
Dear friends,
Over the weekend, my family celebrated my grandfather’s 102nd birthday on Zoom. We dialed in from Hong Kong (my grandfather), the U.S. (myself), the UK, Singapore, and New Zealand. In a normal year, I might not have made it to Hong Kong for the party. But because we now celebrate on Zoom, I was able to attend. For my family, the occasion was a bright spot amid the global tragedy of the pandemic.
Many people are wondering when the world will go back to normal. I believe the world one day will become normal again, but the new normal will be very different from the normal of yesteryear.
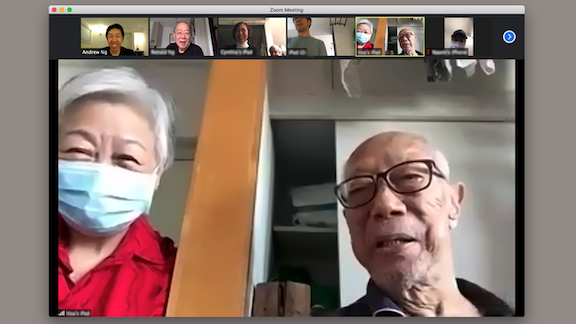
Just as the Covid crisis led me to attend my grandfather’s birthday party, once the virus recedes, our newfound ease with high-quality telecommunications will bring people together virtually for all kinds of purposes.
My teams in Colombia now work with my U.S. staff more smoothly than they did pre-Covid — it matters less and less whether my teammates are in Medellin, Colombia, or Palo Alto, California. I look forward to a world where digital communications enable anyone anywhere to receive an education and have access to meaningful job opportunities.
I hope all of you will live long, healthy lives like my grandfather. Although we find comfort in the past, it is by actively creating the future that we move forward. It’s up to each of us to constantly envision and create a better future.
Keep learning!
Andrew
News

Generation Text
People granted early access to OpenAI’s latest language model are raving about its way with words — and more.
What’s new: Beta testers of GPT-3 are showing off the model’s ability to write business memos, craft blogs, pen tweets, and even generate computer code. You can apply for access to the API via this link. A paid version is expected in about two months.
Demo explosion: Yaser Martinez Palenzuela, a data scientist at Deutsche Telekom, compiled a list of demos on Github. Here are a few of our favorites.
- A venture capitalist at Founders Fund used the system to help write an investment memo and declared himself “truly amazed” by its output.
- It composed a convincing blog post comparing itself to bitcoin, based only on a headline and one-sentence summary provided by an executive at Zeppelin Solutions, which provides blockchain technology.
- Entrepreneur Sharif Shameem showed that the model, prompted by descriptions of website features, can generate working code.
- Product designer Jordan Singer built a GPT-3 interface to a graphics program that renders code for plugins based on brief descriptions.
- A student at Oregon State University asked the model a series of physics questions meant to test its ability to reason. It responded with many correct answers.
Hype alert: OpenAI often has been accused of exaggerating the capabilities of its new technologies. Initially it withheld GPT-2, saying the model was too dangerous to release, and it has threatened to cancel GPT-3 access for anyone who uses the tech maliciously. Yet the company itself warns against overhyping the new model. “It still has serious weaknesses and sometimes makes very silly mistakes,” OpenAI CEO Sam Altman wrote in a tweet.
Bigger is better: GPT-3 owes much of its performance to a gargantuan parameter count of 175 billion, which dwarfs GPT-2’s 1.5 billion and exceeds by an order of magnitude recent models from Google (11 billion) and Microsoft (17 billion).
Why it matters: Large language models based on the transformer architecture have made natural language processing one of the most exciting areas of machine learning. They’re also raising AI’s public profile. GPT-3 is quickly becoming the technology’s foremost spokesbot.
We’re thinking: Sometimes GPT-3 writes like a passable essayist, sometimes like an insightful poet. But after reading the fascinating AI Weirdness blog post in which author Janelle Shane gives the model a question-and-answer workout, it seems a lot like some public figures who pontificate confidently on topics they know little about.

Grade-AI Sushi
Computer vision is helping sushi lovers enjoy top-quality maguro.
What’s new: Japanese restaurant chain Kura Sushi is using a smartphone app called Tuna Scope to grade its suppliers’ offerings, according to the news outlet The Asahi Shimbun.
How it works: Professional tuna graders assess tuna quality by examining a cross section of a fish’s tail for color, sheen, firmness, and fat patterns. The app, developed by Tokyo-based advertising and technology company Dentsu, mimics an experienced grader’s judgement.
- The model was trained on 4,000 images of tuna tail cross sections annotated by human graders. In tests, the app’s grades matched those given by humans nearly 90 percent of the time.
- Tuna sellers use the app to photograph a fish’s tail section, then send its automated assessment to Kura Sushi’s agents, who decide whether to purchase the fish.
- In a promotional trial, the restaurant offered tuna ranked highly by the system in a Tokyo restaurant, where they branded it “AI Tuna.” Ninety percent of roughly 1,000 customers who tried it said they were satisfied.
Behind the news: Computer vision is proving helpful in other parts of the seafood supply chain.
- Microsoft developed a tool that counts and measures farmed salmon, sparing workers boat trips to offshore pens.
- NOAA scientists are developing a boat-towed camera that counts bottom-dwelling fish to help prevent overharvesting of Alaska’s wild pollock.
Why it matters: Kura Sushi normally purchases 70 percent of its tuna overseas, but Covid-19 travel restrictions have made it difficult to assess the catch on-site. The app enables the company to buy fish caught anywhere without sending employees to the docks.
We’re thinking: The engineers who built this app appear to be quite talented. We hope the company isn’t giving them a raw deal.
Less (Video) is More (Examples)
We’d all love to be able to find similar examples of our favorite cat videos. But few of us want to label thousands of similar videos of even the cutest kitties. New research makes headway in video classification when training examples are scarce.
What’s new: Jingwei Ji and Zhangjie Cao led Stanford researchers in developing Ordered Temporal Alignment Module (Otam), a model that classifies videos even with limited training data.
Key insight: ImageNet provides over a million training examples for image classification models, while the Kinetics video dataset offers an order of magnitude fewer. But each video comprises hundreds of individual frames, so video datasets typically contain more images than image datasets. Why not take advantage of all those examples by applying image recognition techniques to videos? That way, each frame, rather than each video as a whole, serves as a training example.
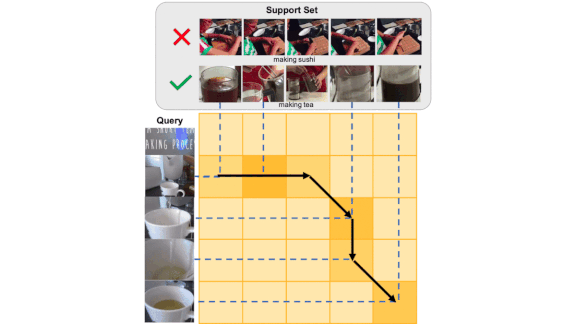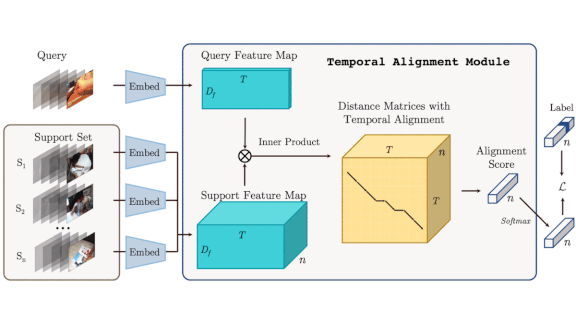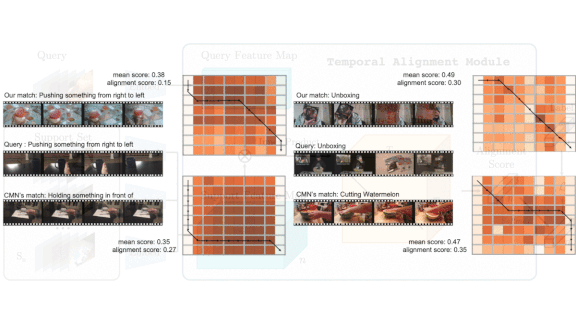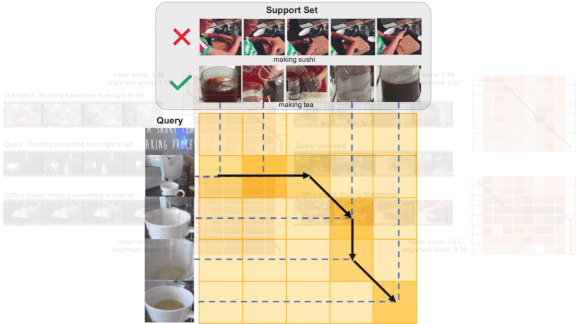
How it works: The task is to find the training video most similar to an input video and apply the same label. A convolutional neural network pre-trained on ImageNet extracts features for each input frame. Then the system compares the features and finds an alignment between the frames of a novel video and those of a training video. The CNN comprises the only trainable parameters.
- For each pair of frames from a novel video and a training video, Otam generates a similarity score. The pairs can be represented in a matrix whose rows are novel video frames and columns are training video frames. For example, (1,1) is the similarity between first frames and (2,1) represents the similarity between the second frame of the input video and the first frame of the training set video.
- Otam constructs a path through the similarity matrix by connecting frame pairs that are most similar. If an input video and training videos are identical, the path follows the diagonal.
- The system aligns similar frames over time even if the videos differ in length. For instance, if two videos depict different people brewing tea, and one person moves more slowly than the other, Otam will match frames essential to the action and ignore the extra frames that represent the slow-moving brewer. The system calculates video-video similarity by summing frame-frame similarities along the path. In this way, the CNN learns to extract features that lead to similar paths for videos of the same class.
- Ordering frame pairs by similarity can’t be optimized directly via backprop. The researchers formulated a continuous relaxation that weights every possible path by its similarity. (A continuous relaxation takes a nondifferentiable, discrete problem and approximates it with a continuous function that has better-behaved gradients, so backprop can optimize it. For instance, softmax is a continuous relaxation for the operation argmax.)
Results: On the Kinetics dataset (clips of people taking various actions in a few sections each), Otam achieved one-shot accuracy of 73 percent, a big improvement over the previous state of the art, 68.4 percent. Otam similarly improved the state of the art on Something V2 dataset, which comprises clips of people interacting with everyday objects.
Why it matters: Some prior video classification systems also use pre-trained CNNs, but they include sequential layers that require lots of video data to train, since an entire video serves as a single training example. Otam eliminates much of that data hunger.
We’re thinking: Videos typically include a soundtrack. We hope the next iteration of Otam will compare sounds as well as images.
A MESSAGE FROM DEEPLEARNING.AI

We’re thrilled to announce the launch of Course 3 of our Natural Language Processing Specialization on Coursera! Enroll now
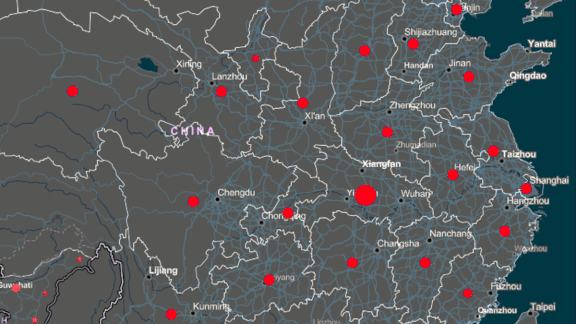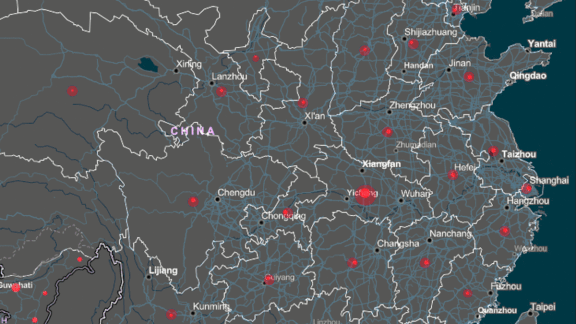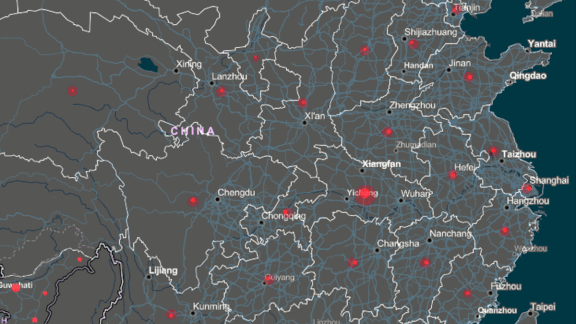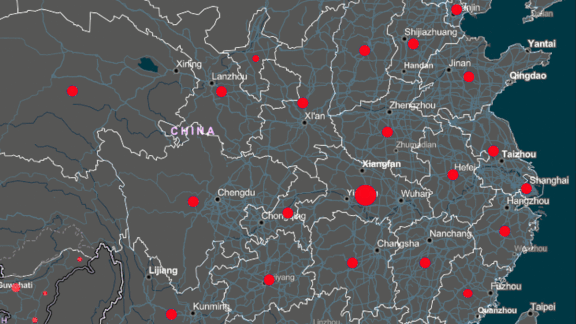
AI Against Covid: Progress Report
A new report details the role of AI in China’s effort to fight the coronavirus.
What’s new: Researchers at Synced, a China-based AI publication, describe how nearly 90 machine learning products have contributed to the country’s pandemic response.
What it says: The report presents case studies in five areas: thermal imaging, medical imaging, epidemiology, contact tracing, and drug discovery. A few examples:
- Infervision trained a computer vision system to detect signs of pneumonia on lung tissue shown in CT scans, helping to alleviate a shortage of human technicians typically needed to interpret this data.
- Municipalities are using a language processing platform from Yidu Cloud to parse information from officials and health care systems, helping them track and predict the virus’ spread.
- Guangdong Province uses MiningLamp Technology’s machine learning platform to trace people who have come in contact with Covid carriers.
- An infrared sensor from Athena Security scans crowds for people running a fever, a common Covid-19 symptom. When it spots an overheated individual, it uses face identification to log their identity and status in the cloud.
- Researchers developing vaccines are using Baidu’s AI-powered gene sequencing tool to decode the virus’ genetic structure rapidly.
Yes, but: Critics have pointed out shortcomings of machine learning in the fight against Covid-19 so far. In April, for example, two groups of researchers audited Covid-related machine learning models. They found bias in many systems for analyzing hospital admissions, diagnosis, imaging, and prognosis.
Why it matters: Not all AI-against-Covid initiatives will prove to be effective. Tracking the approaches underway is crucial to finding the ones that work.
We’re thinking: Artificial intelligence still needs to be complemented by human intelligence. Please wear a mask!
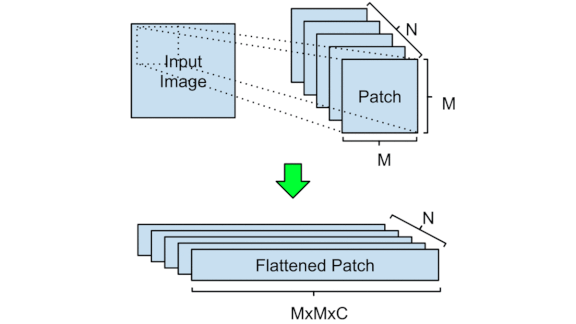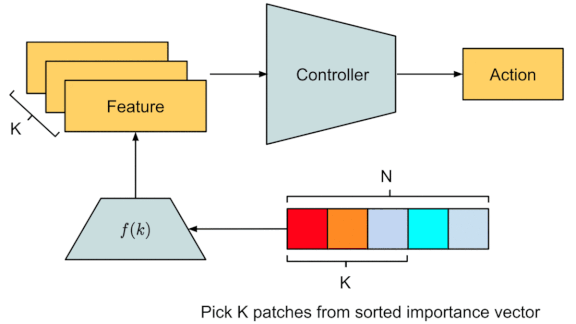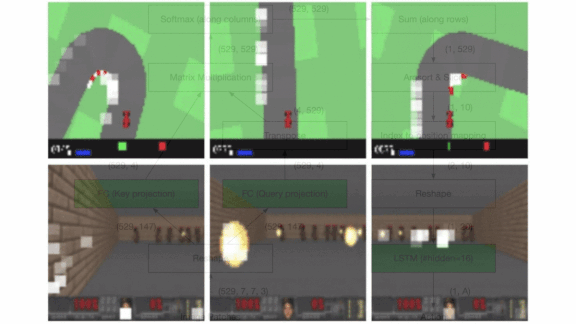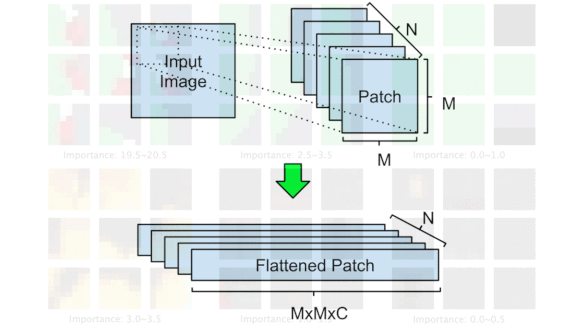
Eyes on the Prize
When the chips are down, humans can track critical details without being distracted by irrelevancies. New research helps reinforcement learning models similarly focus on the most important details.
What’s new: Google’s Yujin Tang, Duong Nguyen, and David Ha developed a reinforcement learning approach that teaches an agent to pay attention only to visual information that helps accomplish a task. This strategy makes it easier to perform similar tasks in new environments.
Key insight: In the previous World Models approach, an agent memorized features when it observed the world and used that knowledge to predict outcomes of future experiences. Memorizing the entire world isn’t necessary because many observable details, such as background color, aren’t helpful when solving a task. Agents should perform better if they block out such details.
How it works: The authors’ approach effectively preprocesses an image before the agent considers it in selecting an action.
- Presented with a new image, the model splits it into small patches. It multiplies each patch’s pixel values by a matrix to transform them into a four-dimensional vector (four being a hyperparameter).
- A self-attention layer, minus the usual feed-forward layer to reduce the number of parameters, ranks each patch’s relevance to the task at hand.
- The rank ordering technique is non-differentiable, so the agent can’t learn which are most relevant through backprop. Instead, the researchers used the covariance matrix adaptation evolution strategy, an evolutionary technique that optimizes a loss function across a large population of models.
- The highest-ranked patches (the user decides how many) feed an LSTM layer, which predicts an action.
Results: The researchers tested their method on the Car Racing and Doom Takeover tasks from OpenAI Gym. On both tasks, it surpassed an OpenAI benchmark that’s nearly optimal.
Why it matters: Providing agents with fewer inputs made it possible to reduce their size, and using an evolutionary technique reduced the number of parameters devoted to self-attention. The researchers needed only 3,700 parameters. World Models, which performed both tasks using relatively few parameters compared to other earlier approaches, required 4.7 million.
We’re thinking: We love AI approaches to car racing, and it looks like this work is braking new ground.