
The process known as image-to-image style transfer — mapping, say, the character of a painting’s brushstrokes onto a photo — can render inconsistent results. When they apply the styles of different artists to the same target content, they may produce similar-looking pictures. Conversely, when they apply the same style to different targets, such as successive video frames, they may produce images with unrelated shapes and colors. A new approach aims to address these issues.
What’s new: Min Jin Chong and David Forsyth at University of Illinois at Urbana-Champaign proposed GANs N’ Roses, a style transfer system designed to maintain the distinctive qualities of input styles and contents.
Key insight: Earlier style transfer systems falter because they don't clearly differentiate style from content. Style can be defined as whatever doesn’t change when an image undergoes common data-augmentation techniques such as scaling and rotation. Content can be defined as whatever is changed by such operations. A loss function that reflects these principles should produce more consistent results.
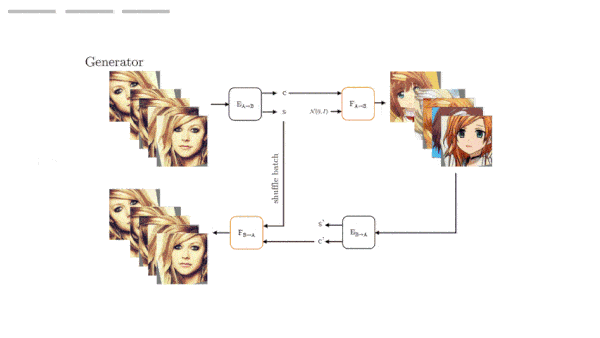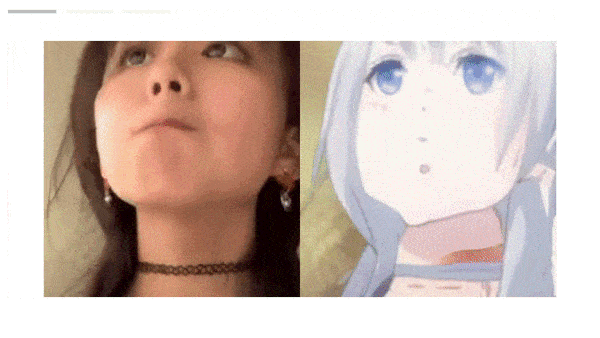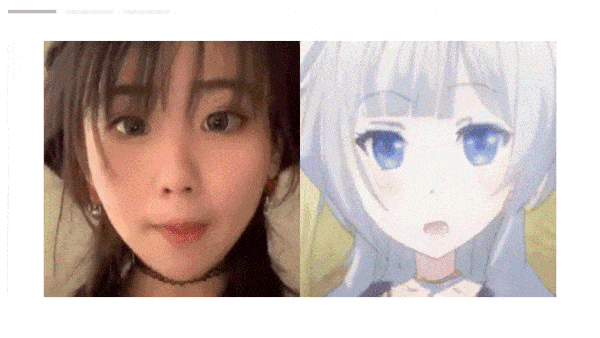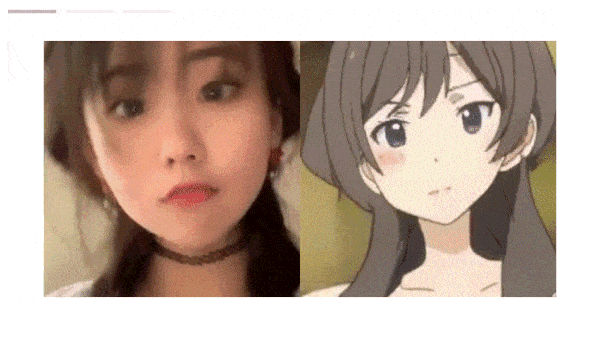
How it works: Like other generative adversarial networks, GANs N’ Roses includes a discriminator that tries to distinguish synthetic anime images from actual artworks and a generator that aims to fool the discriminator. The architecture is a StyleGAN2 with a modified version of CycleGAN’s loss function. The authors trained it to transfer anime styles to portrait photos using selfie2anime, a collection of unmatched selfies and anime faces. The authors created batches of seven anime faces and seven augmented versions of a single selfie (flipped, rotated, scaled, and the like).
- The generator used separate encoder-decoder pairs to translate selfies to animes (we’ll call this the selfie-to-anime encoder and decoder) and, during training only, animes to selfies (the anime-to-selfie encoder and decoder).
- For each image in a batch, the selfie-to-anime encoder extracted a style representation (saved for the next step) and a content representation. The selfie-to-anime decoder received the content representation and a random style representation, enabling it to produce a synthetic anime image with the selfie’s content in a random style.
- The anime-to-selfie encoder received the synthetic anime image and extracted a content representation. The anime-to-selfie decoder took the content representation and the selfie style representation generated in the previous step, and synthesized a selfie. In this step, a cycle consistency loss minimized the difference between original selfies and those synthesized from the anime versions; this encouraged the model to maintain the selfie’s content in synthesized anime pictures. A style consistency loss minimized the variance of selfie style representations within a batch; this minimized the effect of the augmentations on style.
- The discriminator received synthetic and actual anime images and classified them as real or not. A diversity loss encouraged a similar standard deviation among all synthetic and all actual images; thus, different style representations would tend to produce distinct styles.
Results: Qualitatively, the system translated different selfies into corresponding anime poses and face sizes, and different styles into a variety of colors, hair styles, and eye sizes. Moreover, without training the networks on video, the authors rendered a series of consecutive video frames. Subjectively, those videos were smooth, while those produced by CouncilGAN’s frames showed inconsistent colors and hairstyles. In quantitative evaluations comparing Frechet Inception Distance (FID), a measure of similarity between real and generated images in which lower is better, GANs N’ Roses achieved 34.4 FID while CouncilGAN achieved 38.1 FID. Comparing Learned Perceptual Image Patch Similarity (LPIPS), a measure of diversity across styles in which higher is better, GANs N’ Roses scored .505 LPIPS while CouncilGAN scored .430 LPIPS.
Why it matters: If style transfer is cool, better style transfer is cooler. The ability to isolate style and content — and thus to change content while keeping style consistent — is a precondition for extending style transfer to video.
We’re thinking: The next frontier: Neural networks that not only know the difference between style and content but also have good taste.