
An upstart chip company dramatically accelerates pretrained large language models.
What’s new: Groq offers cloud access to Meta’s Llama 2 and Mistral.ai’s Mixtral at speeds an order of magnitude greater than other AI platforms. Registered users can try it here.
How it works: Groq’s cloud platform is based on its proprietary GroqChip, a processor specialized for large language model inference that the company calls a language processing unit or LPU. The company plans to serve other models eventually, but its main business is selling chips. It focuses on inference on the theory that demand for a model’s inference can increase while demand for its training tends to be fixed.
- For approved users, Groq offers API access to Llama 2 70B (4,096-token context length, 300 tokens per second) for $0.70/$0.80 per million tokens of input/output, Llama 7B (2,048-token context length, 750 tokens per second) for $0.10 per million tokens, and Mixtral 8x7B SMoE (32,000-token context length, 480 tokens per second) for $0.27 per million tokens. A 10-day free trial is available.
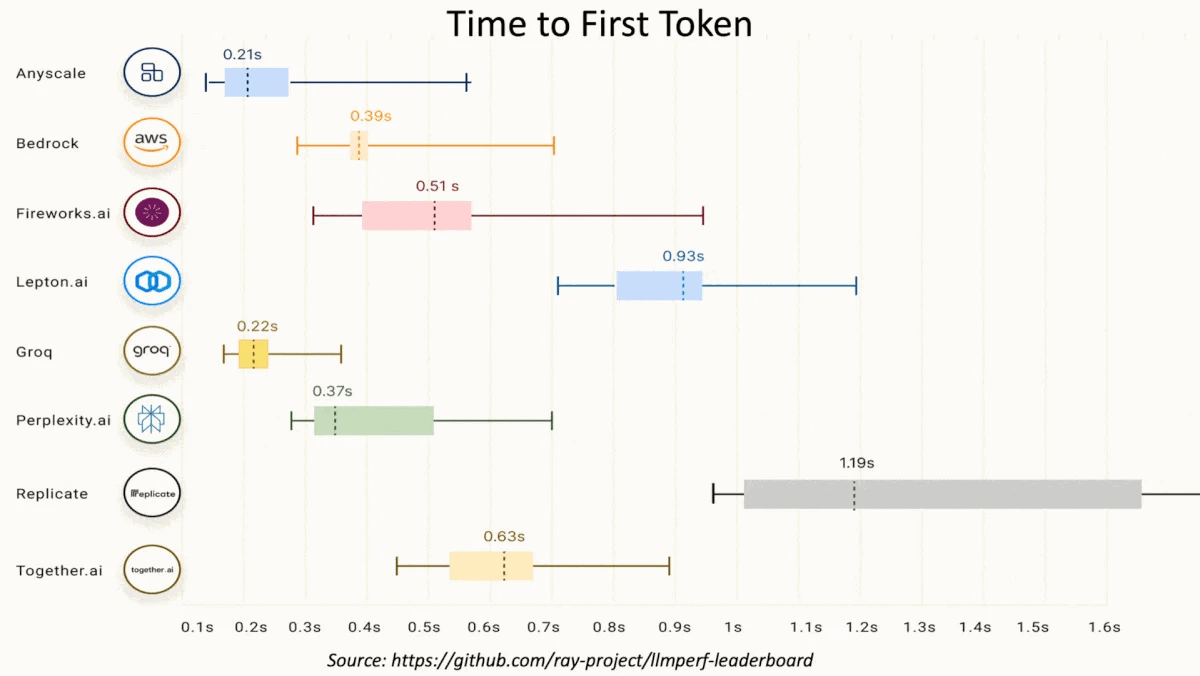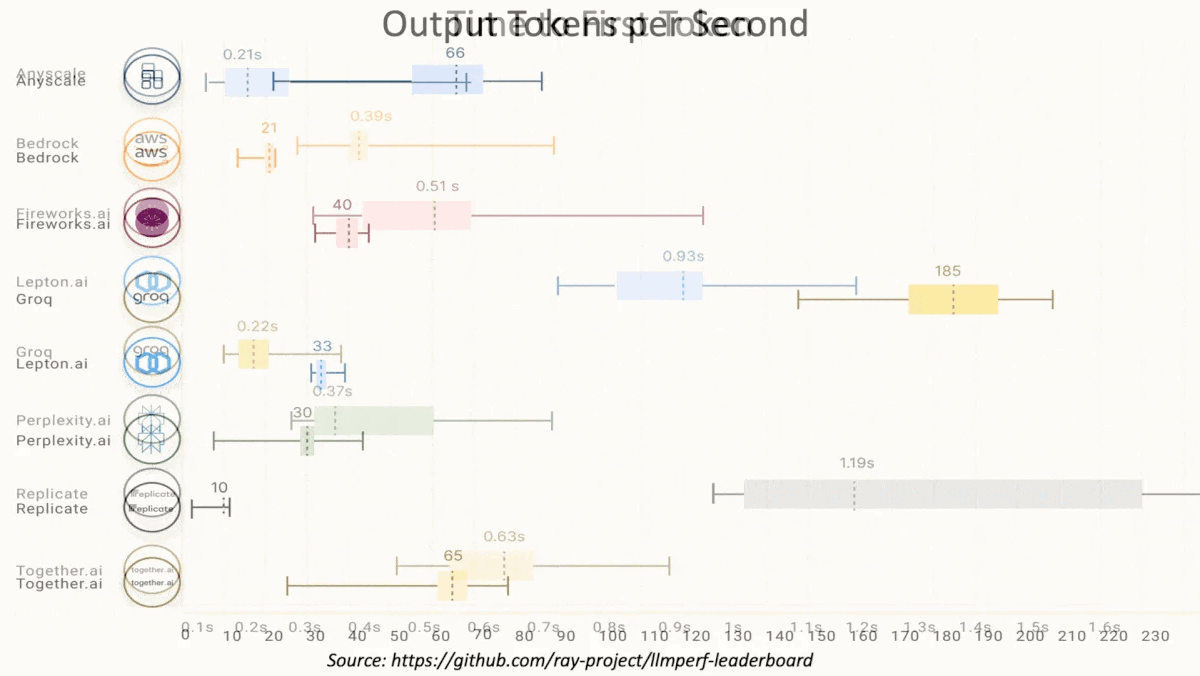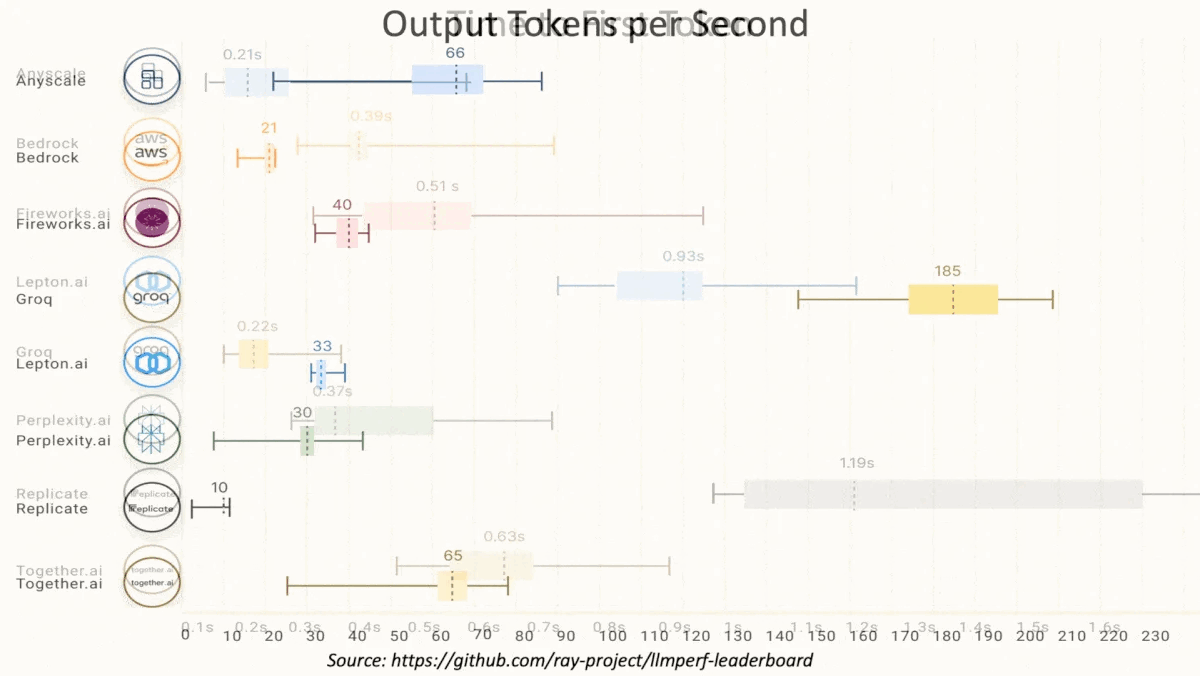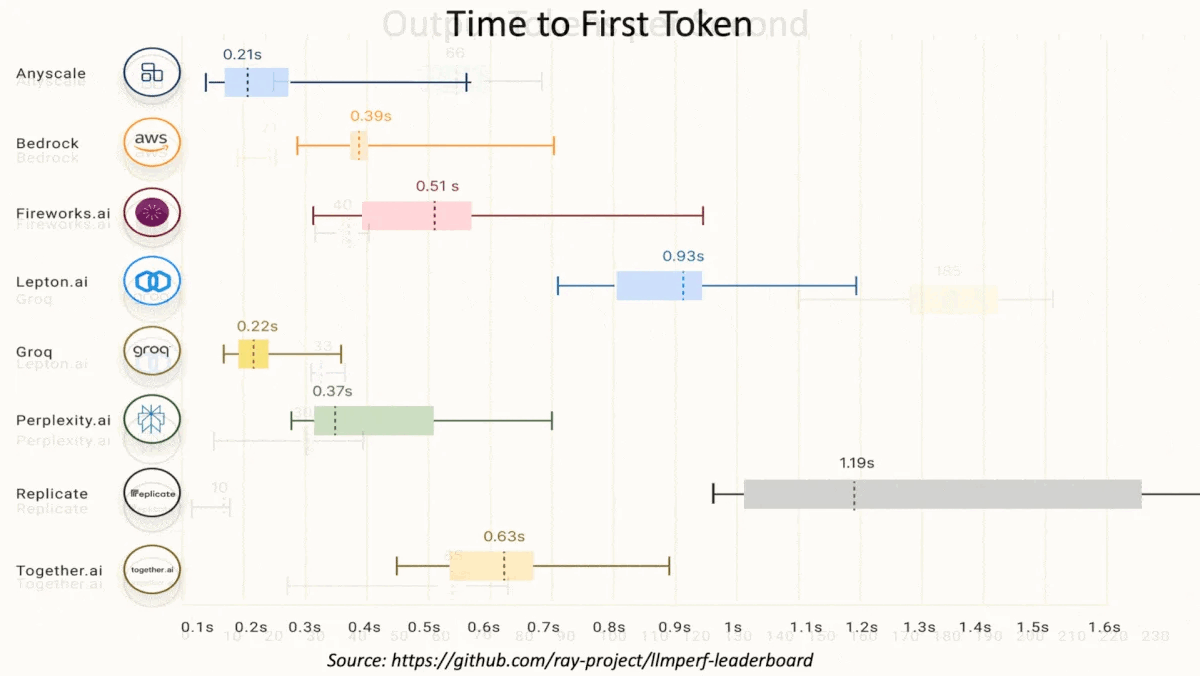
- The benchmarking service Artificial Analysis clocked the median speed of Groq’s instances of Llama 2 70B at 241 tokens per second, while Azure’s was around 18 tokens per second. In addition, the platform outperformed several other cloud services on the Anyscale LLMPerf benchmark, as shown in the image above.
- A variety of novel design features enable the chip to run neural networks faster than other AI chips including the industry-leading Nvidia H100.
Behind the news: Groq founder Jonathan Ross previously worked at Google, where he spearheaded the development of that company’s tensor processing unit (TPU), another specialized AI chip.
Why it matters: Decades of ever faster chips have proven that users need all the speed they can get out of computers. With AI, rapid inference can make the difference between halting interactions and real-time spontaneity. Moreover, Groq shows that there’s plenty of innovation left in computing hardware as processors target general-purpose computing versus AI, inference versus training, language versus vision, and so on.
We’re thinking: Autonomous agents based on large language models (LLMs) can get a huge boost from very fast generation. People can read only so fast, the faster generation of text that’s intended to be read by humans has little value beyond a certain point. But an agent (as well as chain-of-thought and similar approaches to prompting) might need an LLM to “think” through multiple steps. Fast LLM inference can be immensely useful for building agents that can work on problems at length before reaching a conclusion.