparse matrix multiplication algorithms. However, because it processes only a subset of the original attention weights, this approach degrades performance slightly. Further, because sparse attention patterns are handcrafted, they may not work well with all data and tasks.
- Factorized attention. Approaches in this category modify attention calculations by approximating individual matrices as the product of two (or more) smaller matrices. This technique enables Linformer to cut memory requirements by a factor of 10 compared to the original transformer. Factorized attention methods outperform sparse attention in some tasks, such as determining whether two dots in an image are connected by a path that consists of dashes. However, they’re less effective in other areas, such as classifying images and compressing long sequences for retrieval.
- Architectural changes. These approaches retain the original attention mechanism while altering other aspects of transformer architecture. One example is adding an external memory. With the original transformer, if an input sequence is too long, the model breaks it into smaller parts and processes them independently. Given a long document, by the time it reaches the end, it doesn’t have a memory of what happened at the beginning. Transformer-XL and Compressive Transformer store embeddings of earlier parts of the input and use them to embed the current part. Compared to the original transformer of the same size, Transformer-XL was able to improve its performance based on training examples that were 4.5 times longer.
Yes, but: It’s difficult to compare the results achieved by these variations due to differences in model size and hyperparameters (which affect performance) and hardware used (which affects speed). Further, some transformer variations utilize multiple modifications, making it hard to isolate the benefit of any particular one.
Why it matters: These variations can help machine learning engineers manage compute requirements while taking advantage of state-of-the-art approaches.
We’re thinking: The authors of Long Range Arena built a dashboard that reports performance of various transformers depending on the task. We welcome further efforts to help developers understand the tradeoffs involved in different variations.