
Dear friends,
Recently I wrote about major reasons why AI projects fail, such as small data, robustness, and change management. Given that some AI systems don't work, users and customers sometimes rightly wonder whether they should trust an AI system.
How can we persuade people to trust an algorithm? Some important techniques are:
- Explainability. If an AI can explain its decisions, this helps to build trust or identify problems before they can impinge on trust. For instance, the New York State Department of Financial Services is investigating whether the Apple/Goldman Sachs credit card exhibits gender bias in setting credit limits. If the algorithm could explain its decisions, we could determine whether such bias was driving them.
- Testing. Many of us are willing to take medicinal drugs whose biochemical effects no one fully understands. We trust these drugs because they have passed randomized clinical trials and received FDA approval. Similarly, black-box AI algorithms might gain our trust by undergoing rigorous testing.
- Boundary conditions. Clearly specifying boundary conditions (where the AI is expected to work) also helps. For instance, machine learning engineers developing systems to read medical images may specify the allowable range of inputs (for instance, X-rays must be this bright, and with a certain resolution) and so we can test against these conditions.

- Gradual rollout. Rather than having AI make fully automated decisions on Day One, we can start by allowing it merely to assist humans. For example, an AI trained to read X-rays might assist radiologists in making diagnoses rather than replacing doctors outright. Over time, having collected enough data and improved image readers sufficiently, we would come to trust higher and higher levels of automation, perhaps even full automation.
- Auditing. Third-party audits would build trust that our algorithms have minimal or no gender, race, or other bias, and that they meet certain performance standards.
- Monitors and alarms. Even after deploying a system, we can make sure we receive alerts if something goes wrong. By designing mechanisms that escalate serious issues, we can ensure that problems are fixed in a timely way.
Trust isn’t just about convincing others that our solution works. I use techniques like these because I find it at least as important to convince myself that a solution works, before I ask a customer to rely on it.
Keep learning!
Andrew
News

Solar Power Heats Up
Solar-thermal power plants concentrate the sun’s energy using huge arrays of mirrors. AI is helping those arrays stay in focus.
What happened: Heliogen, a solar-thermal startup, developed a computer vision setup that tracks hundreds of mirrors at once. The system detects reflectors that go off kilter and adjusts them to concentrate sunlight. The system recently heated a boiler to 1,000 degrees Celsius, a temperature that allows for industrial processes. Serial entrepreneur and Heliogen founder Bill T. Gross delivers his pitch in this video.
How it works: A solar-thermal plant's central feature is a tower topped by a boiler. Hundreds, sometimes thousands, of mirrors encircle the tower. By focusing heat on the boiler, they produce steam, which spins a turbine, generating electricity. However, factors like wind, ground subsidence, and natural warping can cause mirrors to drift out of focus, reducing the plant’s efficiency. Heliogen's system calibrates them automatically.
- Heliogen’s tower contains a plate designed to conduct heat for use in industrial processes like smelting steel and making concrete.
- Four cameras around the plate monitor the corners of each mirror. If light reflected by a corner is brighter than the center, the system sends a message to servo controllers to adjust the mirror accordingly.
Why it matters: 1,000 degrees Celsius is a milestone; most solar-thermal plants reach half that temperature. But the company’s goal is 1,500 degrees. At this temperature, it’s possible to split atmospheric carbon dioxide and water into their constituent molecules of hydrogen and carbon. Heliogen aims to start by producing hydrogen to generate power via fuel cells. Ultimately, it aims to recombine hydrogen and carbon into hydrocarbon fuels — no fossils required.
Yes, but: A two-part critique published by the news website CleanTechnica points out that Heliogen’s technology produces a hot spot high above ground, where the heat isn’t immediately useful and is difficult to transport. Moreover, industrial facilities would need to be very nearby, potentially casting shadows over the mirrors. “I think it’s more likely that Heliogen's core machine learning innovation regarding halo focusing will find a completely different niche outside of concentrated solar,” the author concludes.
We’re thinking: Heliogen has intriguing technology, a seasoned leader, and a high-profile backer in Bill Gates. It's exciting to see AI helping to make cheaper, cleaner alternatives to highly polluting industrial processes.
Bias Fighter
Sophisticated models trained on biased data can learn discriminatory patterns, which leads to skewed decisions. A new solution aims to prevent neural networks from making decisions based on common biases.
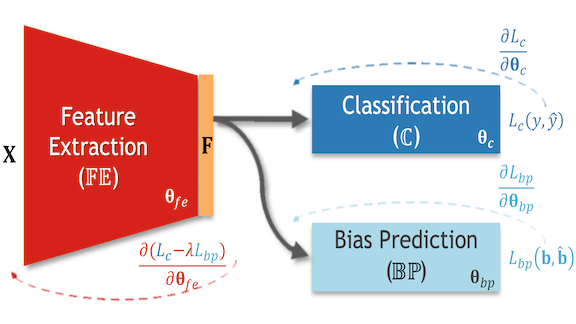
What’s new: Ehsan Adeli and a group at Stanford propose Bias-Resilient Neural Network, or BR-Net, an architecture that works with a classifier to minimize the impact of biases that are well understood. In the training data, we can label, say, race and gender (known as bias variables), and BR-Net will learn to prevent spurious correlations between those variables and the model's output classification.
Key insight: Biases in data correlate with class labels. If one part of a network learns to predict this correlation, another can learn to minimize the predicted correlation. This adversarial scheme can mitigate bias.
How it works: BR-Net comprises three neural networks. The feature extractor finds embeddings of input data. The classifier predicts class labels from the embeddings. The bias predictor predicts the correlation between embeddings and bias variables. Once labels for bias variables have been added to the data, training proceeds in three steps:
- First, the system maximizes classification accuracy: The feature extractor and classifier together learn to predict labels.
- Then it identifies the effects of bias variables: The bias predictor learns the correlation between embeddings and bias variables.
- Finally, it minimizes the influence of bias: The feature extractor learns to generate embeddings that don’t correlate with the bias variables’ labels.
- By iterating through these steps, the feature extractor generates embeddings that maximize the classifier’s performance and minimize the biased correlation between embeddings and labels.
Results: The researchers used a VGG16 classifier with BR-Net to predict a person’s gender from a photo. They trained the model on the GS-PPB dataset. Because classifiers often perform poorly on darker faces, they labeled skin tone as a bias variable. BR-Net achieved 96.1 percent balanced accuracy (accuracy for each of six skin tones considered equally), an improvement of 2 percent. This indicates more consistent results across different skin colors than a VGG16 trained without BR-Net.
Why it matters: Bias in AI is insidious and difficult to prevent. BR-Net offers a solution when sources of bias are known.
We're thinking: Machine learning presents hard questions to society: Which biases should we avoid? How can we come to agreement about which to avoid? Who gets to decide in the end? In lieu of answers, the choices are in the hands of ML engineers.

Prehistoric Pictures Rediscovered
Image analysis guided by AI revealed a 2,000-year-old picture dug into the Peruvian desert.
What happened: Researchers analyzing aerial imagery shot over Peru found a pattern that looks like a three-horned humanoid holding a staff. The figure is roughly 16 feet across and may have served as a waypoint along an ancient path. Known as geoglyphs, such pictures were created by people who predated the arrival of Columbus by 1500 years. The sprawling patterns are visible only from higher elevations.
How it works: Using manual methods, researchers at Yamagata University found more than 100 geoglyphs in satellite photos and other imagery from the region of southeastern Peru called the Nazca Pampa. But they had collected too much data from surrounding areas to search manually. So they teamed with IBM Japan to feed the data into PAIRS Geoscope, a cloud-based deep learning system that analyzes geospatial data. This video describes the project.
- Training Geoscope to find the images presented several challenges. The geoglyphs range in size from tens of feet to nearly a quarter-mile across. They depict birds, humans, reptiles, and abstract shapes. Some are drawn in thin lines, others are filled-in shapes. The system had to learn not to be fooled by river beds and roads, which can trace superficially similar shapes.
- The team trained the system on photos, lidar, and GIS data describing confirmed geoglyphs.
- The model selected more than 500 candidates within a three-square-mile test range. The team reviewed the candidates manually. They chose the most promising one and confirmed it in the field.
Behind the news: The people who created the Nazca geoglyphs lived on the arid Peruvian plains, or pampas. They made these shapes by removing the top layer of pebbles to expose lighter-colored clay roughly six inches below. Conquistadors noted the geoglyphs in their travelogues as far back as the 1500s, but it wasn’t until the 1940s that researchers began studying their origin and purpose.
Why it matters: Remote sensing techniques have spurred a renaissance in archaeology. They’ve helped uncover Mayan pyramids on Mexico’s Yucatan peninsula and abandoned cities in the Cambodian jungle.
We’re thinking: Who wants to team with us to create a massive deeplearning.ai geoglyph to confuse and amuse future generations?
A MESSAGE FROM DEEPLEARNING.AI
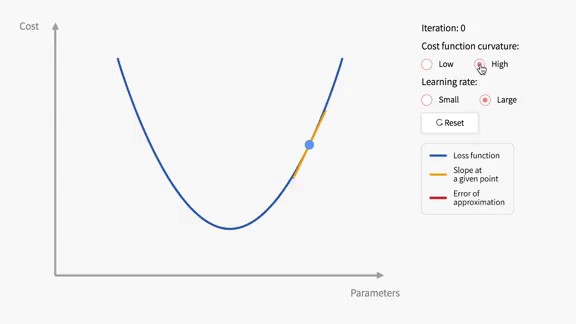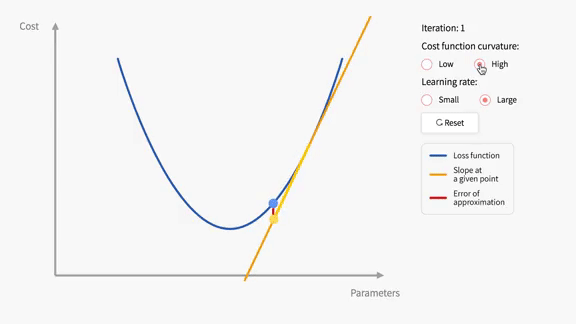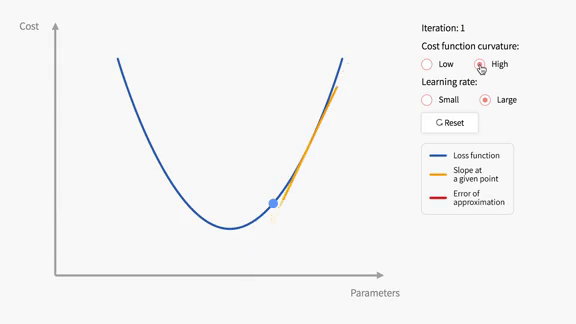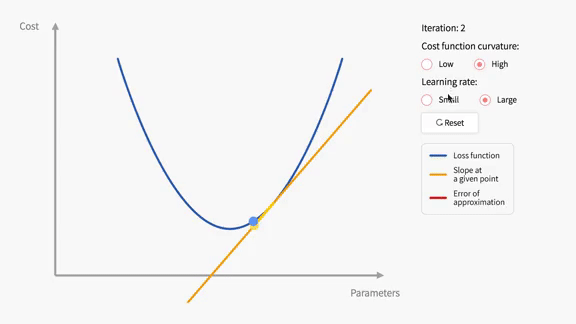
Discover the impact of the learning rate on parameter optimization in Course 2 of the Deep Learning Specialization. Enroll now
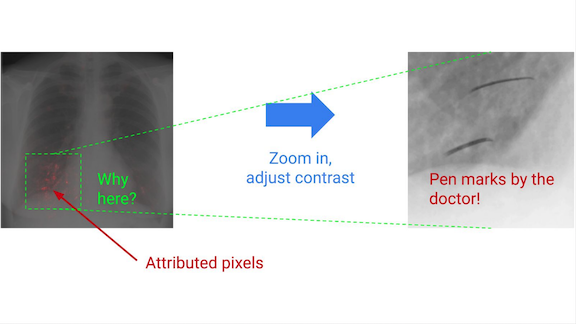
Google's AI Explains Itself
Google's AI platform offers a view into the mind of its machines.
What’s new: Explainable AI (xAI) tools show which features exerted the most influence on a model’s decision, so users can evaluate model performance and potentially mitigate biased results.
How it works: xAI is available to users of Google's Cloud AI platform and its AutoML models and APIs. The core of xAI is a pair of tools that provide graphs or heat maps (depending on the type of data) that show the relative importance of each attribute in a model’s prediction.
- The tool called Integrated Gradients is for neural networks and other models whose attributes are mathematically differentiated. It assigns each feature a Shapley value (a concept borrowed from game theory that measures how important each player is in a cooperative outcome) that grades its role in the predicted outcome. It’s appropriate for most neural nets, according to Google.
- Many ensemble neural nets and trees have non-differentiable attributes. The tool called Sample Shapley explains such cases. It grades each attribute after sampling permutations duplicated across the nets in an ensemble.
- Google Cloud AI also offers free access to its What-If tool, which compares the performance of two models on the same dataset.
Why it matters: The ability to explain how AI models arrive at decisions is becoming a major issue as the technology reaches into high-stakes aspects of life like medicine, finance, and transportation. For instance, self-driving cars would fit more easily into existing regulatory and insurance regimes if they could explain their actions in case of an accident.
Yes, but: Explainability techniques are not a silver bullet when it comes to mitigating bias.
- In an analysis of Google’s tools, Towards Data Science argues that, given the subtlety of hidden correlations that can lurk in datasets, xAI is too superficial to offer meaningful insight into bias, especially in ensemble neural networks. The industry as a whole would be better off formulating standards to ensure that datasets are as unbiased as possible, writes Tirthajyoti Sarkar, who leads machine learning projects at ON Semiconductor.
- Google itself acknowledges xAI’s limitations. A white paper details the many ways in which human bias can impinge on techniques that aim to explain AI decisions. For example, human analysts might disregard explanations highlighting attributes that trigger their own biases.
We’re thinking: As machine learning engineers, we need ways to make sure our models are making good decisions. But we should also keep in mind that explainability has limits. After all, human decisions aren’t always explainable either.
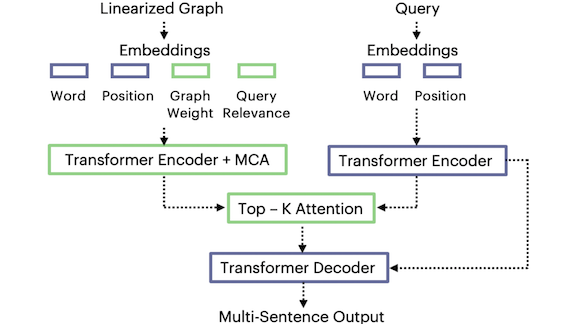
Bigger Corpora, Better Answers
Models that summarize documents and answer questions work pretty well with limited source material, but they can slip into incoherence when they draw from a sizeable corpus. Recent work by Facebook AI Research and Université de Lorraine’s computer science research lab addresses this problem.
What’s new: Angela Fan and collaborators developed a model for multi-document summarization and question answering. While most previous efforts combine all input documents into one, the authors improved the state of t he art by representing them in a more compact form.
Key insight: The combined length of major source documents pertaining to a given topic overwhelms current language models' ability to extract meaning. A knowledge graph squeezes out irrelevant and redundant information, enabling models to work more effectively.
How it works: The authors’ method involves three steps: constructing a knowledge graph from source documents, encoding the graph as a sequence of words, and extracting information from the sequence.
- The model reads a set of source documents and converts each sentence into a (subject, object, relationship) triplet. It transforms each triplet into two nodes corresponding to the subject and object plus an edge between them that represents their relationship. Nodes and edges also capture the number of times a given subject, object, or relationship appears, reducing redundancy.
- For each word, a word embedding encodes meaning and a position embedding encodes relative position. A graph-weight embedding captures the number of times a node or edge appears and a query-relevance embedding reflects a given source document’s relevance to the latest input query. These embeddings combine to yield the vector representation of the graph.
- The model flattens the graph by concatenating triplets.
- At this point, the input is much smaller but still large. A modified attention mechanism finds the most salient parts of the graph and focuses there while generating output text.
Results: The authors tested their model on a question answering task based on the dataset called Explain Like I'm Five (ELI5).This dataset contains 270,000 question-answer pairs along with source documents (the top 100 web sources from the CommonCrawl corpus for each question). The graph approach edged out the earlier state of the art on F1 for ROUGE-1 (30 percent versus 28.9 percent). They also compared performance on the WikiSum dataset for multi-document summarization using an article’s title as the input query, the footnotes as source documents, and the first paragraph as the target summary. The graph approach underperformed the previous ROUGE-L state of the art 36.5 percent to 38.8 percent, but the comparison wasn't apples-to-apples. The previous research supplemented the corpus with a web search, while the new work used only CommonCrawl.
Why it matters: This research shows that natural language generation based on very large bodies of input text can work well. It also shows that source documents don’t need to be composed of well formed sentences. New ways of representing source documents may well lead to better language generation.
We’re thinking: Many search engines produce summaries or answer questions by choosing the most relevant document. The ability to draw on any number of documents could enable such models to deliver a far wider diversity of information, leading to better research tools and ultimately a better-informed public.

Is AI Making Mastery Obsolete?
Is there any reason to continue playing games that AI has mastered? Ask the former champions who have been toppled by machines.
What happened: In 2016, International Go master Lee Sedol famously lost three out of four matches to DeepMind’s AlphaGo model. The 36-year-old announced his retirement from competition on November 27. “Even if I become the number one, there is an entity that cannot be defeated,” he told South Korean's Yonhap News Agency,
Stages of grief: Prior to the tournament, Lee predicted that he would defeat AlphaGo easily. But the model’s inexplicable — and indefatigable — playing style pushed him into fits of shock and disbelief. Afterward, he apologized for his failure to the South Korean public.
Reaching acceptance: Garry Kasparov, the former world-champion chess player, went through his own cycle of grief after being defeated by IBM’s DeepBlue in 1997. Although he didn’t retire, Kasparov did accuse IBM’s engineers of cheating. He later retracted the charge, and in 2017 wrote a book arguing that, if humans can overcome their feelings of being threatened by AI, they can learn from it. The book advocates an augmented intelligence in which humans and machines work together to solve problems.
The human element: Although AlphaGo won in the 2016 duel, its human opponent still managed to shine. During the fourth match, Sedol made a move so unconventional it defied AlphaGo’s expectation and led to his sole victory.
We’re thinking: Lee wasn't defeated by a machine alone. He was beaten by a machine built by humans under the direction of AlphaGo research lead David Silver. Human mastery is obsolete only if you ignore people like Silver and his team.