
Why search for “a cotton dress shirt with button-down collar, breast pockets, barrel cuffs, scooped hem, and tortoise shell buttons in grey” when a photo and the words “that shirt, but grey” will do the trick? A new network understands the image-text combo. (This is the second of three papers presented by Amazon at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). We’ll cover the third one next time.)
What’s new: Online stores offer all kinds of clothing, but search engines may suggest items of a different color or style than you want. Visiolinguistic Attention Learning, developed by Yanbei Chen with researchers at Queen Mary University of London and Amazon, hones product searches based on text input from shoppers.
Key insights: If you can create a picture that approximates the ideal product, you can search for similar images. Generating realistic images is hard, but comparing extracted features is much easier.
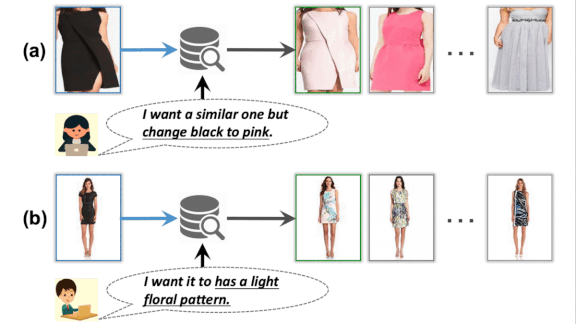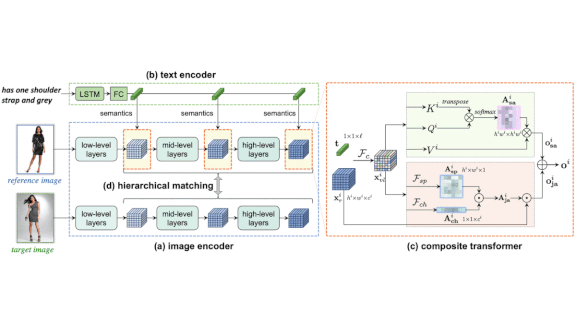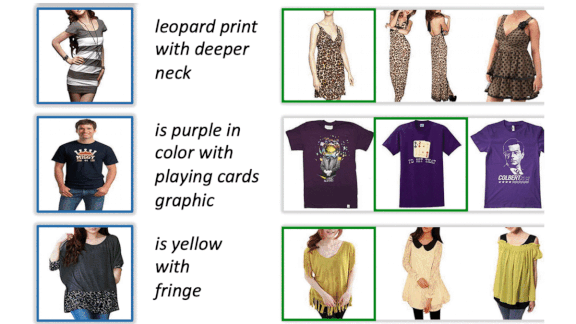
How it works: VAL learns to modify features extracted from a product image according to text input such as “I want it to have a light floral pattern.” Then it searches for other products with features similar to the modified product features.
- VAL learned from datasets that provide an image paired with text as input, and a photo of the corresponding product as output.
- VAL contains a text encoder network and an image encoder network. The image encoder extracts image features at a few levels of detail, for instance shapes and textures.
- A pair of transformers fuses the text and image features at each level of detail.
- One transformer is a variation on self-attention transformers. It identifies relationships between image and text features, and adjusts the image features to agree with the text features.
- The second transformer learns to identify features that are unchanged in the new product and copies them without modification.
- The element-wise sum of both transformers comprises the desired product’s features. VAL compares them with features extracted from product images in its database and returns the closest matches.
Results: The researchers put VAL head-to-head against TIRG, the previous state of the art in image search with text feedback using the Fashion200K dataset of garment photos with text descriptions. VAL achieved 53.8 percent recall of the top 10 recommended products, the fraction of search results that are relevant, compared to TIRG’s 43.7 percent. VAL also outperformed TIRG on the Shoes and FashionIQ datasets.
Why it matters: VAL provides a new method for interpreting images and text together, a useful skill in areas where either one alone is ambiguous.
We’re thinking: We’ll take the blue shirt!