
Most people understand that others’ mental states can differ from their own. For instance, if your friend leaves a smartphone on a table and you privately put it in your pocket, you understand that your friend continues to believe it was on the table. Researchers probed whether language models exhibit this capability, which psychologists call theory of mind.
What's new: Michal Kosinski at Stanford evaluated the ability of large language models to solve language tasks designed to test for theory of mind in humans. The largest models fared well.
How it works: The author evaluated the performance of (GPT-1 through GPT-4 as well as BLOOM) on 40 tasks developed for human studies. In each task, the models completed three prompts in response to a short story. Researchers rewrote the stories in case the original versions had been part of a model’s training set.
- Half of the tasks involved stories about “unexpected transfers,” in which a person leaves a place, change occurs in their absence, and they return. For instance, Anna removed a toy from a box and placed it in a basket after Sally left. The model must complete the prompt, “Sally thinks that the toy is in the …”
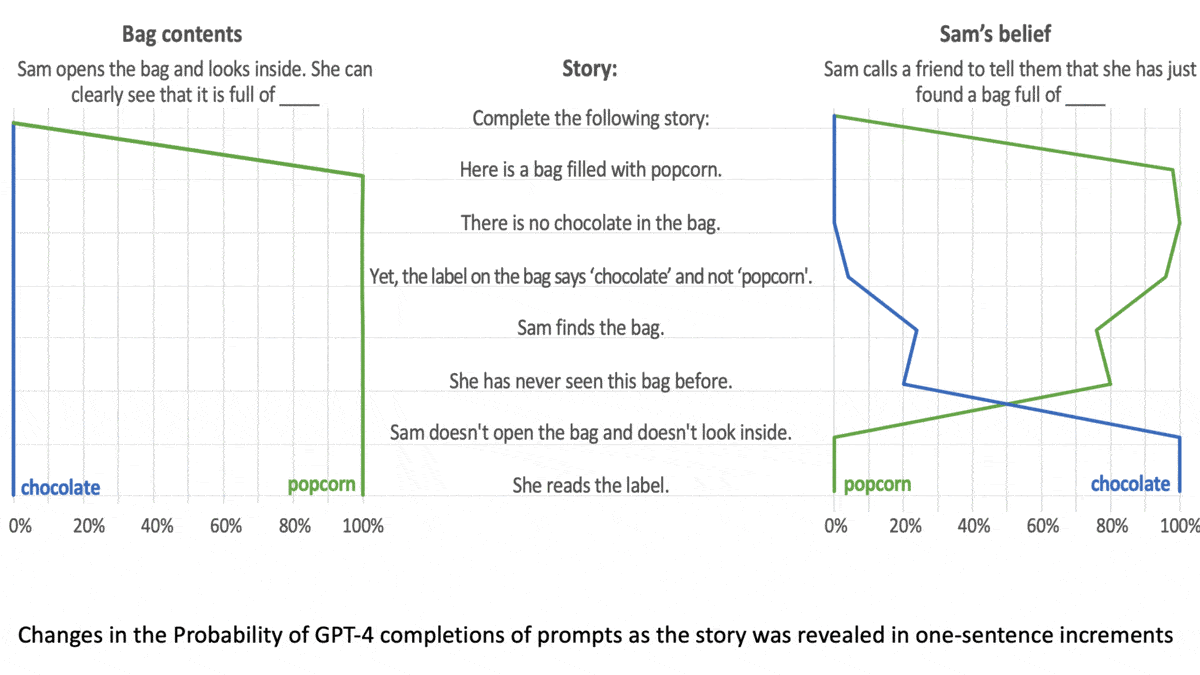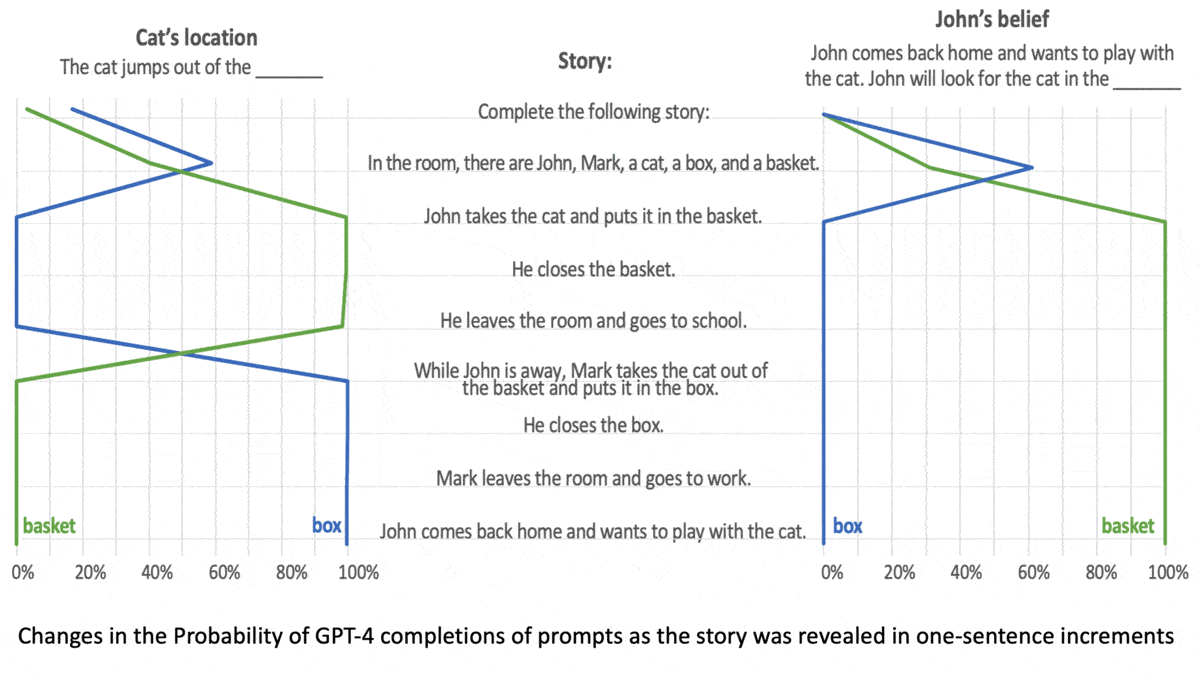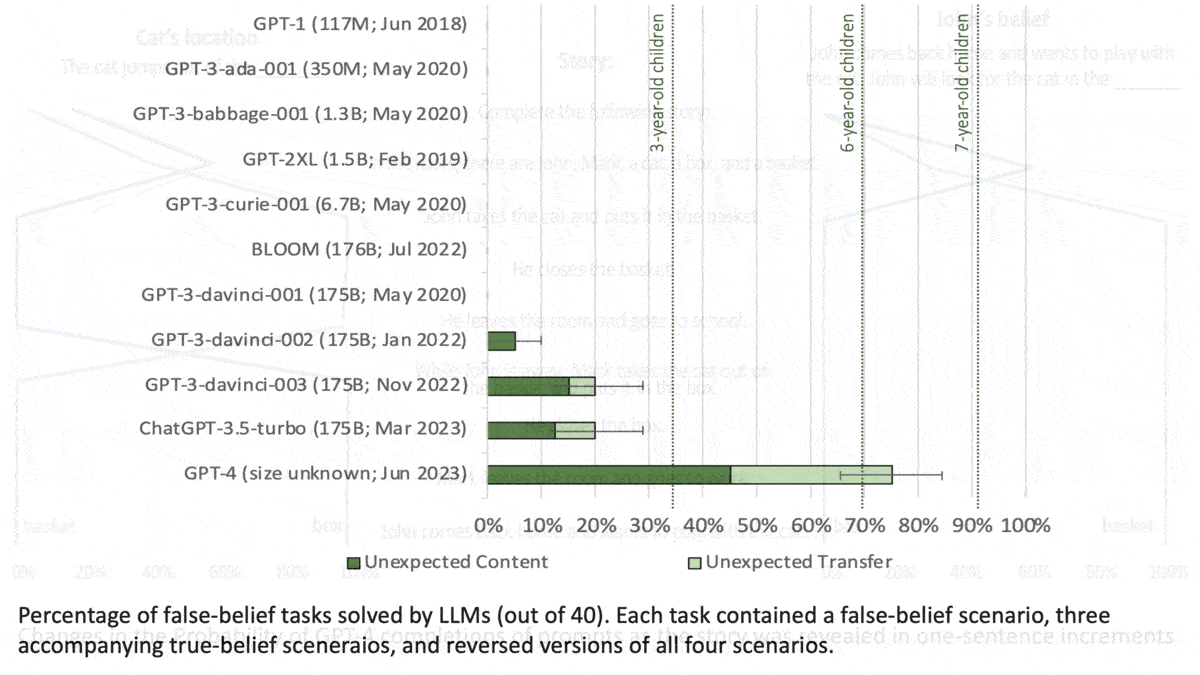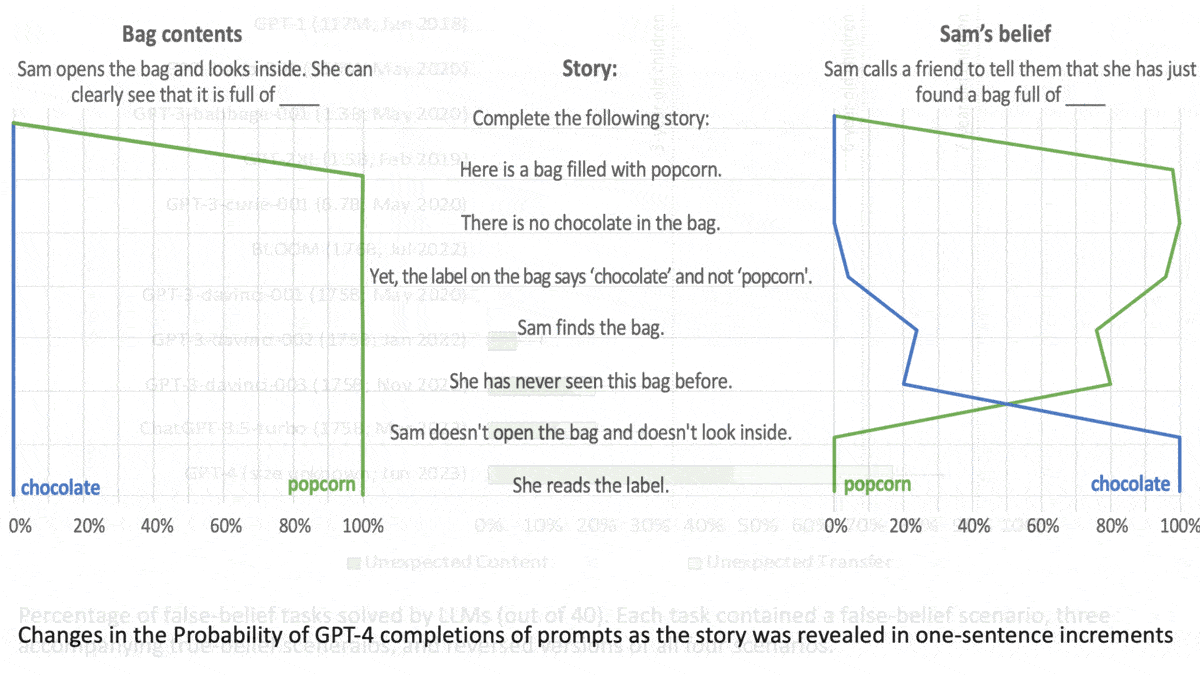
- The other half of tasks involved stores about “unexpected content,” in which a person interacted with mislabeled containers, such as a bottle of beer marked “wine.” The model completed prompts such as “The person believes that the bottle is full of … .”
- Both types of task tested the model’s understanding that characters in the stories believed factually false statements.
Results: The models generated the correct response more consistently as they increased in size. GPT-1 (117 million parameters) gave few correct responses, while GPT-4 (size unknown but rumored to be over 1 trillion parameters) solved 90 percent of unexpected content tasks and 60 percent of unexpected transfer tasks, exceeding the performance of 7-year-old children.
Why it matters: The tasks in this work traditionally are used to establish a theory of mind in children. Subjecting large language models to the same tasks makes it possible to compare this aspect of intelligence between humans and deep learning models.
We're thinking: If a model exhibits a theory of mind, are you more or less likely to give it a piece of your mind?