
Large language models sometimes generate false statements. New work makes them more likely to produce factual output.
What’s new: Katherine Tian, Eric Mitchell, and colleagues at Stanford and University of North Carolina proposed FactTune, a procedure that fine-tunes large language models (LLMs) to increase their truthfulness without collecting human feedback.
Key insight: Just as fine-tuning based on feedback has made LLMs less harmful, it can make them more factual. The typical method for such fine-tuning is reinforcement learning from human feedback (RLHF). But a combination of direct preference optimization (DPO) and reinforcement learning from AI feedback (RLAIF) is far more efficient. DPO replaces cumbersome reinforcement learning with a simpler procedure akin to supervised learning. RLAIF eliminates the cost of collecting human feedback by substituting model-generated preferences for human preferences.
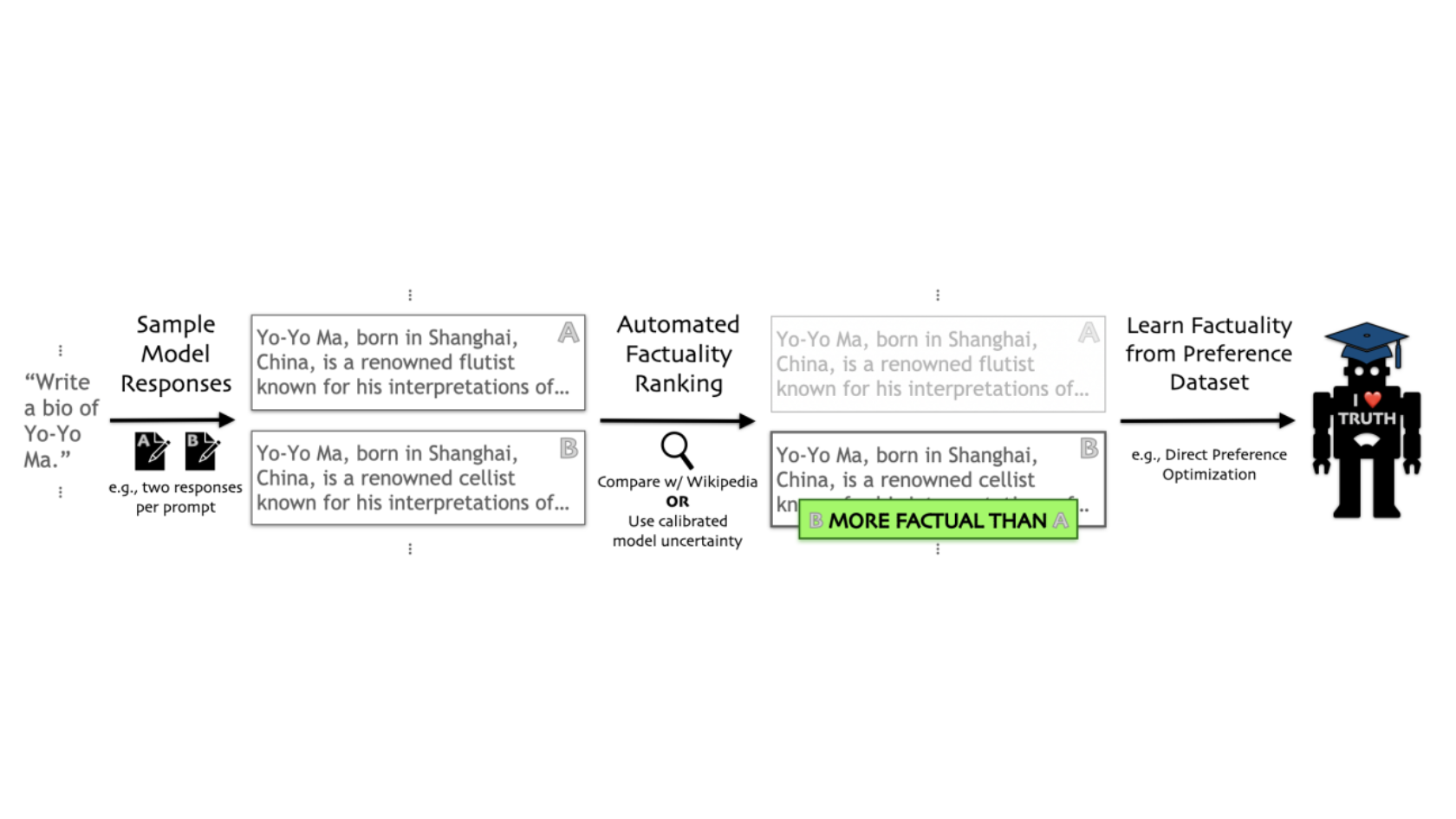
How it works: The authors built models designed to deliver factual output within a specific domain.
- The authors asked GPT-3.5 to prompt LLaMA-7B to generate 10 biographies of roughly 300 people profiled by Wikipedia.
- Instead of human fact checking, which would be prohibitively expensive, they relied on FActScore, an automated fact checker that uses a separate LLaMA fine-tuned for fact-checking to determine whether a separate model’s output is supported by Wikipedia. FActScore asked GPT-3.5 to extract claims in the biographies and determined whether each claim was supported by Wikipedia. Then it scored the biographies according to the percentage of supported claims.
- The authors built a dataset by choosing two biographies of the same person at random. They annotated the one with the higher factuality score as preferred and the one with the lower score as not preferred.
- They used the dataset to fine-tune the LLaMA-7B via Direct Preference Optimization (DPO).
Results: Fine-tuning by the authors’ method improved the factuality of models in two domains.
- The authors generated biographies of people in the test set using LLaMA-7B before and after fine-tuning via their method. Human judges who used Wikipedia as a reference deemed factual 58 percent of the claims generated by the model without fine-tuning and 85 percent of claims generated by the fine-tuned model.
- The authors generated answers to a wide variety of medical questions drawn from Wikipedia using LLaMA-7B before and after fine-tuning via their method. Judges gave factual ratings to 66 percent of answers generated by the model without fine-tuning and 84 percent of answers generated by the fine-tuned model.
Why it matters: LLMs are known to hallucinate, and the human labor involved in fact checking their output is expensive and time-consuming. The authors applied well tested methods to improve the factuality of texts while keeping human involvement to a minimum.
We’re thinking: This work, among others, shows how LLMs can bootstrap their way to better results. We’ve only just begun to explore combinations of LLMs working together as well as individual LLMs working iteratively in an agentic workflow.