
Dear friends,
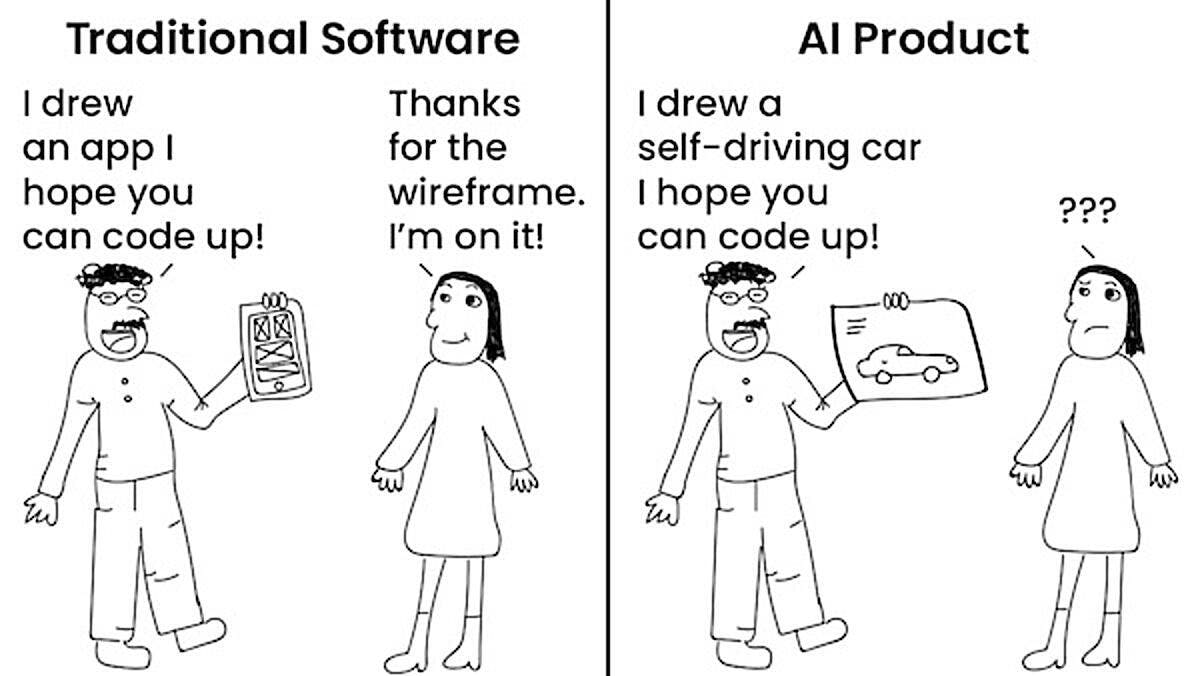
In a recent letter, I noted that one difference between building traditional software and AI products is the problem of complex product specification. With traditional software, product managers can specify a product in ways that communicate clearly to engineers what to build — for example, by providing a wireframe drawing. But these methods don’t work for AI products.
For an AI product, among the most important parts of the specification are:
The space of acceptable operating conditions (also called the operational design domain)
The level of performance required under various conditions, including machine learning metrics such as accuracy and software metrics such as latency and throughput
Consider the problem of how to build a self-driving car. We might decide the acceptable road conditions for autonomous operation and the acceptable rate of collisions with particular objects at various speeds (for example, gently bumping a traffic cone at five miles per hour every 1 million miles may be okay, but hitting a pedestrian at 20 miles per hour every 1,000 miles is not).
Or take reading electronic health records. What is an acceptable error rate when diagnosing a serious disease? How about the error rate when diagnosing a minor disease? What if human-level performance for a particular illness is low, so physicians tend to misdiagnose it, too?
Specifying the metrics, and the dataset or data distribution on which the metrics are to be assessed, gives machine learning teams a target to aim for. In this process, we might decide how to define a serious versus a minor disease and whether these are even appropriate concepts to define a product around. Engineers find it convenient to optimize a single metric (such as average test-set accuracy), but it’s not unusual for a practical specification to require optimizing multiple metrics.
Here are some ideas that I have found useful for specifying AI products.
Clearly define slices (or subsets) of data that raise concerns about the system’s performance. One slice might be minor diseases and another major diseases. If the system is intended to make predictions tied to individuals, we might check for undesirable biases by specifying slices that correspond to users of different age groups, genders, ethnicities, and so on.
For each slice, specify a level of performance that meets the user’s need, if it’s technically feasible. Also, examine performance across slices to ensure that the system meets reasonable standards of fairness.
If the algorithm performs poorly on one slice, it may not be fruitful to tweak the code. Consider using a data-centric approach to improve the quality of data in that slice. Often this is the most efficient way to address the problem.
I’ve found it very helpful to have sufficient data and a clear target specification for each slice. This isn’t always easy or even possible, but it helps the team advance toward a reasonable target.
As a team performs experiments and develops a sense of what’s possible as well as where the system might falter, the appropriate slices can change. If you’re a machine learning engineer who is part-way through the project, and the product manager changes the product specification, don’t be frustrated! Ask them to buy you a coffee (or tea or other beverage of your choice) for your trouble, but recognize that this is part of developing a machine learning system. Hopefully such changes will happen less frequently as the team gains experience.
Keep learning!
Andrew