
Dear friends,
It is only rarely that, after reading a research paper, I feel like giving the authors a standing ovation. But I felt that way after finishing Direct Preference Optimization (DPO) by Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Chris Manning, and Chelsea Finn. (I didn't actually stand up and clap, since I was in a crowded coffee shop when I read it and would have gotten weird looks! 😀)
This beautiful work proposes a much simpler alternative to RLHF (reinforcement learning from human feedback) for aligning language models to human preferences. Further, people often ask if universities — which don't have the massive compute resources of big tech — can still do cutting-edge research on large language models (LLMs). The answer, to me, is obviously yes! This article is a beautiful example of algorithmic and mathematical insight arrived at by an academic group thinking deeply.
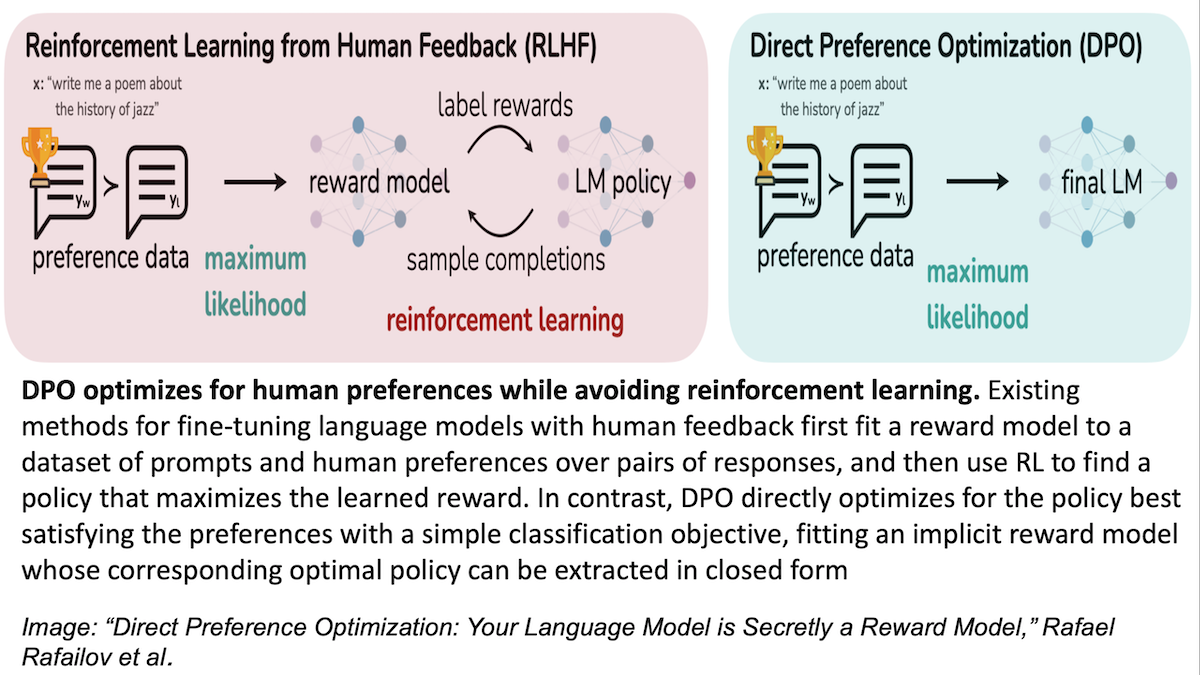
RLHF became a key algorithm for LLM training thanks to the InstructGPT paper, which adapted the technique to that purpose. A typical implementation of the algorithm works as follows:
- Get humans to compare pairs of LLM outputs, generated in response to the same prompt, to specify which one they prefer. For example, humans typically prefer the more helpful, less toxic output.
- Use the human preferences to learn a reward function. The reward function, typically represented using a transformer network, is trained to give a higher reward (or score) to the outputs that the humans preferred.
- Finally, using the learned reward, run a reinforcement learning algorithm to tune the LLM to (i) maximize the reward of the answers generated, while (ii) not letting the LLM change too much (as a form of regularization).
This is a relatively complex algorithm. It needs to separately represent a reward function and an LLM. Also, the final, reinforcement learning step is well known to be finicky to the choice of hyperparameters.
DPO dramatically simplifies the whole thing. Rather than needing separate transformer networks to represent a reward function and an LLM, the authors show how, given an LLM, you can figure out the reward function (plus regularization term) that that LLM is best at maximizing. This collapses the two transformer networks into one. Thus, you now need to train only the LLM and no longer have to deal with a separately trained reward function. The DPO algorithm trains the LLM directly, so as to make the reward function (which is implicitly defined by the LLM) consistent with the human preferences. Further, the authors show that DPO is better at achieving RLHF's optimization objective (that is, (i) and (ii) above) than most implementations of RLHF itself.
RLHF is a key building block of the most advanced LLMs. It’s fantastic that these Stanford authors — through clever thinking and mathematical insight — seem to have replaced it with something simpler and more elegant. While it's easy to get excited about a piece of research before it has stood the test of time, I am cautiously optimistic that DPO will have a huge impact on LLMs and beyond in the next few years. Indeed, it is already making its way into some top-performing models, such as Mistral’s Mixtral.
That we can replace such fundamental building blocks of LLMs is a sign that the field is still new and much innovation lies ahead. Also, while it's always nice to have massive numbers of NVIDIA H100 or AMD MI300X GPUs, this work is another illustration — out of many, I want to emphasize — that deep thinking with only modest computational resources can carry you far.
A few weeks ago at NeurIPS (where DPO was published), I found it remarkable both (i) how much highly innovative research there is coming out of academic labs, independent labs, and companies small and large, and (ii) how much our media landscape skews attention toward work published by the big tech companies. I suspect that if DPO had been published by one of the big LLM companies, it would have made a huge PR splash and been announced as a massive breakthrough. Let us all, as builders of AI systems, make sure we recognize the breakthroughs wherever they occur.
Keep learning!
Andrew
P.S. We just launched our first short course that uses JavaScript! In “Build LLM Apps with LangChain.js,” taught by LangChain’s founding engineer Jacob Lee, you’ll learn many steps that are common in AI development, including how to use (i) data loaders to pull data from common sources such as PDFs, websites, and databases; (ii) different models to write applications that are not vendor-specific; and (iii) parsers that extract and format the output for your downstream code to process. You’ll also use the LangChain Expression Language (LCEL), which makes it easy to compose chains of modules to perform complex tasks. Putting it all together, you’ll build a conversational question-answering LLM application capable of using external data as context. Please sign up here!