
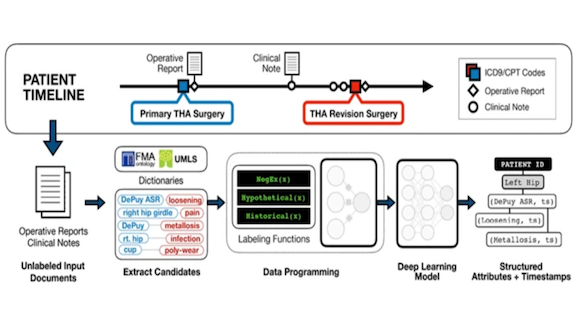
Weak supervision is the practice of assigning likely labels to unlabeled data using a variety of simple labeling functions. Then supervised methods can be used on top of the now-labeled data. Researchers used this technique to search electronic health records (EHRs) for information squirreled away in unstructured text.
What’s new: Complications from hip replacement surgery tend to be under-reported because they’re recorded in EHRs as notes rather than check-marked in a standard list. Researchers at Stanford used weak supervision to label such notes and then extracted information related to hip implants. Their method brought to light complications that hadn’t been tracked explicitly.
Key insight: Alison Callahan and collaborators divided the problem of finding references to post-surgical issues in notes into two parts: identifying the implant’s make and model, and spotting mentions of pain and complications. This made it possible to use weak supervision to label data separately for each subproblem.
How it works: Snorkel is a framework that provides a modular way to define and combine labeling functions. The model works as follows:
- Domain experts construct labeling functions to find the implant maker and type, mentions of pain and the anatomy affected, and mentions of the implant close to the complication it led to. For instance, a labeling function may spot a pain-related word adjacent to a body part and mark the corresponding sentence as evidence of pain. These functions assign labels for each subproblem in every sentence.
- A probabilistic model (graphical model) learns the relative accuracy of the labeling functions based on mutual overlaps and conflicts of their label assignments on the training data. These metrics are then used to combine labels from each labeling function into a single label for each subproblem in every sentence.
- An LSTM with attention is trained on the newly labeled data to spot complications arising from certain implants and map pain to body parts.
Results: The researchers trained the system on records of about 6,000 hip-replacement patients treated between 1995 and 2014. Learning the relationships between the various labeling functions uncovered twice as many patients facing complications as majority voting on their predictions (61 percent versus 32 percent). Overall, the system made it possible to assess the likelihood that a particular implant would lead to complications.
Why it matters: This analysis could help doctors to match patients with appropriate implants, and help implant manufacturers design their products to minimize bad outcomes.
Takeaway: This approach extracts useful information from EHRs, and it looks as though it would generalize to other text-labeling tasks.