
A group of media and technology experts is working to give AI a better understanding of indigenous peoples.
What’s new: Intelligent Voices of Wisdom, or IVOW, is a consultancy that aims to reduce machine learning bias against cultures that are underrepresented in training data by producing knowledge graphs and other resources, The New York Times reported.
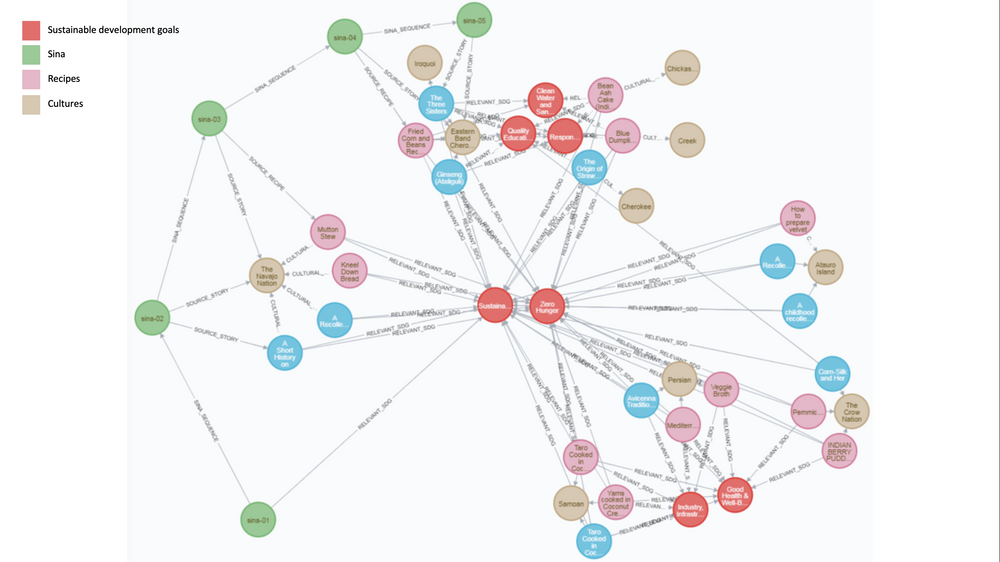
How it works: IVOW has held data-labeling workshops and created a graph of native culinary techniques.
- At a September 2021 workshop, the group invited Native Americans to relabel imagery depicting various scenes and objects relevant to their culture. Participants used words like “sacred” to describe a bundle of ceremonial sage — described as “ice cream” by one image classifier — and appended words like “genocide” and “tragedy” to an image of Navajo children who had been separated from their parents that the classifier labeled “crowd” and “audience.”
- The Indigenous Knowledge Graph uses the Neo4j graphical data system to compile labels and other information. It contains recipes and stories about their origins in Iran, East Timor, Samoa, and several North American peoples.
- Users can query the knowledge graph using a chatbot called Sina Storyteller based on Google’s Dialogflow natural language understanding platform. For instance, a user can ask Sina for a Cherokee recipe, and the chatbot will reply with both a recipe and a scripted story about it.
Behind the news: A number of efforts around the globe are building data and tools for underrepresented languages and, by extension, the people who speak them.
- Masakhane, a community of African researchers, is working to improve machine translation to and from a number of low-resource African languages.
- Researchers in Australia and the United States have developed speech recognition tools trained to recognize and transcribe languages that are in danger of disappearing due to an aging population of speakers.
Why it matters: Some of the most blatant biases embedded in training datasets, particularly those scraped from the web, are well known. Less well understood are biases that arise because some groups are culturally dominant while others are relatively obscure. If AI is to work well for all people, it must be trained on data that reflects the broad range of human experience.
We’re thinking: People have a hard time fully comprehending and respecting cultures that are unfamiliar to them. Perhaps AI trained on datasets that have been curated for their relevance to a wide variety of cultures will help us come closer to this ideal.