
Dear friends,
With the rise of software engineering over several decades, many principles of how to build traditional software products and businesses are clear. But the principles of how to build AI products and businesses are still developing. I’ve found that there are significant differences, and I’ll explore some of them in this and future letters.
That AI enables new categories of products and businesses is a familiar theme. However, using this new technology — whether in a startup going from 0 to 1 or a large company incubating a new product — brings special challenges:
Unclear technical feasibility. It’s relatively well understood what a traditional mobile app or web app can do. If you can draw a reasonable wireframe, you can probably build it. But until you’ve examined the data and run some experiments, it’s hard to know how accurate an AI system can be in a given application. For example, many technologists overestimated how easy it would be to build an acceptably safe self-driving car. Generally, AI startups bring higher technical risk than traditional software startups because it’s harder to validate in advance if a given technology proposal is feasible.
Complex product specification. The specification for a traditional web app might come in the form of a wireframe, but you can’t draw a wireframe to indicate how safe a self-driving car must be. It’s extremely complex to specify operating conditions (sometimes also called the operational design domain) and acceptable error rates under various conditions. Similarly, it can be hard to write a spec for a medical diagnosis tool, depending on how acceptable different types of errors are (since not all errors are equally severe). Further, product specs often evolve as the team discovers what is and isn’t technically feasible.
Need for data. To develop a traditional software product, you might (a) interview users to make sure they want what you aim to build, (b) show them a wireframe to make sure your design meets their needs, and (c) dive into writing the code. If you’re building an AI product, you need to write code, but you also need access to data to train and test the system. This may not be a big challenge. For a consumer product, you may be able to start with a small amount of data from an initial cohort of users. But for a product aimed at business customers — say, AI to optimize shipping or help a hospital manage its medical records — how can you get access to shipping data or medical records? To work around this chicken-and-egg problem, some AI startups start by doing consulting or NRE (non-recurring engineering) work. Those activities are hard to scale, but they afford access to data that can shape a scalable product.
Additional maintenance cost. For traditional software, the boundary conditions — the range of valid inputs d — are usually easy to specify. Indeed, traditional software often checks the input to make sure, for example, it’s getting an email address in a field dedicated to that input. But for AI systems, the boundary conditions are less clear. If you have trained a system to process medical records, and the input distribution gradually changes (data drift/concept drift), how can you tell when it has shifted so much that the system requires maintenance?
Because of these differences between traditional software and AI, the best practices for building AI businesses are different. I’ll dive deeper into these differences in future letters. Meanwhile, please ask your business friends to subscribe to The Batch if they want to understand how to build an AI business!
Keep learning!
Andrew
News

Where There’s Smoke, There’s AI
An automated early warning system is alerting firefighters to emerging blazes.
What’s new: South Korean company Alchera trained a computer vision system to monitor more than 800 fire-spotting cameras in Sonoma County, California, the local news channel ABC7 reported.
How it works: Alchera’s Artificial Intelligence Image Recognition (AIIR) spots smoke plumes caught on camera by a portion of California’s Alert Wildfire network. A convolutional neural network flags video frames in which it recognizes smoke plumes, and an LSTM analyzes the time series to confirm the classification. If smoke is confirmed, an alarm alerts an operator at a central monitoring station.
- The system came online last month. In its first week, it logged over 60 alerts with a false-positive rate of 0.08 percent. It detected one blaze 10 minutes before the first human spotter dialed 9-1-1.
- If the system proves successful, officials aim to expand its purview to other Alert Wildfire cameras installed throughout the state by government agencies, power companies, and others.
Behind the news: Last year, California firefighters used AI to convert aerial imagery into maps to monitor fires that might endanger Yosemite National Park. Wildfires threaten as many as 4.5 million U.S. homes and have wrought havoc in Australia, Pakistan, Russia, and other countries in recent years.
Why it matters: While other wildfire-detection systems rely on sporadic aerial or satellite photos, this one watches continuously via cameras at ground level, enabling it to recognize hazards early and at lower cost.
We’re thinking: This is one hot application!
Synthetic Videos on the Double
Using a neural network to generate realistic videos takes a lot of computation. New work performs the task efficiently enough to run on a beefy personal computer.
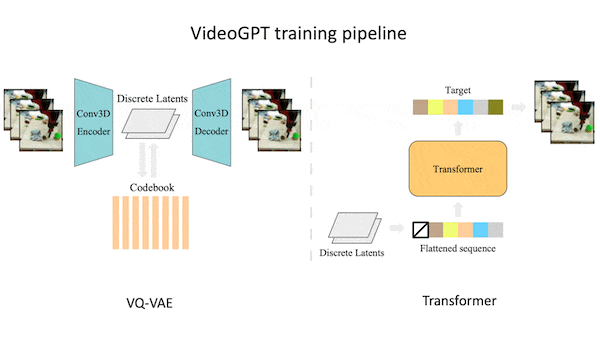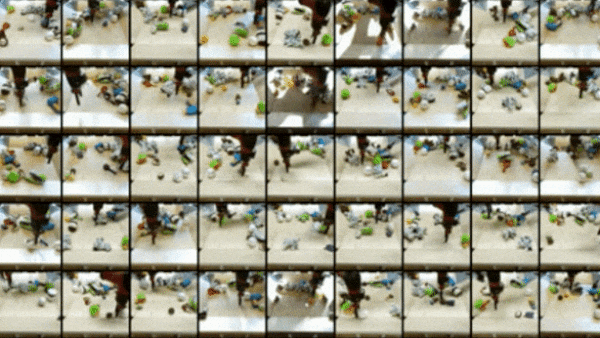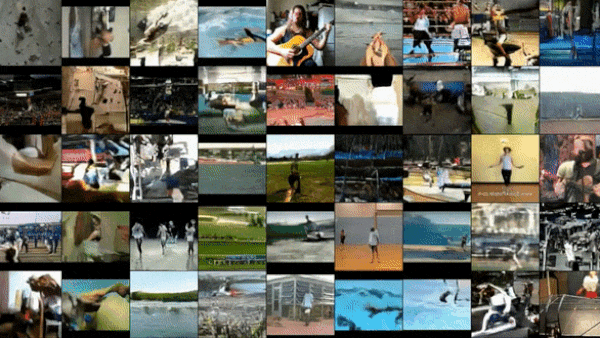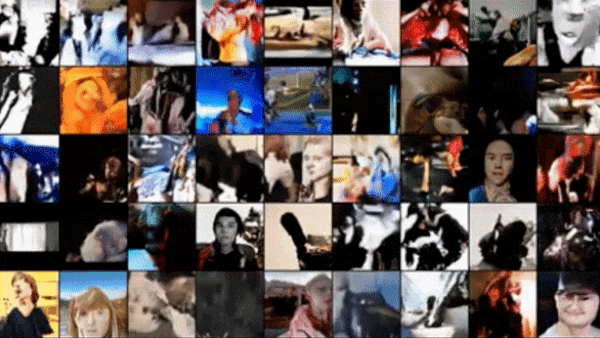
What’s new: Wilson Yan, Yunzhi Zhang, and colleagues at UC Berkeley developed VideoGPT, a system that combines image generation with image compression to produce novel videos.
Key insight: It takes less computation to learn from compressed image representations than full-fledged image representations.
How it works: VideoGPT comprises a VQ-VAE (a 3D convolutional neural network that consists of an encoder, an embedding, and a decoder) and an image generator based on iGPT. The authors trained the models sequentially on BAIR Robot Pushing (clips of a robot arm manipulating various objects) and other datasets.
- VQ-VAE’s encoder learned to compress representations of the input video (16x64x64) into smaller representations (8x32x32) where each value is a vector. In the process, it learned an embedding whose vectors encoded information across multiple frames.
- VQ-VAE replaced each vector in the smaller representations with the closest value in the learned embedding, and the decoder learned to reproduce the original frames from these modified representations.
- After training VQ-VAE, the authors used the encoder to compress a video from the training set. They trained iGPT, given a flattened 1D sequence of representations, to generate the next representation by choosing vectors from the learned embedding.
- To generate video, VideoGPT passed a random representation to iGPT, concatenated its output to the input, passed the result back to iGPT, and so on for a fixed number of iterations. VQ-VAE’s decoder converted the concatenated representations into a video.
Results: The authors evaluated VideoGPT’s performance using Frechet Video Distance (FVD), a measure of the distance between representations of generated output and training examples (lower is better). The system achieved 103.3 FVD after training on eight GPUs. The state-of-the-art Video Transformer achieved 94 FVD after training on 128 TPUs (roughly equivalent to several hundred GPUs).
Why it matters: Using VQ-VAE to compress and decompress video is not new, but this work shows how it can be used to cut the computation budget for computer vision tasks.
We’re thinking: Setting aside video generation, better video compression is potentially transformative given that most internet traffic is video. The compressed representations in this work, which are tuned to a specific, sometimes narrow training set, may be well suited to imagery from security or baby cams.
A MESSAGE FROM DEEPLEARNING.AI

You’re invited! On June 30, 2021, we’ll celebrate the launch of Course 3 in the Machine Learning Engineering for Production (MLOps) Specialization featuring our instructors and leaders in MLOps. Join us for this live event!

Machine Learning for Human Learners
AI is guiding admissions, grading homework, and even teaching classes on college campuses.
What’s new: In a bid to cut costs, many schools are adopting chatbots, personality-assessment tools, and tutoring systems according to The Hechinger Report, an online publication that covers education. Critics worry that these systems may cause unseen harm.
What they found: AI is used to help manage students at nearly every step in gaining higher education.
- Baylor University, Boston University, and others use personality-assessment software from Kira Talent to score applicants on traits such as openness, motivation, and “neuroticism.” Human administrators make the final call on who gets accepted.
- After accepting a new crop of candidates, Georgia State University uses a chatbot to send them encouraging messages. The system has increased the percentage who pay a deposit and enroll.
- Australia’s Deakin University developed Genie, a chatbot that monitors student behaviors and locations. If it determines that a would-be scholar is dawdling in the dining hall, for instance, it will send a message to get back on-task.
- Southern New Hampshire University is developing systems to grade homework and class participation. It monitors speech, body language, and how rapidly students respond to online lessons.
- ElevateU produces instructional programs called “AI textbooks” that tailor the learning experience based on student preferences, actions, and responses.
Yes, but: Some observers say these systems may be giving inaccurate grades, contributing to bias in admissions, or causing other types of harm.
- An AI grading system tested by researchers at MIT gave high marks to gibberish essays studded with key phrases that contributed to a good score.
- University of Texas at Austin abandoned a system that evaluated graduate candidates after it was found to favor people whose applications resembled those of past students.
- Last year, the British government abandoned high-school rankings determined by an algorithm when the system gave 40 percent of students lower grades than their teachers would have assigned.
Why it matters: The pandemic exacerbated an ongoing decline in U.S. university enrollment, which has left colleges scrambling. Automated systems that are carefully designed and sensibly deployed could help streamline processes, reduce costs, and increase access.
We’re thinking: AI has its place on campus. For instance, chatbots can help students figure out where their classes meet. The technology doesn’t yet offer a substitute for good human judgement when it comes to sensitive tasks like assessing performance, but if it can show consistently fair and accurate judgement, it could help reduce the noise that currently afflicts human grading.
Sorting Shattered Traditions
Computer vision is probing the history of ancient pottery.
What’s new: Researchers at Northern Arizona University developed a machine learning model that identifies different styles of Native American painting on ceramic fragments and sorts the shards by historical period.
How it works: The researchers started with an ensemble of VGG16 and ResNet50 convolutional neural networks pretrained on ImageNet. They fine-tuned the ensemble to predict pottery fragments’ historical period.
- The researchers collected 3064 photographs of pottery fragments from the southwestern U.S. Four experts labeled each photo as belonging to one of nine periods between 825 AD and 1300 AD. A majority of the experts had to agree on the type of pottery in each image for it to be included in the fine-tuning dataset, which contained 2,407 images.
- To make their training data more robust, the researchers randomly rotated, shrunk, or enlarged every photo prior to each training cycle.
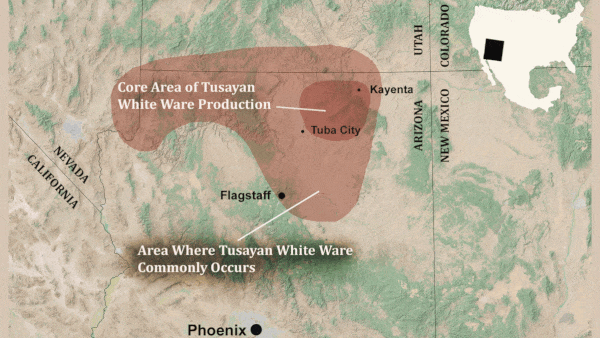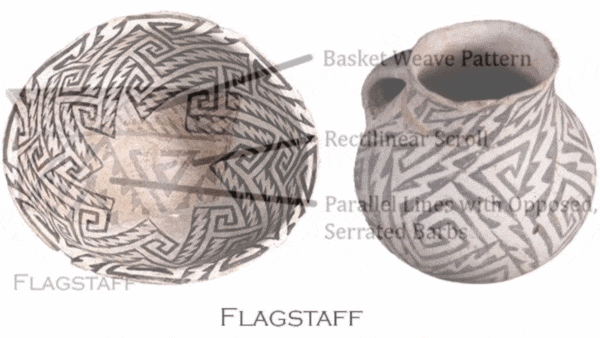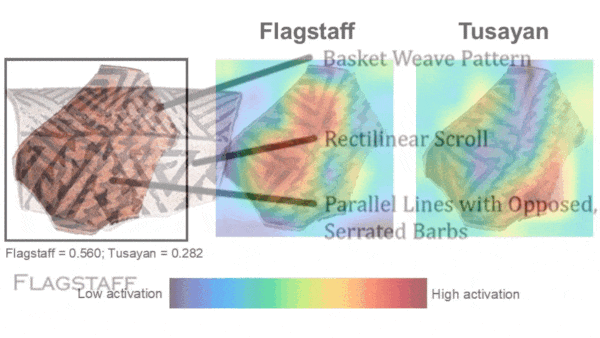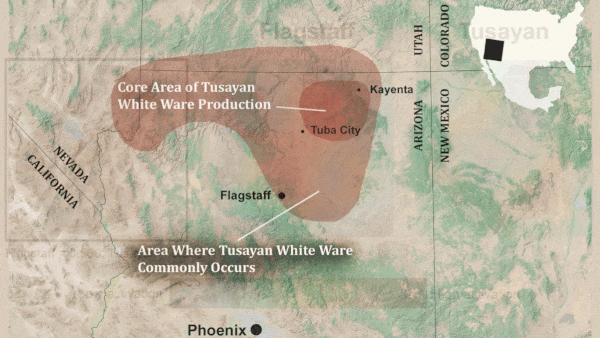
- Heat maps generated using Grad-CAM highlighted the design features that were most influential in the model’s decisions.
Results: In tests, the model classified tens of thousands of unlabeled fragments. It scored higher than two experts and roughly equal to two others.
Behind the news: AI is helping archaeologists discover long-lost civilizations and make sense of clues they had already uncovered.
- Researchers found evidence of ancient settlements by training a model to interpret lidar readings taken during flights over Madagascar and the U.S.
- Using a similar method, archaeologists developed a network that identified underground tombs in aerial photography.
- A model that reads cuneiform is helping scholars translate ancient Persian tablets.
Why it matters: For human archaeologists, learning to recognize the patterns on ancient pottery takes years of practice, and they often disagree on a given fragment’s provenance. Machine learning could sift through heaps of pottery shards far more quickly, allowing the humans to focus on interpreting the results.
We’re thinking: Even when experts correctly identify a fragment, they can’t always explain what features led them to their conclusion. Heat maps from machine learning models could help teach the next generation of archaeologists how to read the past.
A MESSAGE FROM DEEPLEARNING.AI

In “Analyze Datasets and Train ML Models Using AutoML,” Course 1 in our new Practical Data Science Specialization, you’ll learn foundational concepts for exploratory data analysis (EDA), automated machine learning (AutoML), and text classification algorithms. Enroll now