
Dear friends,
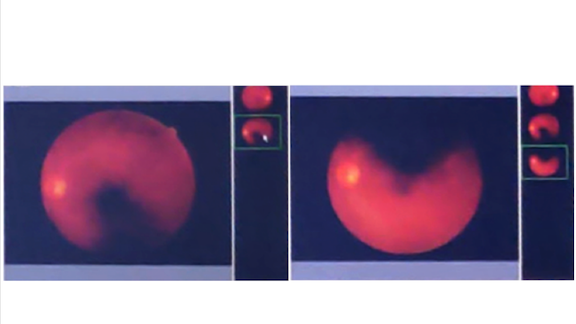
There has been a lot of excitement about the idea of using deep learning to diagnose diabetic retinopathy: That is by taking a photo of the retina and using AI to detect signs of disease. I was fascinated by a new paper by Emma Beede and others that studied the use of Google’s diabetic retinopathy detecting system in 11 clinics in Thailand and found that, despite all the research progress, this technology isn’t working well in production yet.
We as a community need to get much better at bridging proofs of concept (PoCs) and production deployments. Even Google’s excellent AI team ran into many practical issues:
- Images collected in the sometimes poorly-equipped clinics were not of the same uniform high quality as those in the training and test sets used in the original research. For example, in some clinics, pictures were taken with the ceiling lights on, resulting in lower image quality.
- There were unexpected corner cases. For example, the paper describes how a nurse who was unable to take a single, clean image of the retina instead took two partial images and wanted to diagnose from a composite of them.
- Many details relating to the patients’ and clinicians’ workflow still needed to be sorted out. Some patients were dissuaded from using the system because of concerns that its results might require them to immediately go to a hospital — a time consuming and expensive proposition for many. More generally, decisions about when/whether/who/how to refer a patient based on the AI output are consequential and need to be sorted out.
The paper was published by SIGCHI, a leading conference in human-computer interaction (HCI). I’m encouraged to see the HCI community embrace AI and help us with these problems, and I applaud the research team for publishing these insights. I exchanged some emails with the authors, and believe there’s a promising path for AI diagnosis of diabetic retinopathy. To get there, we’ll need to address challenges in robustness, small data, and change management.
Many teams are working to meet these challenges, but no one has perfect answers right now. As AI matures, I hope we can turn building production systems into a systematic engineering discipline, so we can deploy working AI systems as reliably as we can deploy a website today.
Keep learning!
Andrew
Covid-19 Watch
New Machine Learning Resources
This week’s roundup of resources for taking on Covid-19 includes a collection of models, a collaborative molecule hunt, and a search engine query set.
- Coronavirus Query Dataset: The pandemic has spurred the emergence of new datasets that offer novel ways to detect the spread of disease. The Bing Coronavirus Query Set is a notable example: It logs Bing queries from around the world related to coronavirus. Analyzing the patterns of those queries might help point out new places where the disease is spreading. We might also be able to detect re-emergence of the disease in places opening up from lockdown by analyzing the relationship between searches and known coronavirus prevalence.
- Finding Molecules With Machine Learning: AI Cures, a research group at MIT, is devoted to bringing together researchers in computational and life sciences to find antiviral molecules that can combat Covid-19. They have open-sourced a number of datasets for specific tasks, such as finding effective antibodies against secondary infections, and are asking for modeling submissions from the AI community. Browse their open tasks, download the data, upload your best model; your code may help researchers find a life-saving treatment.
- Finally, One Place for Models: With so many Covid-19 forecasting models out there, it can be hard to keep them straight. FiveThirtyEight, a data-driven news organization, has released a new tool that compares six of the most reputable models side by side and explains the differences in their predictions and assumptions. The models’ forecasts are updated every week along with actual coronavirus data, showing how the models fared in the past — and hopefully leading to a better understanding of the future.
News
Roll Over, Beyoncé
A new generative model croons like Elvis and raps like Eminem. It might even make you think you’re listening to a lost demo by the Beatles.
What’s new: OpenAI released Jukebox, a deep learning system that has generated thousands of songs in styles from country to metal and soul. It even mimics the voices of greats like Frank Sinatra.
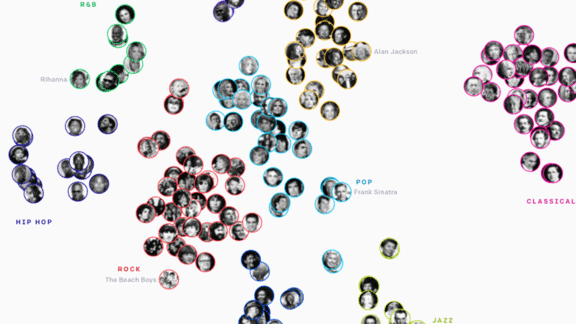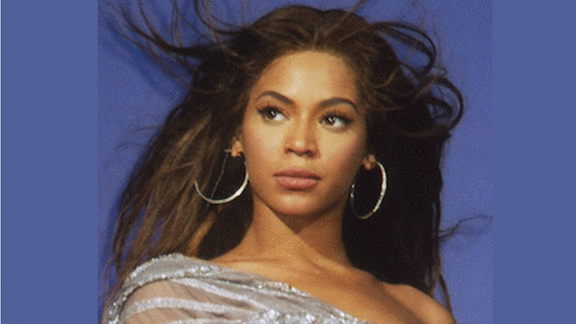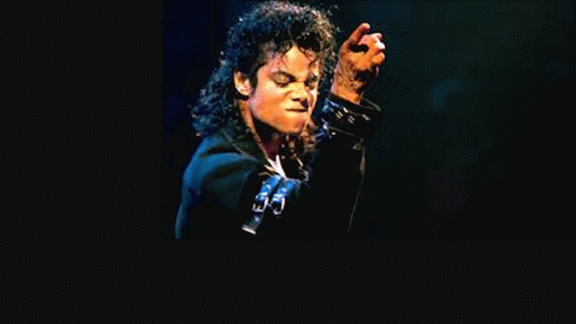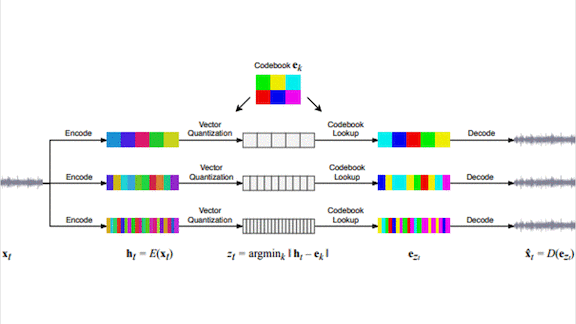
How it works: Jukebox generates music by drawing from a database of 1.2 million songs. Where some other AI-powered systems use symbolic generators to create tunes, Jukebox uses audio recordings, which capture more of music’s subtleties.
- In working with raw audio, the biggest bottleneck is its sheer size and complexity, the authors write. They used vector quantized variational autoencoders, or VQ-VAEs, to compress the training set to a lower-dimensional space. Then they trained the model to generate audio in this compressed space. Transformers create successively higher-resolution versions of a new song. Finally, a decoder turns that output into audio.
- The researchers paired each song with metadata including its artist, lyrics, and genre. That helps guide the model as it generates made-to-order music in any designated style.
- The model made cohesive music, but it struggled to produce coherent lyrics. To overcome this, researchers added existing lyrics into the conditioning information. It also had a hard time associating chunks of words with musically appropriate passages, so the researchers used open source tools to manually align words with the music windows in which they appear.
- The model requires upward of nine hours of processing to render one minute of audio.
Results: OpenAI released over 7,000 songs composed by Jukebox. Many have poor audio quality and garbled lyrics, but there are more than a few gems. Have a listen — our favorites include the Sinatra-esque “Hot Tub Christmas,” with lyrics co-written by OpenAI engineers and a natural language model, and a country-fied ode to deep learning.
Behind the news: AI engineers have been synthesizing music for some time, but lately the results have been sounding a lot more like human compositions and performances.
- In 2016, Sony’s Flow Machine, trained on 13,000 pieces of sheet music, composed a pop song reminiscent of Revolver-era Beatles.
- The production company AIVA sells AI-generated background music for video games, patriotic infomercials, and tech company keynotes.
- Last April, OpenAI released MuseNet, a music generator that predicts a sequence of notes in response to a cue.
Why it matters: Jukebox’s ability to match lyrics and voices to the music it generates can be uncanny. It could herald a new way for human musicians to produce new work. As a percentage of all music consumed, computer generated music is poised to grow.
We’re thinking: Human artists already produce a huge volume of music — more than any one person can listen to. But we’re particularly excited about the opportunity for customization. What if you could have robo-Beyonce sing a customized tune for your home movie, or robo-Elton John sing you a song celebrating your birthday?

Fake Detector
AI’s ability to produce synthetic pictures that fool humans into believing they’re real has spurred a race to build neural networks that can tell the difference. Recent research achieved encouraging results.
What’s new: Sheng-Yu Wang and Oliver Wang teamed up researchers from UC Berkeley and Adobe to demonstrate that a typical discriminator — the component in a particular generative adversarial network (GAN) that judges the output to be real or synthetic — can recognize fakes generated by a variety of image generators.
Key insight: The researchers trained the discriminator on a dataset made up of images created by diverse GANs. Even two training examples from an unrelated generator improved the discriminator’s ability to recognize fake images.
How it works: The researchers compared the performance of ProGAN’s discriminator when trained on Pro-GAN output and on their own dataset.
- The training set comprised 18,000 real images and 18,000 Pro-GAN images from the 20 object categories in the LSUN dataset, along with augmented versions of those images. The validation set consisted of 100 real and synthetic images per category. The researchers created the Foresynth test dataset that consists of real and synthetic images from 11 GANs.
- Blur and compression were applied to the training data, though the testing wasn’t performed on augmented images.
- Augmentation improved performance on the whole, though some GANs evaded detection better than others.
Results: ProGAN’s discriminator distinguished real from fake images 80 percent of the time. Accuracy rose to 82.3 percent by adding two training examples from another generator (and allowing the discriminator to adjust its confidence threshold) and 88.6 percent with many examples. The researchers also compared real images used to train the generators with 2,000 fake images from each one. They found no discernible pattern in a frequency representation of real images and distinctive patterns in the output of all generators. These subtle patterns, they conjecture, enabled the discriminator to generalize to the output of unrelated generators.
Yes, but: The authors’ approach to detecting fake images does a fairly good job of spotting run-of-the-mill GAN output. But a determined malefactor could use only generated images that evaded their method.
Why it matters: Prior research didn’t envision that a single discriminator could learn to recognize fakes from diverse, unrelated generators. Current generators apparently leave common traces — a hopeful prospect for developing more capable fake detectors. Of course, that could change tomorrow.
We’re thinking: Your move, fakers.
Triage for Pandemic Patients
Israeli and American hospitals are using an algorithm to flag individuals at high risk for Covid-19 complications.
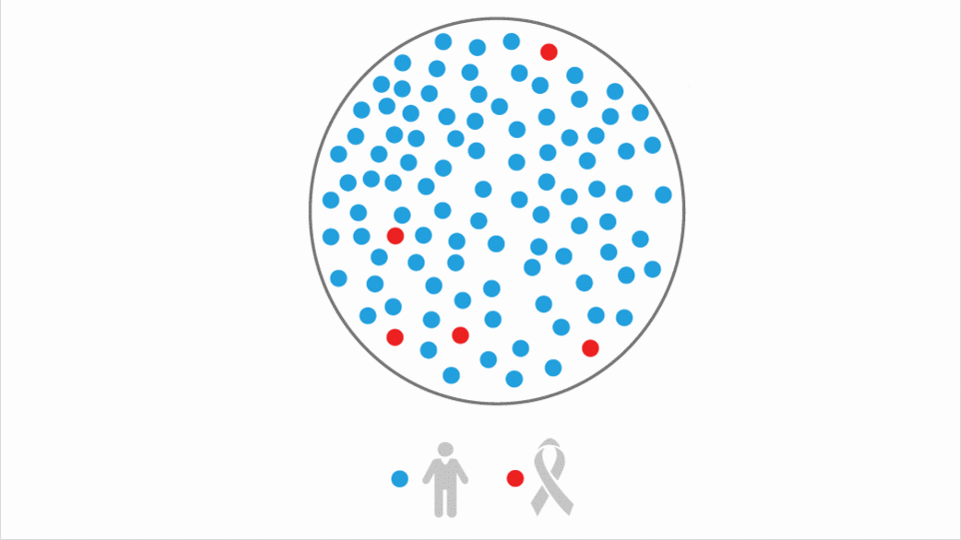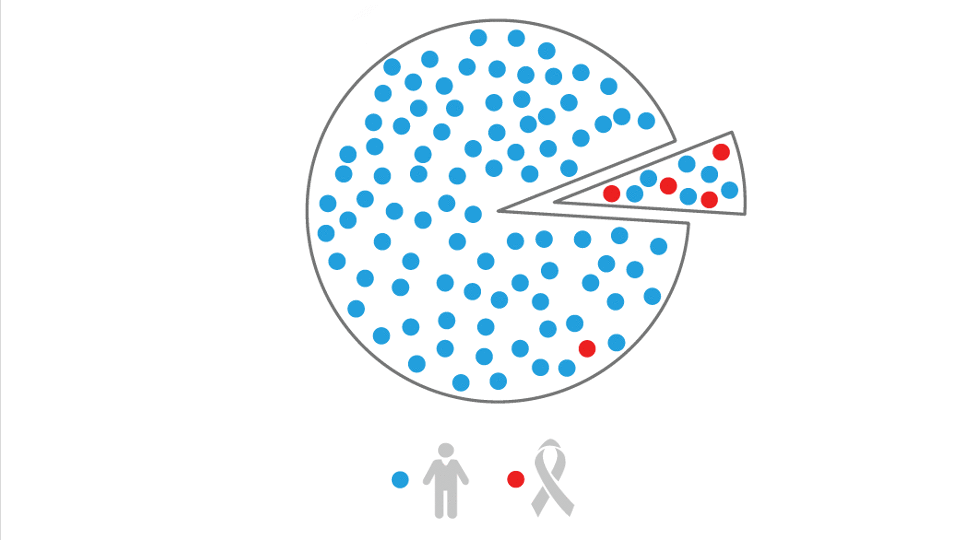
What’s new: Israel’s Maccabi Healthcare Services and U.S.-based Kaiser Permanente are using a model dubbed Covid Complications AlgoMarker to identify patients likely to be hospitalized, develop complications, or die from Covid-19. The developer, Medial EarlySign, is offering it for free to other health systems.
How it works: The model analyzes the electronic medical records of patients in a given health system. It assigns each one a score that indicates their level of risk based on demographics, hospital admission history, prescribed medications, whether they have respiratory and cardiac diseases, and other factors. If a high-scoring patient tests positive for Covid-19, physicians have early warning that they need to take extra care to prevent or manage complications.
- Covid AlgoMarker is based on an earlier Medial EarlySign product that measures a person’s risk of developing flu complications.
- The flu model was trained using 10 years of electronic medical records from 600,000 patients of Kaiser Permanente, Maccabi Healthcare Services, and the Texas Health Information Network. It was validated using 2 million records covering six years.
- The developer tweaked the flu model’s parameters to align with research on risk factors for Covid-19 complications. The most important, an EarlySign spokesperson told The Batch, are a person’s age and sex: Covid-19 hits males and elders hardest.
- The adapted model was verified on a dataset of 5,000 Covid-19 patients. It flagged those with the highest risk of developing Covid-19 complications with 87 percent accuracy.
Fast Track: The model identified about 40,000 members as high risk and put them on the fast track for testing. If they test positive, doctors will use their risk scores to help determine whether they should be hospitalized, quarantined, or sent home. EarlySign will continue to retrain the model as more data comes in.
Yes, but: Privacy laws like the EU’s General Data Protection Regulation make it difficult to roll out a system like this, which would work best if allowed to automatically scan a massive number of patients’ health records. Another obstacle: Many healthcare systems in the U.S. and elsewhere use older computer systems that don’t integrate well with newer systems.
Why it matters: With no end to the pandemic in sight, AI that helps hospitals triage patients efficiently can help save lives.
We’re thinking: Although the privacy, data aggregation, and data cleaning issues are formidable, systems like this might help us figure out who to allow back to work, who to keep at home, and who needs special care.
A MESSAGE FROM DEEPLEARNING.AI
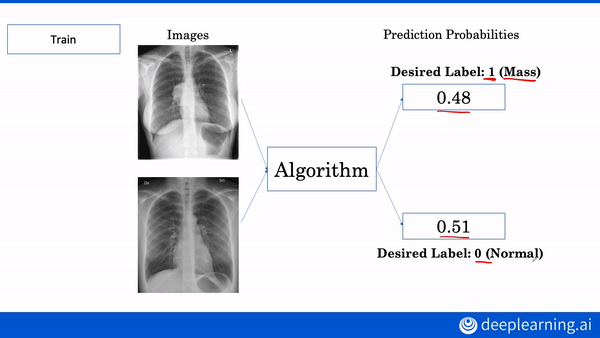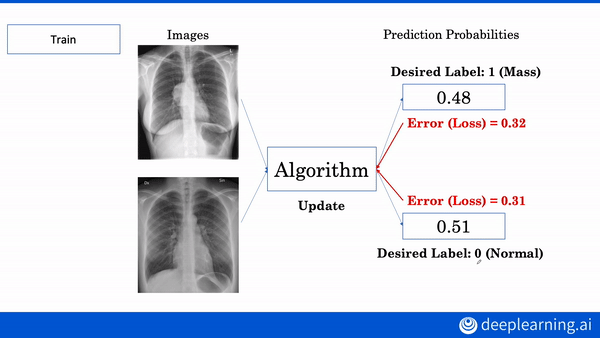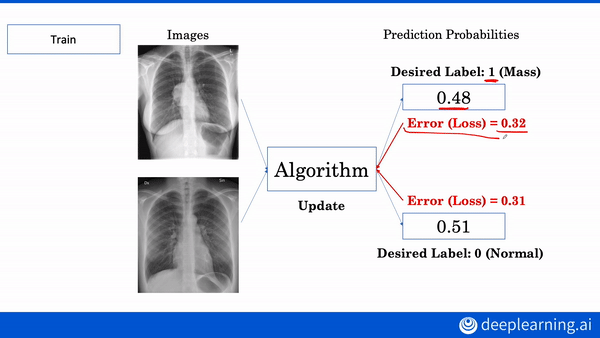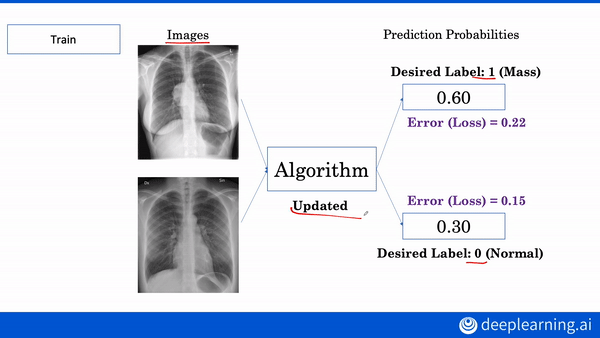
Build a machine learning algorithm to diagnose chest x-rays and 3D MRI brain images. Enroll in the AI for Medicine Specialization.

Seeing Sea Plastic
A machine learning model is scanning the oceans for the glint of garbage.
What’s new: Researchers from the UK’s Plymouth Marine Laboratory trained a model to identify ocean-borne refuse.
How it works: The European Space Agency’s two Sentinel-2 satellites capture light that reflects off the Earth’s surface. The algorithm examines this imagery, pixel by pixel, for evidence of plastic.
- Every sort of object reflects light differently, especially in spectral bands beyond the colors visible to humans. Plastic throws off a distinct signature in the near-infrared zone.
- The researchers trained a naive Bayes model on different “spectral signatures” — patterns of light that result when it bounces off plastic, sea water, and debris like driftwood, foam, and seaweed.
- They validated the model using satellite imagery from offshore regions where various types of debris was known to accumulate, including imagery from a previous experiment in which researchers dumped flotillas of plastic off the coast of Greece.
Results: The team tested the model on imagery of coastal sites in western Canada, Ghana, Vietnam, and Scotland. It averaged 86 percent accuracy.
Behind the news: Marine scientists are finding a variety of uses for AI in ocean conservation. For instance, Google built a neural network that recognizes humpback whale songs using data from the U.S. National Oceanic and Atmospheric Administration. Researchers use the model to follow migrations.
Why it matters: Fish and whales often die from ingesting or getting tangled in pieces of plastic. As the material breaks down into tiny fragments, it gets eaten by smaller organisms, which get eaten by larger organisms, including fish consumed by humans, with potentially toxic effects.
We’re thinking: Pointing this model at the beach might be even more helpful: Most ocean plastic originates on land, so coastlines may be the best places to capture it before it enters the food web.
RL and Feature Extraction Combined
Which comes first, training a reinforcement learning model or extracting high-quality features? New work avoids this chicken-or-egg dilemma by doing both simultaneously.
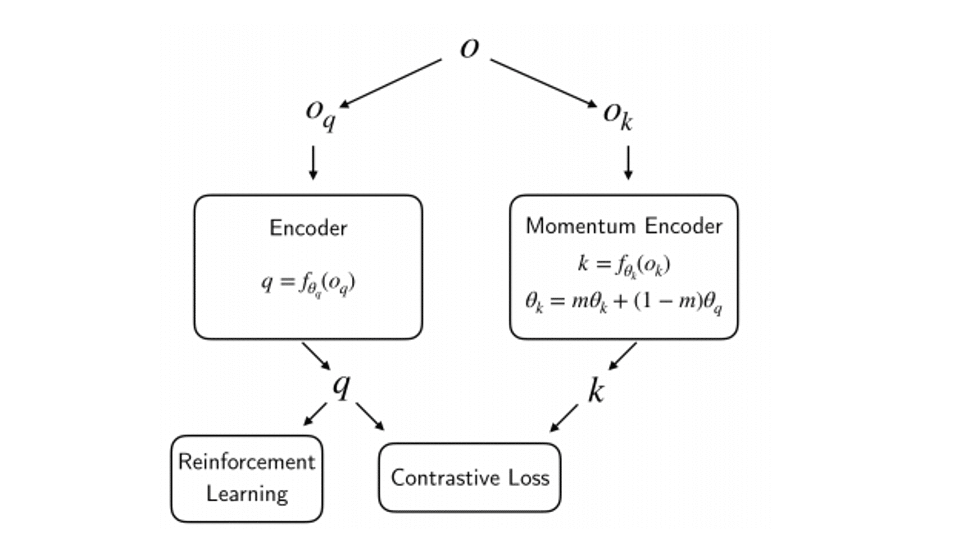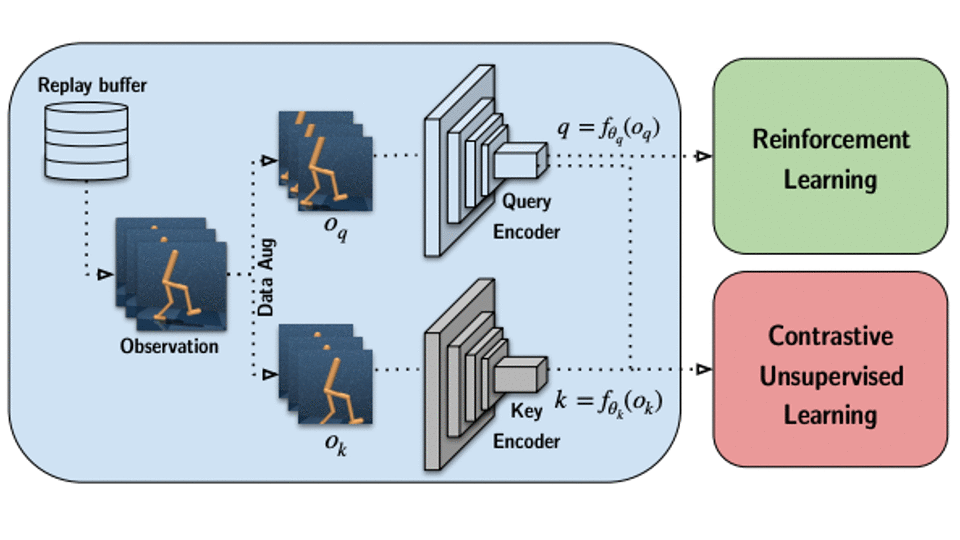
What’s new: Aravind Srinivas and Michael Laskin at UC Berkeley offer Contrastive Unsupervised Representations for Reinforcement Learning (CURL). The authors propose contrastive learning to extract features during RL.
Key insight: In many RL scenarios, the model learns by interacting with its environment. To extract features, it must capture training data while learning, so pre-trained feature extractors don’t generalize well to novel situations. Contrastive learning, which has been successfully applied to self-supervised learning, extracts similar features for similar inputs and dissimilar features for dissimilar inputs. This doesn’t require pre-training, so the researchers figured that reinforcement and contrastive learning could go hand-in-hand.
How it works: The authors essentially combined an RL agent of the user’s choice with a high-performance contrastive learning model that draws techniques from SimCLR, MoCo, and CPC. The two learn independently.
- The RL agent observes multiple images in sequence.
- The contrastive learning model applies two data augmentations to the observations, for instance a pair of random crops.
- CURL learns to extract similar feature vectors from each version.
- The RL agent learns from the extracted features.
Results: The researchers tested CURL with Rainbow DQN in 42 tasks. They compared its performance against state-of-the-art pixel-based models with similar amounts of training. CURL collected rewards an average 2.8 times larger in DMControl and 1.6 times larger in Atari games. It achieved this performance in DMControl in half the training steps.
Why it matters: A typical solution to the chicken-or-egg problem is to collect enough data so that it doesn’t matter whether RL or feature extraction comes first. CURL cuts the data requirement.
We’re thinking: We’ve been excited about self-supervised learning for some time and are glad to see these techniques being applied to speed up RL as well.
Asia’s AI Advantage
Asian companies lead the world in AI deployment, new research argues.
What’s new: Market research by MIT Technology Review Insights found that companies in the Asia-Pacific region are using machine learning faster and with better results than any other part of the world.
What they found: The authors interviewed over 1,000 executives and directors from businesses in a range of economic sectors around the globe. Roughly one-fifth work for companies in the Asia-Pacific region.
- Ninety-six percent of the Asian executives interviewed said their companies were using AI, compared to 85 percent in the rest of the world. Both numbers have increased sharply since 2017.
- Asian companies appear to be getting the most benefit from the technology, too. Forty-six percent of Asia-Pacific executives reported that their AI investments were exceeding expectations, as opposed to 37 percent of executives elsewhere.
- Their businesses are using AI mostly to manage information technology, improve customer service, and conduct research and development.
- Use of AI in sales and marketing is on the rise. While a third of Asian respondents have deployed models in these areas, 61 percent plan to by 2023. E-commerce sales driven by Covid-19, the authors say, will add momentum to AI-powered online customer service.
Data-driven growth: Nearly half of Asian executives surveyed said their companies’ AI ambitions were hindered by a lack of access to high-quality data. Most said that better legal protections and industry standards regarding data privacy and security would make them more willing to share datasets with other companies. Third-party data-sharing platforms like Singapore’s nonprofit Ocean Protocol could be part of the solution, the authors write.
Behind the news: Several Asia-Pacific governments have provided major support for IT infrastructure.
- South Korea committed $4 billion last summer toward research and development including AI.
- Singapore provides worthy startups with accreditation that helps attract investors.
- In 2017, China released a national AI plan that includes a $2 billion R&D center near Beijing.
Why it matters: The survey shows that AI is thriving in places where the government provides both regulatory clarity and institutional support.
We’re thinking: Every country should develop policies to foster AI development or risk getting left behind.