
Dear friends,
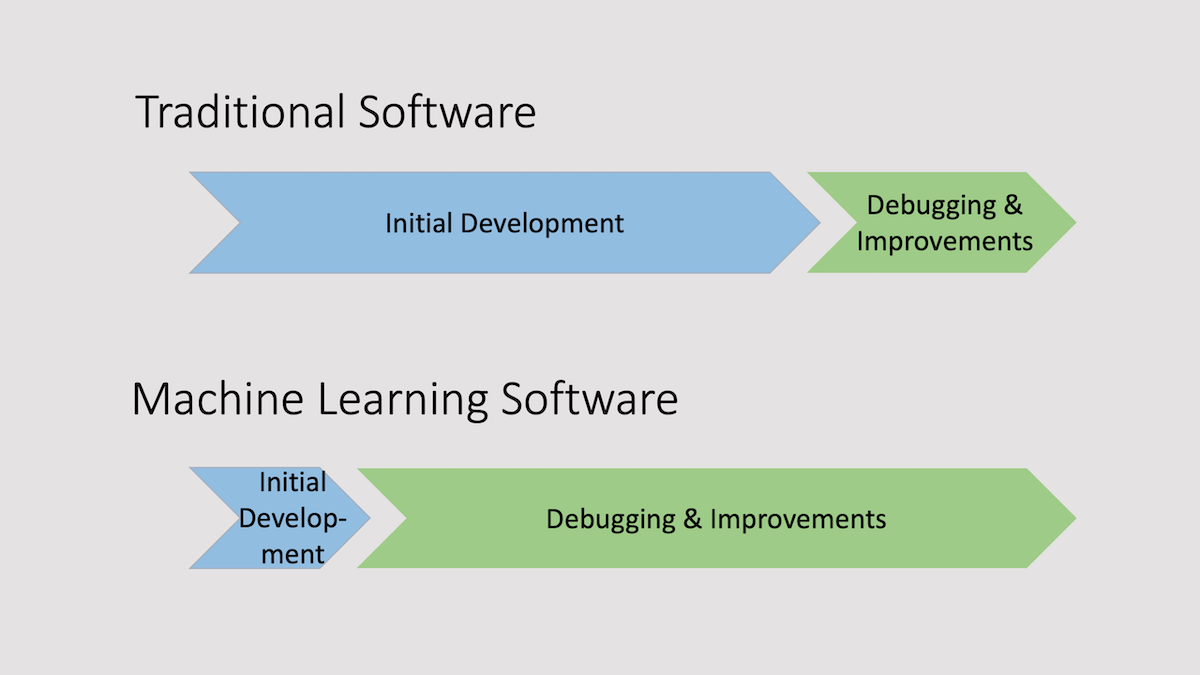
Internalizing this mental framework has made me a more efficient machine learning engineer: Most of the work of building a machine learning system is debugging rather than development.
This idea will likely resonate with machine learning engineers who have worked on supervised learning or reinforcement learning projects for years. It also applies to the emerging practice of prompt-based AI development.
When you’re building a traditional software system, it’s common practice to write a product spec, then write code to that spec, and finally spend time debugging the code and ironing out the kinks. But when you’re building a machine learning system, it’s frequently better to build an initial prototype quickly and use it to identify and fix issues. This is true particularly for building applications that humans can do well, such as unstructured data tasks like processing images, audio, or text.
- Build a simple system quickly to see how well it does.
- Figure out where it falls short (via error analysis or other techniques), and iteratively try to close the gap between what the system does and what a human (such as you, the developer, or a domain expert) would do given the same data.
Machine learning software often has to carry out a sequence of steps; such systems are called pipelines or cascades. Say, you want to build a system to route an ecommerce site’s customer emails to the appropriate department (is this apparel, electronics, . . . ), then retrieve relevant product information using semantic search, and finally draft a response for a human representative to edit. Each of these steps could have been done by a human. By examining them individually and seeing where the system falls short of human-level performance, you can decide where to focus your attention.
While debugging a system, I frequently have a “hmm, that looks strange” moment that suggests what to try next. For example, I’ve experienced each of the following many times:
- The learning curve doesn’t quite look right.
- The system performs worse on what you think are the easier examples.
- The loss function outputs values that are higher or lower than you think it should.
- Adding a feature that you thought would help performance actually hurt.
- Performance on the test set is better than seems reasonable.
- An LLM’s output is inconsistently formatted; for example, including extraneous text.
When it comes to noticing things like this, experience working with multiple projects is helpful. Machine learning systems have a lot of moving parts. When you have seen many learning curves, you start to hone your instincts about what’s normal and what’s anomalous; or when you have prompted a large language model (LLM) to output JSON many times, you start to get a sense of the most common error modes. These days, I frequently play with building different small LLM-based applications on weekends just for fun. Seeing how they behave (as well as consulting with friends on their projects) is helping me to hone my own instincts about when such applications go wrong, and what are plausible solutions.
Understanding how the algorithms work really helps, too. Thanks to development tools like TensorFlow and PyTorch, you can implement a neural network in just a few lines of code — that’s great! But what if (or when!) you find that your system doesn’t work well? Taking courses that explain the theory that underlies various algorithms is useful. If you understand at a technical level how a learning algorithm works, you’re more likely to spot unexpected behavior, and you’ll have more options for debugging it.
The notion that much of machine learning development is akin to debugging arises from this observation: When we start a new machine learning project, we don’t know what strange and wonderful things we’ll find in the data. With prompt-based development, we also don’t know what strange and wonderful things a generative model will produce. This is why machine learning development is much more iterative than traditional software development: We’re embarking on a journey to discover these things. Building a system quickly and then spending most of your time debugging it is a practical way to get such systems working.
Keep learning!
Andrew