
Getting high accuracy out of a classifier trained on a small number of examples is tricky. You might train the model on several large-scale datasets prior to few-shot training, but what if the few-shot dataset includes novel classes? A new method performs well even in that case.
What’s new: Eleni Triantafillou of Google and Vector Institute, along with colleagues at both organizations, designed Few-shot Learning with a Universal Template (FLUTE).
Key insight: Training some layers on several tasks while training others on only one reduces the number of parameters that need to be trained for a new task. Since fewer parameters need training, the network can achieve better performance with fewer training examples.
How it works: The authors trained a ResNet-18 to classify the eight sets in Meta-Dataset: ImageNet, Omniglot, Aircraft, Birds, Flowers, Quickdraw, Fungi, and Textures. Then they fine-tuned the model on 500 examples and tested it separately on Traffic Signs, MSCOCO , MNIST, CIFAR-10, and CIFAR-100.
- The authors trained the model’s convolutional layers on all training sets. Prior to training on each set, they swapped in new batch normalization layers. These were Feature-wise Linear Modulation (FiLM) layers, which scale and shift their output depending on the dataset the input belongs to. They also swapped in a fresh softmax layer.
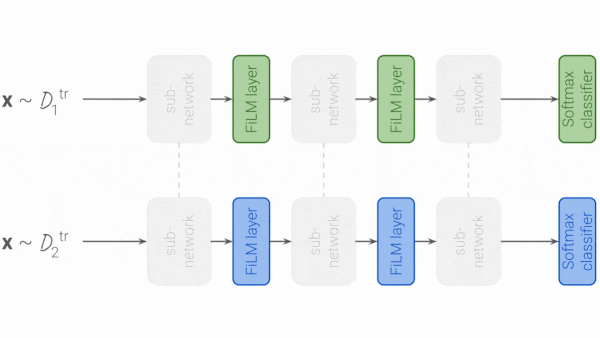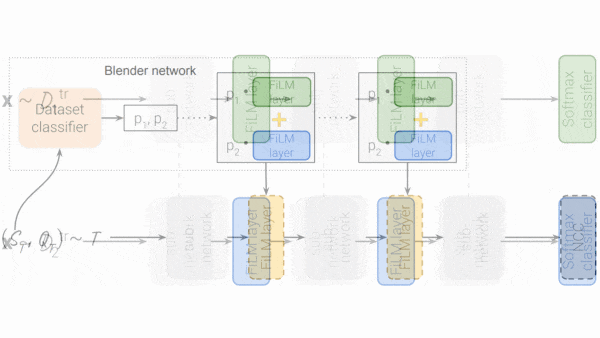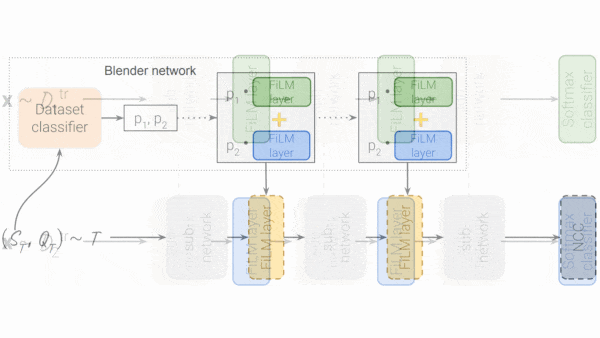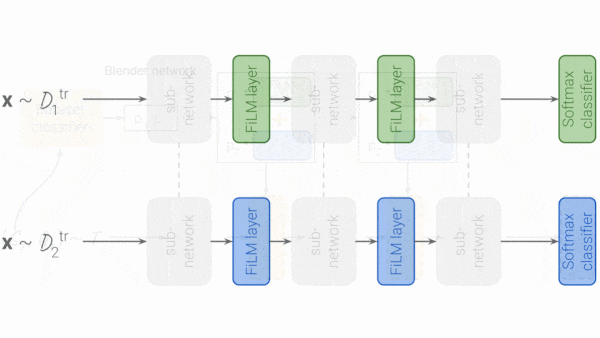
- Prior to fine-tuning on each test set, the authors initialized the FiLM layers as follows: They trained a set encoder to find the training dataset most similar to the test set. A so-called blender network weighted the FiLM layer parameter values according to the set encoder’s output. Then it combined the weighted parameters in all first layers, all second layers, and so on.
- The authors fine-tuned the FiLM layers to minimize nearest-centroid classifier loss: Using up to 100 labeled examples in each class (capped at 500 total), the authors created a centroid for each class, an average of the network’s outputs for all examples in that class. Then, using individual examples, they trained the FiLM layers to minimize the distance between the output and the centroid for the example’s class.
- The model classified test examples by picking the class whose centroid was most similar to the example’s output.
Results: Averaged across the five test sets, FLUTE’s 69.9 percent accuracy exceeded that of other few-shot methods trained on the same datasets. The closest competitor, SimpleCNAPs, achieved 66.8 percent accuracy.
Why it matters: The combination of shared and swappable layers constitutes a template that can be used to build new classifiers when relatively few examples are available.
We’re thinking: We will con-template the possibility of using this approach for tasks beyond image classification.