
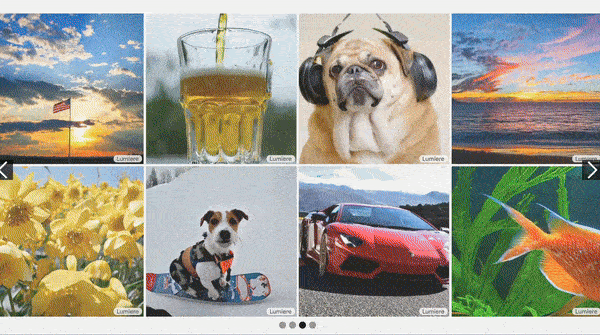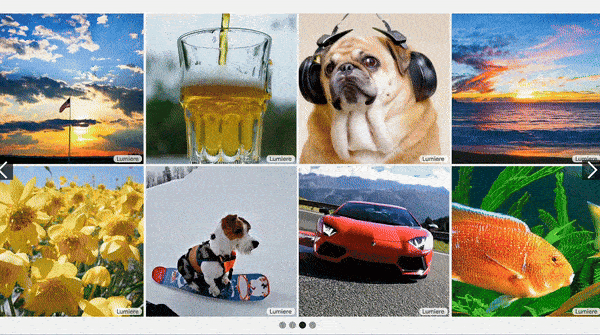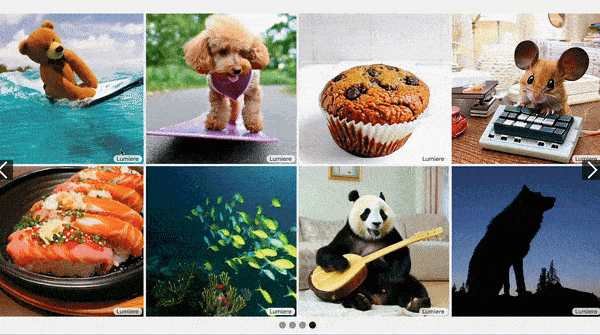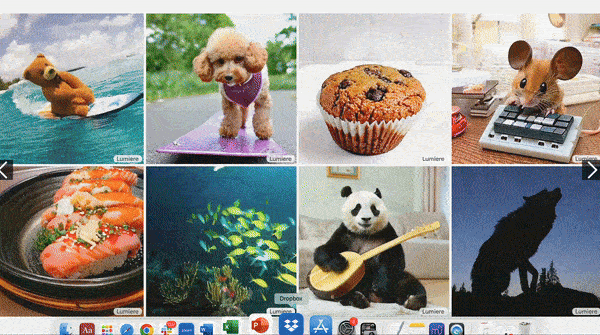
Text-to-video has struggled to produce consistent motions like walking and rotation. A new approach achieves more realistic motion.
What’s new: Omer Bar-Tal, Hila Chefer, Omer Tov, and colleagues at Google, Weizmann Institute, Tel-Aviv University, and Technion built Lumiere, a system that simplifies the usual process of generating video with improved results. You can see examples of its output here.
Key insight: Most text-to-video generators economize on memory use through a staged process: One model generates a few frames per second, another model generates additional frames between the initial ones, and a third generates a higher resolution version of every frame. Generating in-between frames can make repetitive motions inconsistent. To avoid these inconsistencies, the authors generated all frames at the same time. To bring down memory requirements, the video generator reduced the size of the video embedding before intensive processing and then restored their original size.
How it works: Lumiere borrows two components from previous work. It uses a frozen, pretrained text-to-image diffusion model (in this case, Imagen, with additional convolutional and attention layers) to generate low-resolution video frames from a text description. It uses a super-resolution model (unspecified in this case) to boost the frames’ resolution. The authors trained the layers added to Imagen on an unspecified dataset of 30 million videos (16 frames per second, 128x128 pixels per frame) and their captions.
- Given a 5-second video with added noise and its text caption, the layers added to Imagen learned to remove the noise. Following earlier work, the model saved memory by shrinking video embeddings spatially. Specifically, additional convolutional layers progressively shrank the input embedding from size (Time, Height, Width, Depth) to size (Time, Height/2, Width/2, Depth). This effectively shrank the parts of the embedding that correspond to individual frames before subjecting the entire embedding to computationally intensive attention layers. Afterward, further convolutional layers enlarged the embeddings to match the input size.
- In addition to shrinking and enlarging the video embedding spatially, the added layers learned to shrink and enlarge it temporally; that is, from size (Time, Height, Width, Depth) to size (Time/2, Height/2, Width/2, Depth). This further economized on memory usage.
- To accommodate the super-resolution model, Lumiere broke up Imagen’s 5-second video output into overlapping clips. The super-resolution model increased their resolution to 1024×1024.
- To avoid temporal artifacts from this process, Lumiere employed MultiDiffusion, which learned a weighted sum over the overlapping portions of the clips.
Results: Given one video produced by Lumiere and another produced by a competitor (AnimateDiff, Gen2, Imagen Video, Pika, or ZeroScope), judges compared video quality and alignment with the text prompt used to generate a video. For each competitor, they evaluated 400 videos for each of 113 prompts. Comparing video quality, Lumiere beat the best competitor, Gen2, 61 percent to 39 percent. Comparing alignment with the prompt, Lumiere beat the best competitor, ImagenVideo, 55 percent to 45 percent.
Why it matters: Earlier video generators produced output with limited motion or motion with noticeable issues (for example, a character’s body shape might change in unexpected ways). By producing all video frames at once, Lumiere generates images of motion without such issues.
We’re thinking: Lumiere's approach hints at both the challenge of generating video and the pace of development. Many further refinements are needed to make such systems as useful as, say, ChatGPT, but recent progress is impressive.