
Dear friends,
AI continues to create numerous exciting career opportunities, and I know that many of you aim to develop a career in the field. While taking online courses in technical topics is an important step, being an AI professional requires more than technical skills. Lately I’ve been thinking about how to do more to support all of you who are looking to build a career in AI.
Considering individuals at a variety of stages in their careers, what are some of the keys to success?
- Technical skills. When learning a new skill, taking an online course or reading a textbook — in which an expert presents important concepts into an easy-to-digest format — is one of the most efficient paths forward.
- Practical experience. After gaining a skill, it’s necessary to practice it — and learn tricks of the trade — by applying that skill to significant projects. Machine learning models that perform well in the lab can run into trouble in the real world. Practical project experience remains an important component in overcoming such problems.
- Project selection. Choosing projects to work on is one of the hardest skills in AI. We can only work on so many projects at a time, and scoping ones that are both feasible and valuable — so they have a good chance of achieving meaningful success — is an important step that has to be done repeatedly in the course of a career.
- Teamwork. When we tackle large projects, we succeed better by working in teams than individually. The ability to collaborate with, influence, and be influenced by others is critical. This includes both interpersonal and communication skills. (I used to be a pretty bad communicator, by the way.)
 |
- Networking. I hate networking! As an introvert, having to go to a party to smile and shake as many hands as possible is an activity that borders on horrific. I’d much rather stay home and read a book. Nonetheless, I’m fortunate to have found many genuine friends in AI; people I would gladly go to bat for and who I count on as well. No person is an island, and having a strong professional network can help propel you forward in the moments when you need help or advice.
- Job search. Of all the steps in building a career, this one tends to receive the most attention. Unfortunately, I’ve found a lot of bad advice about this on the internet. (For example, many articles seem to urge taking an adversarial attitude toward potential employers, which I don’t think is helpful). Although it may seem like finding a job is the ultimate goal, it’s just one small step in the long journey of a career.
- Personal discipline. Few people will know if you spend your weekends learning or binge watching TV (unless you tell them on social media!), but they will notice the difference over time. Many successful people develop good habits in eating, exercise, sleep, personal relationships, work, learning, and self-care. Such habits help them move forward while staying healthy.
- Altruism. I find that individuals who aim to lift others during every step of their own journey often achieve better outcomes for themselves. How can we help others even as we build an exciting career for ourselves?
Each of these items is a complex subject worthy of an entire book. I will continue to think on how we can work collectively to support everyone’s career goals. Meanwhile, I would like to hear your thoughts as well. What am I missing? What can I or my teams do to support you in your career?
Keep learning!
Andrew
News
 |
Stopping Guns at the Gate
A Major League Baseball stadium will be using computer vision to detect weapons as fans enter.
What’s new: A system called Hexwave will look for firearms, knives, and explosives carried by baseball fans who visit Camden Yards, home field of the Baltimore Orioles, The Baltimore Sun reported. The system will be tested during certain games in the coming baseball season.
How it works: Developed by MIT Lincoln Lab and licensed to Liberty Defense Holdings, a security firm, Hexwave scans passing bodies and alerts guards to potential threats even if they’re concealed by clothing or luggage. It can scan 1,000 people per hour.
- The system scans visitors with microwaves, which penetrate a variety of materials, as they walk past an antenna array. It constructs a 3D image of the body in real time.
- A machine learning model interprets the imagery. In addition to weapons, it recognizes benign objects like keys and coins so visitors don’t have to empty pockets and bags. If it recognizes a potential threat, the system alerts the security guard and outlines the threat on a display.
- Liberty Defense Holdings plans to start selling Hexwave this year. The company previously tested the system at sporting arenas in Munich and Vancouver and a U.S. shopping mall chain.
Behind the news: A small but growing number of public venues implement AI solutions to enhance security and cut wait times.
- A system from Omnilert was trained to recognize firearms in surveillance imagery using simulations from video game software, scenes from action movies, and videos of employees holding toy or real guns. A number of universities, retailers, and other workplaces use it.
- Several U.S. airports use machine learning models to confirm traveler’s identities and reduce wait times as they board international flights and cross borders.
Why it matters: Traditional security checkpoints can be slow, intrusive, and ineffective. AI stands to make them not only more effective but also much more efficient.
We’re thinking: Neither Liberty Defense Holdings nor MIT Lincoln Lab provides independent validation of the system’s performance. In an era when the AI community is grappling with the technology’s potential for harm, it’s incumbent on companies that offer systems that evaluate individual behavior to demonstrate their products’ accuracy and fairness before putting them into widespread use.
 |
AI Versus the Garbage Heap
Amazon reported long-term success using machine learning to shrink its environmental footprint.
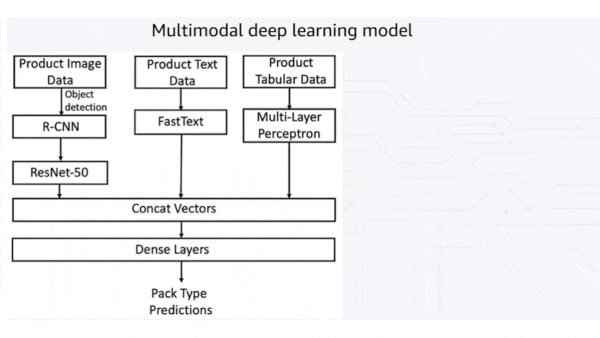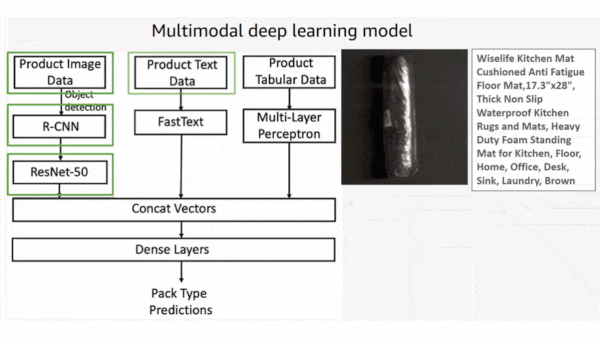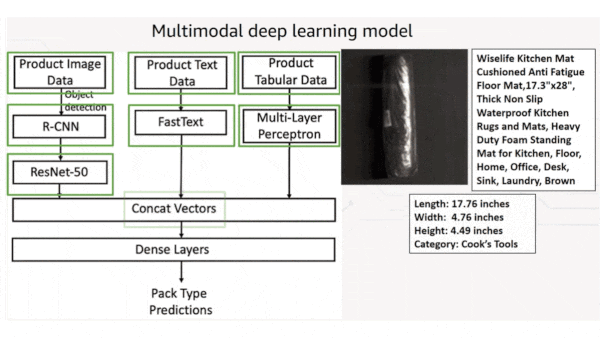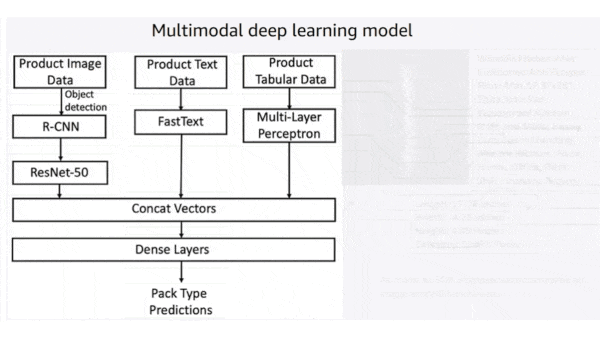
What’s new: The online retailer developed a system that fuses product descriptions, images, and structured data to decide how an item should be packed for shipping. It evolved over six years, ultimately helping Amazon cut packaging waste equivalent to over 2 billion shipping boxes.
How it works: The system initially made packaging decisions based on text descriptions. Last year, the company integrated computer vision and tabular data analysis.
- A Faster R-CNN crops product images. Then a ResNet50 pretrained on ImageNet generates separate representations of images of the product and the manufacturer’s default packaging. For instance, the manufacturer of a football, which ordinarily would warrant a box, might supply it deflated, in which case a more environmentally friendly bag would be a viable choice.
- A FastText model trained on product descriptions analyzes text. For instance, words like “fragile,” “glass,” or “ceramic” might indicate a delicate object that’s best shipped in a box. Words like “multipack” and “bag” might indicate a product that’s already covered in protective packaging, which can be put in a padded mailer to save material.
- A vanilla neural network generates representations of structured data such as the number of items to be shipped and their categories, to help decide whether items can be packaged together, or if not, how many packages are necessary.
- A multimodal fusion architecture combines the representations to render a packaging decision.
Why it matters: Amazon has shipped some 465 million pounds of plastic waste by one estimate. More broadly, 131.2 billion consumer parcels were shipped worldwide in 2020, according to postage technology firm Pitney Bowes — a figure expected to double within the next five years. AI that cuts the waste that attends all this shipping and receiving might help ease ecommerce’s burden on the planet.
We’re thinking: Multimodal AI is on the upswing, and it’s great to see this approach contributing to a more sustainable world. That said, 2 billion boxes is a drop in the 131-billion-parcel ocean. We hope Amazon — and other retailers — will continue to look for innovative ways to diminish the mountain of packaging garbage.
A MESSAGE FROM DEEPLEARNING.AI
 |
We’re thrilled to launch the second cohort of our Curriculum Architect Program! This free program is designed to help aspiring and experienced educators hone their curriculum development skills, especially for technical online courses. Learn more and submit your application.
 |
Predicting Regime Change
Can AI spot countries at risk of a sudden change in leadership?
What’s new: Researchers at the University of Central Florida are working with a system called CoupCast to estimate the likelihood that an individual country will undergo a coup d’état, The Washington Post reported.
How it works: CoupCast predicts the probability that a coup will overthrow each of the world’s national leaders in each month.
- The team gathered a proprietary training dataset by deducing likely drivers of coup attempts from academic research on coups dating back to 1920. In addition, it collected data detailing contemporaneous economic conditions such as gross domestic products, social conditions such as infant mortality, political conditions such as election schedules and regime longevity, and leader profiles such as age and military background.
- The team trained two architectures, a random forest and an ensemble of regression models, to predict coup probabilities in logarithmic space, allowing a finer assessment of risk where coups are rare. They trained the regression models in an autoregressive fashion: First they trained a model on data between 1950 and 1974 to predict coup risks for 1975. They added the 1975 predictions to the dataset and retrained the model to predict risks for 1976, and so on to the present.
- The two models are similarly good at predicting coups, but they're much more accurate when combined. The team combines their outputs using a generalized additive model.
Results: In 2021, the system predicted upheavals in Chad and Mali.
Behind the news: CoupCast is one of several efforts to use machine learning to study political tensions.
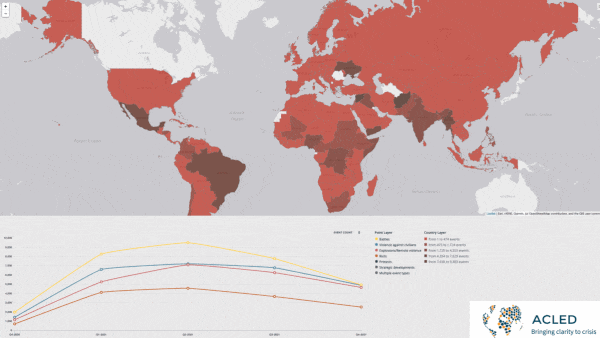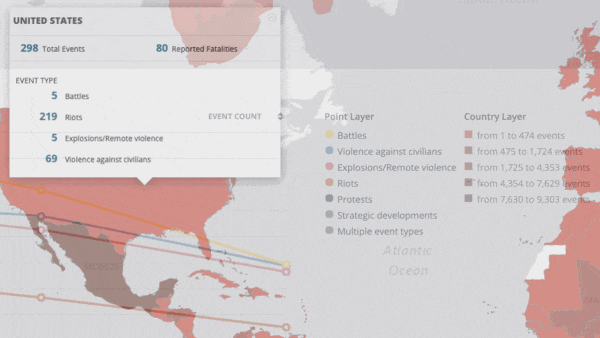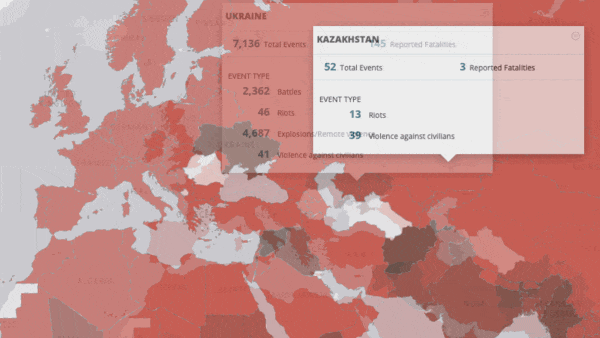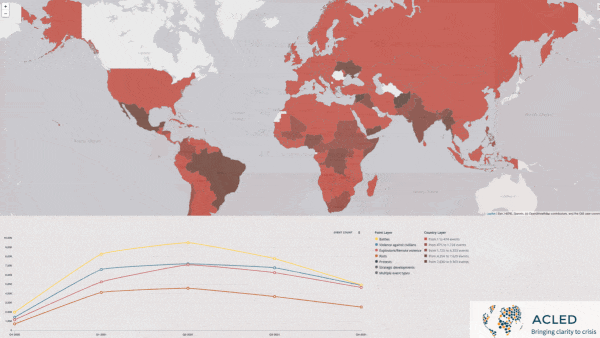
- Atchai, a data science company, trained a transformer model on a dataset of global protests and political violence from Armed Conflict Location & Event Data (ACLED). The system analyzed news reports to determine the causes of protests, then used topic modeling and clustering to show how various protests relate to one another.
- GroundTruth Global couples predictions drawn from machine learning with human analysis to understand volatility in developing economies.
- The United States military developed a system that predicts whether actions such as arms sales or diplomatic visits will increase tensions between the U.S. and China.
Yes, but: The executive director of the nonprofit One Earth Future, which managed CoupCast from 2016 to 2021, came to doubt that its predictions could have a meaningful impact on policy, he told The Washington Post. This and other concerns prompted him to turn over the project to the University of Central Florida.
Why it matters: Technology that helps people see what’s on the horizon may help prevent coups from spiraling into civil wars and humanitarian crises — or at least help people prepare for the worst.
We’re thinking: Modeling political unrest is an important but challenging small-data problem; CoupCast’s dataset included only 600 positive examples. Given the extremely high stakes of international relations, a data-driven approach seems like a productive complement to human analysis.
 |
More Learning With Less Memory
Researchers discovered a new way to reduce memory requirements when training large machine learning models.
What's new: Tim Dettmers and colleagues at University of Washington released 8-bit optimizers that store gradient statistics as 8-bit values, instead of the usual 32-bit, while maintaining the same accuracy.
Key insight: Popular optimizers like Adam use statistics derived from gradients to accelerate training. Adam uses an estimate of the change in the gradient of each weight over time, which can occupy as much as 50 percent of the memory required during training. However, at any given time, the optimizer needs only the estimates pertinent to the weights it’s currently processing. The remaining part can be quantized temporarily — that is, the numbers can be converted into fewer bits — to take up less memory.
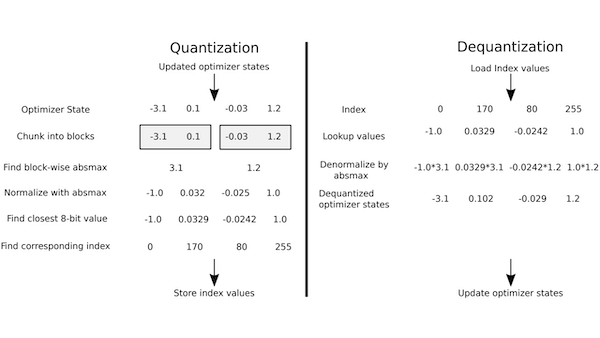
How it works: The authors used block-wise quantization, which means that gradient statistics were split into blocks and each block was quantized independently.
- During training, an optimizer updated parameters in groups (for example, the group of weights in a neural network’s first layer). After it updated the weights of one group, it quantized the group’s gradient statistics, stored them, and updated the next group.
- To perform quantization, the algorithm split the gradient statistics of one group into blocks of 2,048 numbers. For each block, it recorded the maximum absolute value, then divided the block’s elements using that value, so the maximum absolute value became 1. For each divided element, it looked up the closest 8-bit value, then stored the index (0...255) of that value.
- When it returned to a particular group, it dequantized the gradient statistics for that group by reversing the steps above. Then it performed another update and quantized the statistics again.
Results: The authors used their method on a few language tasks including machine translation and GLUE. Models trained on the 8-bit version of Adam achieved BLEU and accuracy scores on those tasks, respectively, nearly identical to those achieved by the 32-bit version. Using 8-bit Adam, authors fine-tuned a 1.5 billion-parameter GPT-2-large on an Nvidia V100 GPU with 24GB of memory. Using the 32-bit Adam optimizer, the hardware maxed out on a 762-million parameter GPT-2-medium.
Why it matters: Using an 8-bit optimizer makes it possible to train bigger models —in this work, roughly twice as big — on a given hardware configuration. For instance, now we can train Roberta-large — which is 1 percent to 5 percent more accurate than Roberta, according to the original paper — within the previous memory requirement for the smaller version.
We're thinking: Details like how much memory an optimizer uses may not seem worthy of attention when you’re designing and training a model — but, given the memory and processing requirements of deep learning models, sometimes they can have a big impact.