
It’s expensive to pay doctors to label medical images, and the relative scarcity of high-quality training examples can make it hard for neural networks to learn features that make for accurate diagnoses. A new method addresses the issue by training a feature extractor on both X-rays and text that accompanies them.
What’s new: Yuhao Zhang and colleagues at Stanford University proposed ConVIRT, a method that uses contrastive learning to learn from unlabeled images paired with corresponding text reports. The effort brought together medical imaging specialist Curt Langlotz and natural language processing luminary Chris Manning (see our Heroes of NLP interview with him here).
Key insight: The text report that accompanies a medical image contains useful information about the image’s contents, and vice-versa. ConVIRT generates features based on similarities between images and corresponding reports, as well as differences between images and unrelated reports.
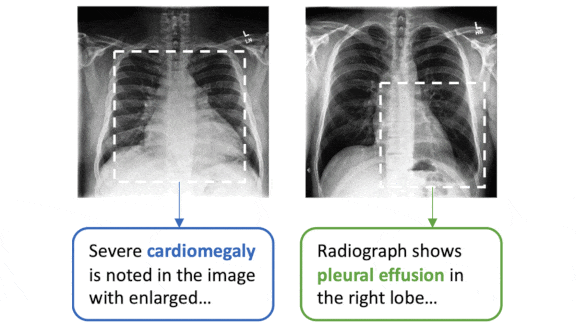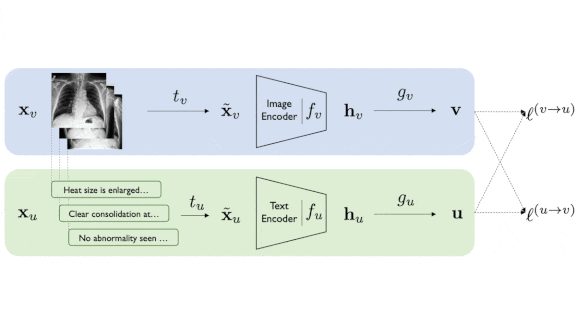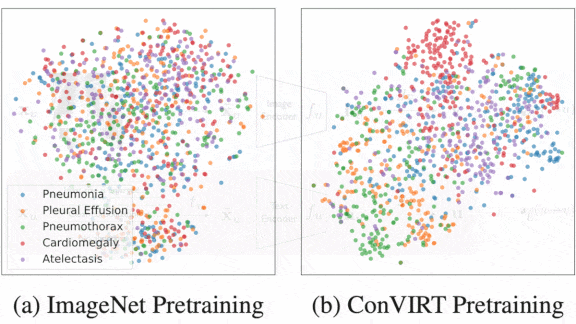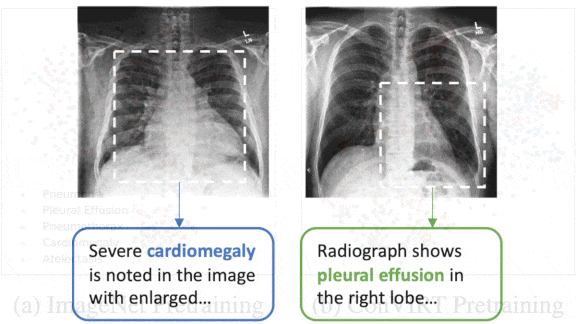
How it works: The authors built separate pipelines for images and text. The image pipeline consisted of a ResNet-50, followed by a neural network with a single hidden layer (to project the image vectors into a consistent space for comparison with the text vectors}. The text pipeline consisted of BERT followed by a similarly shallow network.
- The researchers used two datasets for pretraining: the MIMIC-CXR database of 217,000 chest X-rays and reports and a Rhode Island Hospital dataset of 48,000 musculoskeletal images with reports.
- They pretrained the models on the image-text pairs using a contrastive loss: The image pipeline learned to produce a vector as similar as possible to the corresponding vector produced by the text pipeline, and different from all the other text vectors. The text pipeline learned in a similar way.
- They extracted the ResNet-50 model and fine-tuned it for four image classification tasks, including the RSNA Pneumonia Detection Challenge of diagnosing pneumonia in chest X-rays.M
Results: In all four tasks, ConVIRT outperformed baseline models including a ResNet-50 pretrained on ImageNet and fine-tuned on RSNA and other datasets, and custom models built to generate the paired text from an image. Fine-tuned on 1 percent of the RSNA dataset, ConVIRT achieved 88.8 AUC (area under the receiver operating characteristic curve, higher is better), compared to the ImageNet model (83.1 AUC) and the best custom image-text model (87.7 AUC). Fine-tuned on 10 percent of RSNA, ConVIRT outperformed those models 91.5 AUC to 87.3 AUC and 89.9 AUC respectively.
Why it matters: Pretraining on paired images and text via contrastive learning could help alleviate the high cost of medical data for deep learning.
We’re thinking: For updates on leading-edge AI for medicine, check out the new AI Health Podcast cohosted by Pranav Rajpurkar, instructor of our AI For Medicine Specialization.