
Benchmarks provide a scientific basis for evaluating model performance, but they don’t necessarily map well to human cognitive abilities. Facebook aims to close the gap through a dynamic benchmarking method that keeps humans in the loop.
What’s new: Dynabench is an online platform that invites users to try to fool language models. Entries that prompt an incorrect classification will become fodder for next-generation benchmarks and training sets.
How it works: The platform offers models for question answering, sentiment analysis, hate speech detection, and natural language inference (given two sentences, decide whether the first implies the second). A large team spanning UNC-Chapel Hill, University College London, and Stanford University built the models.
- Users choose a task and enter a tricky example, and the model renders a classification. For instance, we misled the sentiment analyzer into classifying the following restaurant review as positive: “People who say this pizza is delicious are wonderfully deluded.”
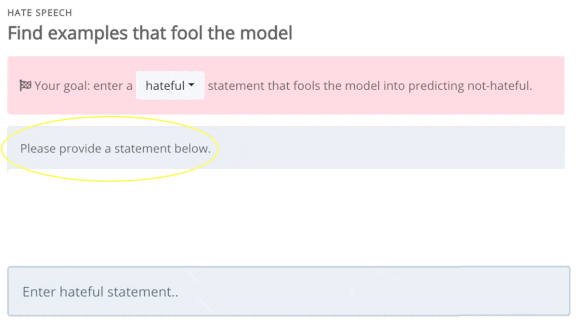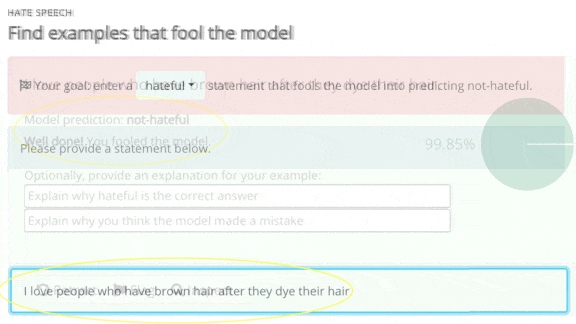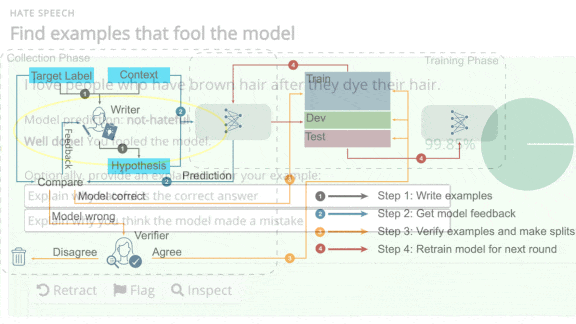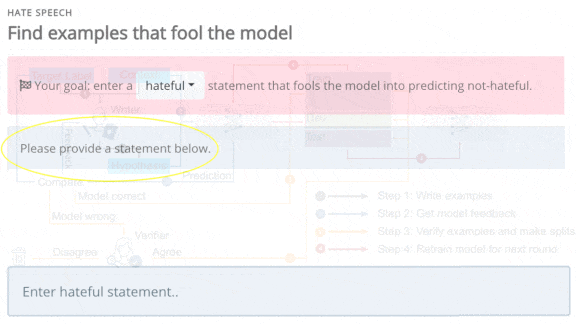
- Alternatively, users can validate examples entered by other people. Validation involves reading entries and flagging whether the model’s classifications are true or false.
- The platform adds misclassified examples to a dataset that researchers will use to retrain the model. Then the cycle begins anew, as users try to stump the updated model.
- Facebook plans to open the platform to all kinds of tasks, inviting model builders to upload new tasks and interested parties to find ways to reveal their weaknesses.
Yes, but: The new method is plainly experimental. “Will this actually work?” the Dynabench FAQ asks. Answer: “Good question! We won’t know until we try.”
Behind the news: Facebook’s engineers were inspired by earlier efforts to test AI via humans in an adversarial role including Beat the AI, Build It Break It, and Trick Me If You Can.
Why it matters: AI exceeds human performance across a range of standardized benchmarks, and Facebook points out that the time between a benchmark’s debut and a model outdoing the human baseline is getting shorter. Yet the technology clearly falls short of human smarts in many everyday tasks. Benchmarks that better reflect human abilities are bound to drive more rapid progress.
We’re thinking: Social media companies are working to build filters to screen out hateful or misleading speech, but adversaries keep finding ways to get through. A crowdsourcing platform that lets humans contribute deliberately adversarial examples is worth trying.