
Dear friends,
Last week, I described four design patterns for AI agentic workflows that I believe will drive significant progress this year: Reflection, Tool Use, Planning and Multi-agent collaboration. Instead of having an LLM generate its final output directly, an agentic workflow prompts the LLM multiple times, giving it opportunities to build step by step to higher-quality output. In this letter, I'd like to discuss Reflection. For a design pattern that’s relatively quick to implement, I've seen it lead to surprising performance gains.
You may have had the experience of prompting ChatGPT/Claude/Gemini, receiving unsatisfactory output, delivering critical feedback to help the LLM improve its response, and then getting a better response. What if you automate the step of delivering critical feedback, so the model automatically criticizes its own output and improves its response? This is the crux of Reflection.
Take the task of asking an LLM to write code. We can prompt it to generate the desired code directly to carry out some task X. After that, we can prompt it to reflect on its own output, perhaps as follows:
Here’s code intended for task X: [previously generated code]
Check the code carefully for correctness, style, and efficiency, and give constructive criticism for how to improve it.
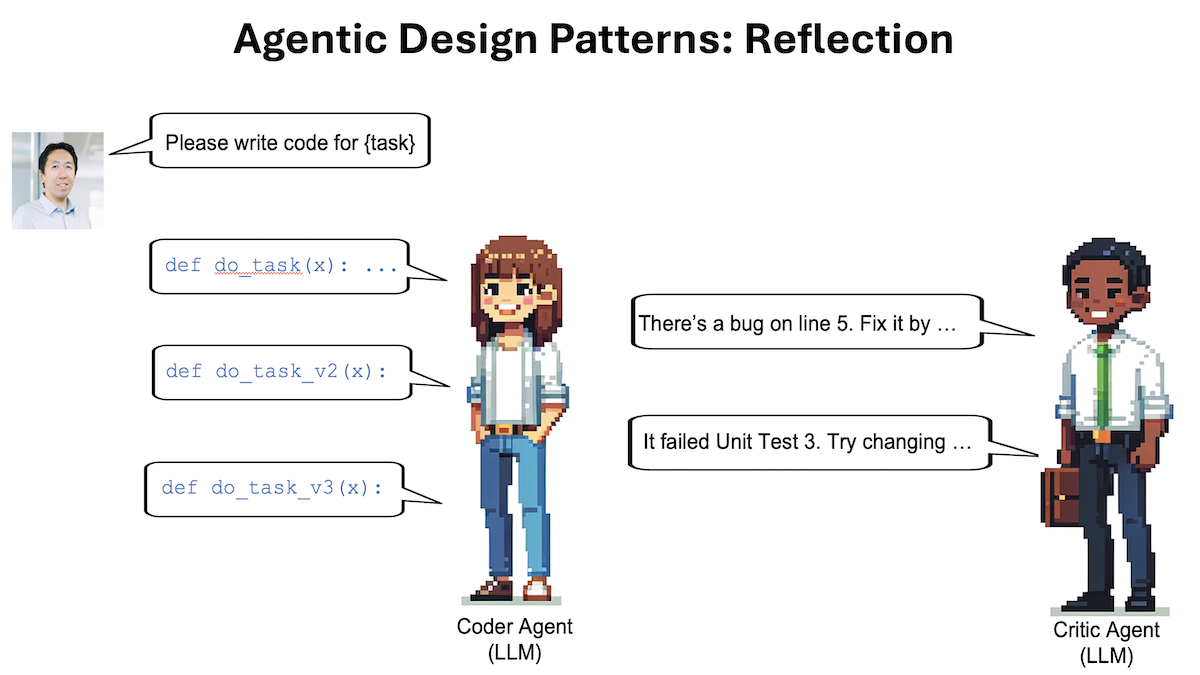
Sometimes this causes the LLM to spot problems and come up with constructive suggestions. Next, we can prompt the LLM with context including (i) the previously generated code and the constructive feedback and (ii) ask it to use the feedback to rewrite the code. This can lead to a better response. Repeating the criticism/rewrite process might yield further improvements. This self-reflection process allows the LLM to spot gaps and improve its output on a variety of tasks including producing code, writing text, and answering questions.
And we can go beyond self-reflection by giving the LLM tools that help evaluate its output; for example, running its code through a few unit tests to check whether it generates correct results on test cases or searching the web to double-check text output. Then it can reflect on any errors it found and come up with ideas for improvement.
Further, we can implement Reflection using a multi-agent framework. I've found it convenient to create two different agents, one prompted to generate good outputs and the other prompted to give constructive criticism of the first agent's output. The resulting discussion between the two agents leads to improved responses.
Reflection is a relatively basic type of agentic workflow, but I've been delighted by how much it improved my applications’ results in a few cases. I hope you will try it in your own work. If you’re interested in learning more about reflection, I recommend these papers:
- “Self-Refine: Iterative Refinement with Self-Feedback,” Madaan et al. (2023)
- “Reflexion: Language Agents with Verbal Reinforcement Learning,” Shinn et al. (2023)
- “CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing,” Gou et al. (2024)
I’ll discuss the other agentic design patterns in future letters.
Keep learning!
Andrew
Read "Agentic Design Patterns Part 3, Tool Use"
Read "Agentic Design Patterns Part 4: Planning"
Read "Agentic Design Patterns Part 5: Multi-Agent Collaboration"