
Researchers have proposed task-agnostic architectures for image classification tasks and language tasks. New work proposes a single architecture for vision-language tasks.
What’s new: Led by Tanmay Gupta, researchers at the Allen Institute for AI and University of Illinois at Urbana-Champaign designed a general-purpose vision architecture and built a system, GPV-I, that can perform visual question answering, image captioning, object localization, and image classification.
Key insight: Model architectures usually are designed for specific tasks, which implies certain types of output. To classify ImageNet, for instance, you need 1,000 outputs, one for each class. But text can describe both tasks and outputs. Take classification: the task “Describe this image” leads to the output, “this image is a dog.” By generating a representation of text that describes a task, a model can learn to perform a variety of tasks and output text that completes it without task-specific alterations in its architecture.
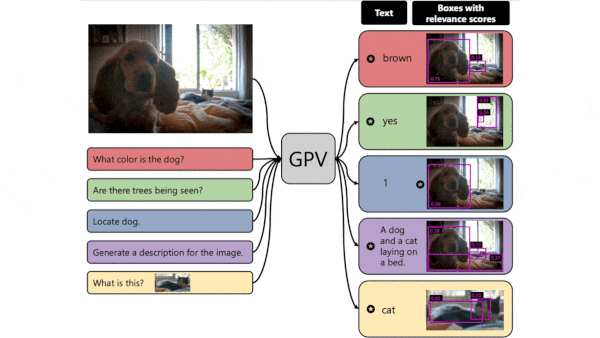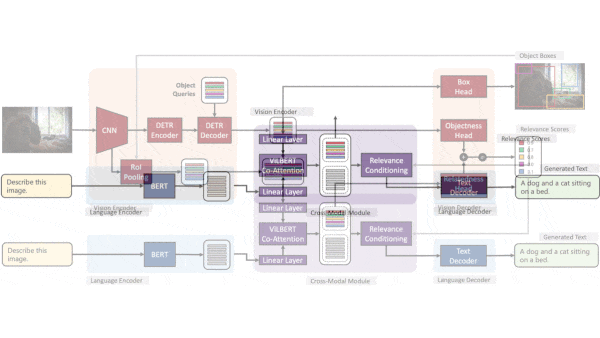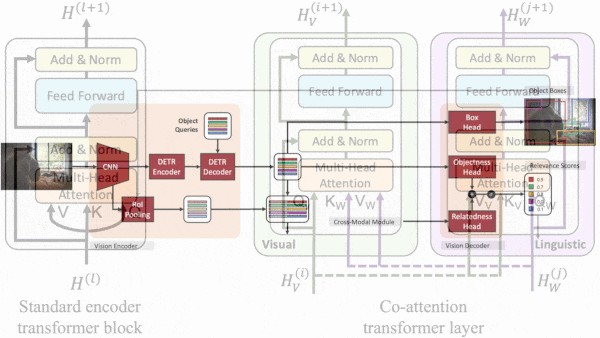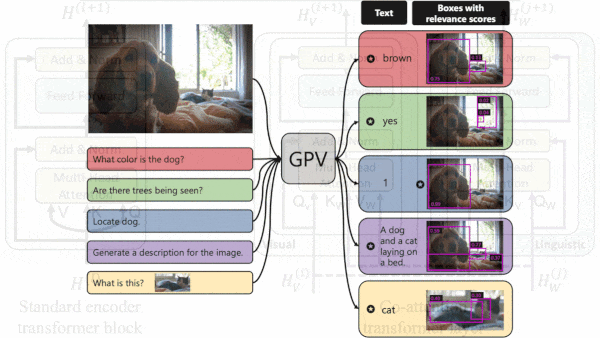
How it works: Given a text description of a task — say, “describe the image” — and an image, GPV-I generates separate representations of the text and image, determines their relative importance to one another, and outputs a relevant text response and a copy of the image with bounding boxes. The authors trained it on COCO image captioning, VQA question answering, and RefCOCO+ object localization datasets.
- The system uses BERT to produce a representation of the task. It extracts an initial image representation using a ResNet-50 and passes it to a transformer borrowed from DETR. The transformer splits the representation into a grid, each cell of which contains a representation for the corresponding location in the image.
- A so-called cross-modal module accepts the representations of the image (one for each grid cell) and text (that is, the task) and produces new ones that reflect their relationship. It uses co-attention between transformer layers to compare image and text representations and a sigmoid layer to compute the relevance of the image representations to the task. Then it weights each image representation by its relevance.
- An image decoder uses the DETR representations to generate a bounding box for each object detected and the relevance scores to select which boxes to draw over the image. The text decoder (a transformer) uses the BERT representations and weighted representations to generate text output.
Results: The researchers evaluated GPV-I on COCO classification, COCO captioning, and VQA question answering. They compared its performance with models trained for those tasks. On classification, GPV-I achieved accuracy of 83.6 percent, while a ResNet-50 achieved 83.3 percent. On captioning, GPV-I achieved 1.023 CIDEr-D — a measure of the similarity of generated and ground-truth captions, higher is better — compared to a VLP’s 0.961 CIDEr-D. On question answering, GPV-I achieved 62.5 percent accuracy compared to ViLBERT’s score of 60.1 percent, based on the output’s similarity to a human answer.
Why it matters: A single architecture that can learn several tasks should be able to share concepts between tasks. For example, a model trained both to detect iguanas in images and to answer questions about other topics might be able to describe what these creatures look like even if they weren’t represented in the question-answering portion of the training data.
We’re thinking: Visual classification, image captioning, and visual questioning answering are a start. We look forward to seeing how this approach performs on more varied tasks.