
To reconstruct the 3D world behind a set of 2D images, machine learning systems usually require a dedicated neural network for each scene. New research enables a single trained network to generate 3D reconstructions of multiple scenes.
What’s new: Adam Kosiorek and Heiko Strathmann led a team at DeepMind in developing NeRF-VAE. Given several 2D views of a 3D scene pictured in its training data, NeRF-VAE produces new views of the scene.
Key insight: The method known as Neural Radiance Fields (NeRF) produces new views of a scene based on existing views and the positions and orientations of the camera that produced them. NeRF-VAE takes the same input but adds representations of those views. This enables it to learn patterns within a scene. Those patterns help the network produce new views by enabling it to, say, infer the characteristics of common elements that were partly blocked from view in the training images.
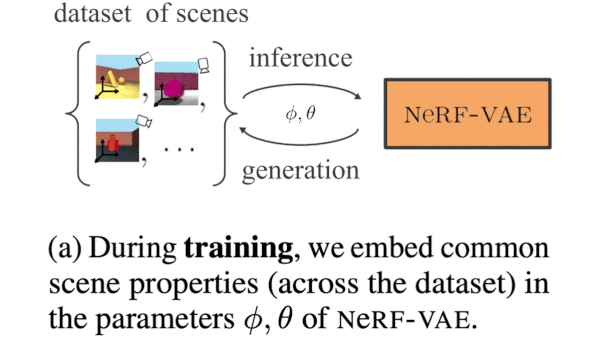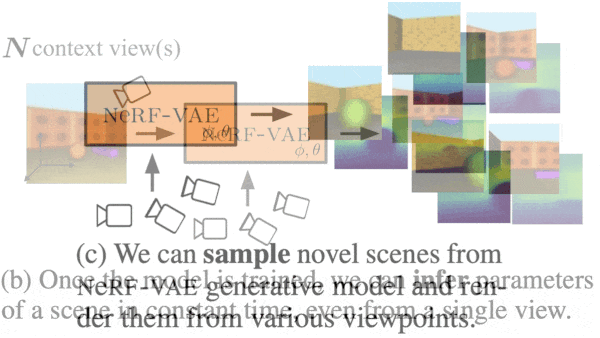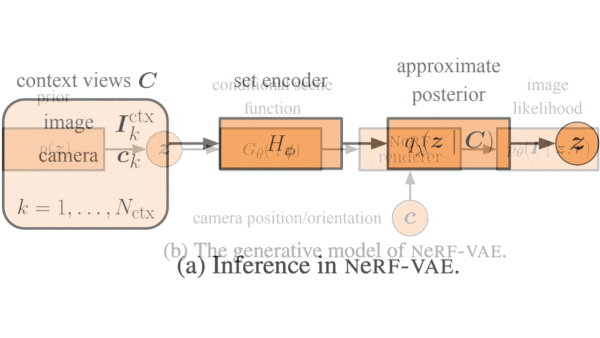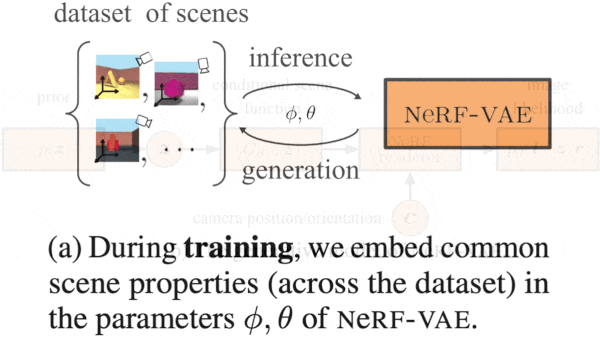
How it works: NeRF-VAE is a modified variational autoencoder (VAE), where the encoder is a Nouveau ResNet and the decoder is basically NeRF with an additional input for a representation of the scene. The training set comprised four randomly generated views per scene of 200,000 synthetic 3D scenes composed of geometric shapes against plain backgrounds, as well as the associated camera positions and orientations. The authors trained the network to match predicted pixels with the pixels in the images.
- For each of the four views of a scene, the encoder predicts parameter values that correspond to the image’s data distribution. The system averages the parameters and uses the average distribution to generate a representation of the scene.
- The decoder samples points along rays that extends from the camera through each pixel in the views. It uses a vanilla neural network to compute the color and transparency of each point based on the point’s position and the ray’s direction as well as the scene representation.
- To determine the color of a given pixel, it combines the color and transparency of all sampled points along the associated ray. To generate a new view, it repeats this process for every pixel.
Results: The authors trained one NeRF-VAE on all scenes and a separate NeRF for each scene. Trained on four images per scene, NeRF-VAE achieved roughly 0.2 mean squared error, while NeRF achieved roughly 0.8 mean squared error. NeRF required training on 100 images of a scene to achieve a competitive degree of error.
Why it matters: NeRF falters when it attempts to visualize hidden regions in a scene. That’s partly because a NeRF model encodes information about only a single 3D structure. NeRF-VAE overcomes this weakness by learning about features that are common to a variety of 3D structures.
We’re thinking: By feeding a random vector directly to the decoder, the authors produced views of novel, generated scenes made up of elements in the training images. Could this approach extend deepfakery into the third dimension?