
An architectural innovation improves upon transformers — up to 2 billion parameters, at least.
What’s new: Albert Gu at Carnegie Mellon University and Tri Dao at Princeton University developed the Mamba architecture, a refinement of the earlier state space sequence architecture. A relatively small Mamba produced tokens five times faster and achieved better accuracy than a vanilla transformer of similar size while processing input up to a million tokens long.
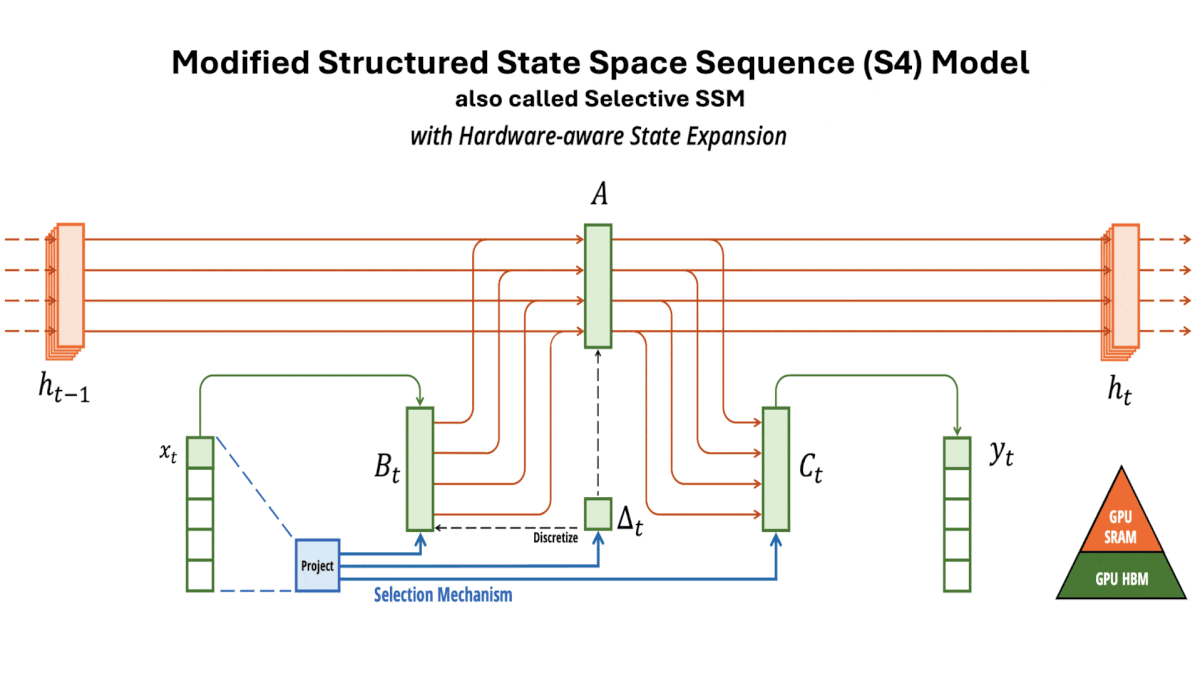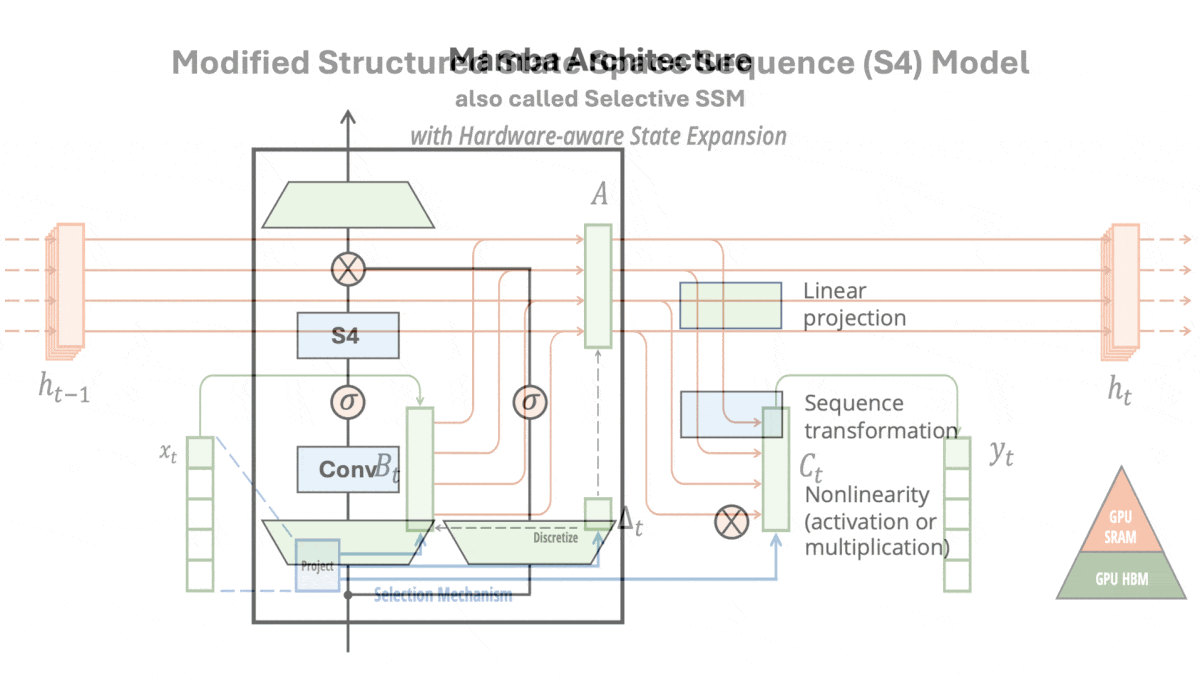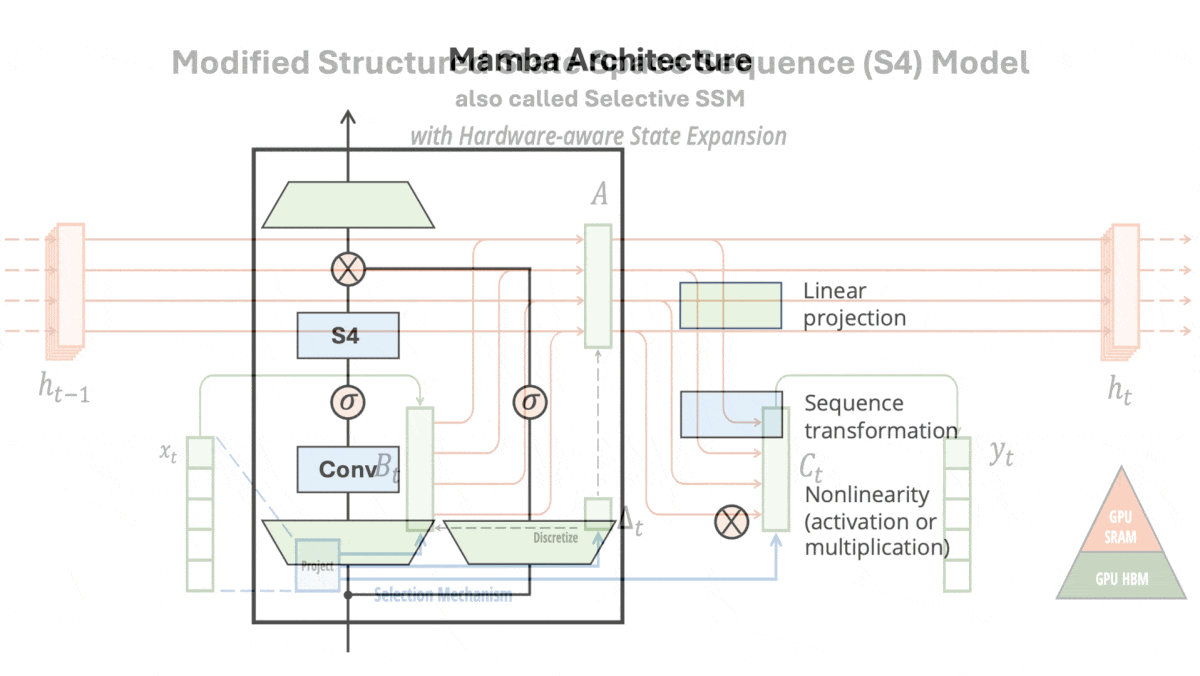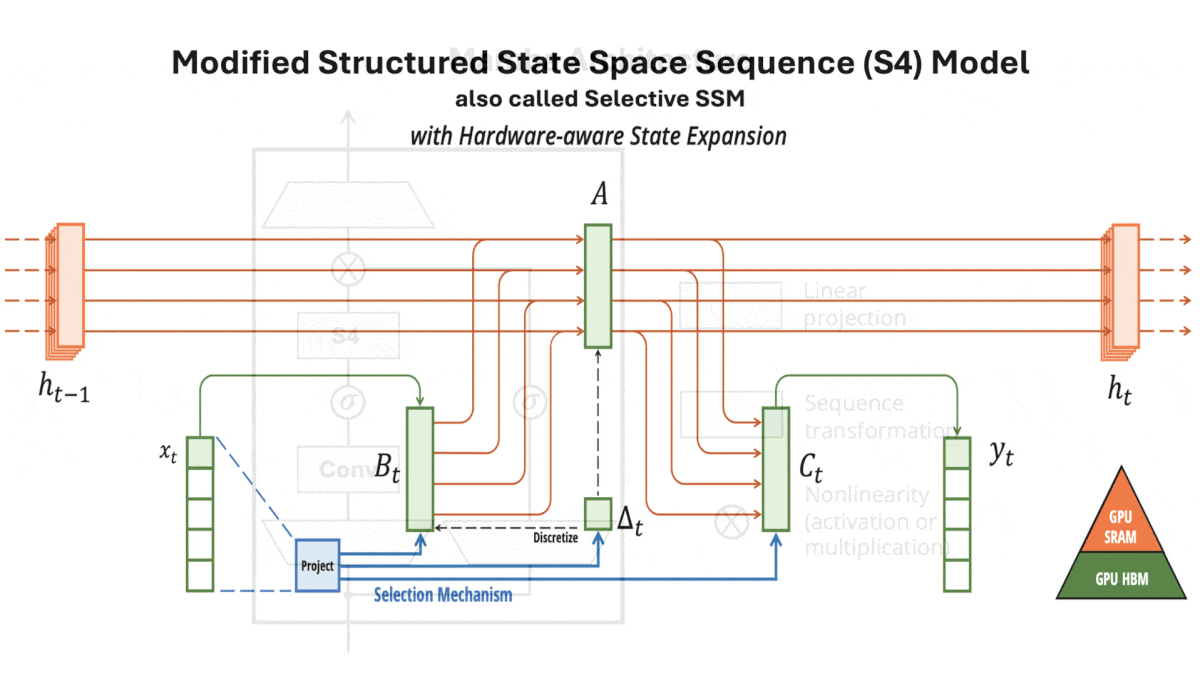
Structured State Space Sequence (S4) basics: S4s, also known as structured SSMs, can be functionally similar to recurrent neural networks (RNNs): They can accept one token at time and produce a linear combination of the current token and an embedding that represents all previous tokens. Unlike RNNs and their extensions including LSTMs — but like transformers — they can also perform an equivalent computation in parallel during training. In addition, they are more computationally efficient than transformers. An S4’s computation and memory requirements rise linearly with input size, while a vanilla transformer’s rise quadratically — a heavy burden with long input sequences.
Key insight: S4s are more efficient than transformers but, while a transformer’s input length is limited only by processing and memory, an S4’s input length is limited by how well its hidden state can represent previously input tokens as new tokens arrive. A gating mechanism that lets the model process the most important parts of an input and ignore the rest can enable it to process longer inputs. One viable gate: Typically S4s apply the same mathematical function to all input tokens, whose parameters consist of four learned matrices. Changing the matrices for each input enables the model to learn which tokens or parts of tokens are least important and can be ignored (set to zero). This condenses the input, enabling the modified S4 to process very long input sequences.
How it works: Mamba is made up of blocks, each of which includes a modified S4 (which the authors call a selective SSM). The authors pretrained different instances on a variety of tasks including generating tokens from The Pile (a collection of text from the web) and predicting DNA base pairs in HG38 (a single human genome) in sequences up to 1 million tokens long.
- In each block, the authors replaced three of the S4’s four fixed matrices with learned linear functions of the input. That is, they replaced each of three learned matrices with a learned matrix multiplied by the input. (The authors hypothesized that modifying the fourth matrix would not help, so they didn’t change it.)
- The following layer multiplied the model’s output with a linear projection of the block’s input. This acted as a gate to filter out irrelevant parts of the embedding.
Results: Mamba achieved better speed and accuracy than transformers of similar size, including tasks that involved inputs of 1 million tokens.
- Running on an Nvidia A100 GPU with 80GB, a Mamba of 1.4 billion parameters produced 1,446 tokens per second, while a transformer of 1.3 billion parameters produced 344 tokens per second.
- In sizes from 130 million parameters to 2.8 billion parameters, Mamba outperformed the transformer Pythia and the S4 H3 on many tasks. It was better at predicting the next word of The Pile, and it was better at question-answering tasks such as WinoGrande and HellaSwag. For instance, on WinoGrande, using models of roughly 2.8 billion parameters, Mamba achieved 63.5 percent accuracy, Pythia 59.7 percent accuracy, and H3 61.4 percent accuracy.
- After fine-tuning on Great Apes DNA Classification (classifying DNA segments up to 1 million tokens long as belonging to one of five species of great ape), using models of 1.4 million parameters, Mamba achieved 70 percent accuracy, while Hyena DNA achieved 55 percent accuracy.
Yes, but: The authors tested model sizes much smaller than current state-of-the-art large language models.
Why it matters: Google’s transformer-based Gemini 1.5 Pro offers context lengths up to 1 million tokens, but methods for building such models aren’t yet widely known. Mamba provides an alternative architecture that can accommodate very long input sequences while processing them more efficiently. Whether it delivers compelling benefits over large transformers and variations that provide higher efficiency and larger context is a question for further research
We're thinking: Research on Mamba is gaining momentum. Other teams are probing the architecture in projects like Motion Mamba, Vision Mamba, MoE-Mamba, MambaByte, and Jamba.