
Dear friends,
We just wrapped up the Data-Centric AI Workshop at the NeurIPS 2021 conference. It was packed with information about how to engineer data for AI systems. I wish the whole DeepLearning.AI community could have been there! I expect the videos to be available before long and will let you know when they’re online
Over the course of an eight-hour session, authors presented 100 papers via two-minute lightning talks and posters. Eight invited speakers described a variety of data-centric AI issues and techniques, and expert panels answered questions from the audience.
These were some of my key takeaways:
- There’s a lot going on in data-centric AI — even more than I realized. I was also surprised by the variety of ideas presented on how to measure, engineer, and improve data. Several participants expressed variations on, “I’ve been tuning the data by myself for a long time, and it’s great to finally find a like-minded and supportive community to discuss it with.”
- Many diverse applications are using data-centric AI in areas including chatbots, content moderation, healthcare, document scanning, finance, materials science, speech, and underwater imaging. They take advantage of clever techniques for spotting incorrect labels, crowdsourcing, generating data, managing technical debt, managing data pipelines, benchmarking, and more.
- An immense amount of innovation and research lies ahead. We’re working collectively to coalesce broadly useful data-centric principles and tools. But, given the richness of the problems that remain open, it will take many years and thousands of research papers to flesh out this field.
 |
Among the invited speakers:
- Anima Anandkumar showed sophisticated synthetic data techniques.
- Michael Bernstein shared tips for making crowdsourcing much more effective.
- Douwe Kiela demonstrated DynaBench as a tool for creating new data-centric benchmarks.
- Peter Mattson and Praveen Paritosh described efforts to benchmark data including a plan by MLCommons to continue developing projects like DataPerf.
- Curtis Northcutt described the CleanLab system, which made it possible to find many labeling errors in the test sets of widely used datasets like MNIST and ImageNet.
- Alex Ratner described a programmatic approach to Data-Centric AI.
- Olga Russakovsky presented a tool for de-biasing large datasets.
- D. Scully discussed the role of data-centric AI in addressing technical debt in machine learning systems.
I also enjoyed hearing participants in DeepLearning.AI and Landing AI’s Data-centric AI Competition speak about their submissions. You can read some of their blog posts here.
Thanks to everyone who participated in the workshop or submitted a paper; to the presenters, panelists, invited speakers, and poster presenters; and to the reviewers, volunteers, and co-organizers who put the program together.
I was struck by the energy, momentum, and camaraderie I felt among the participants. I came away more excited than ever to keep pushing forward the data-centric AI movement, and I remain convinced that this field will help everyone build more effective and fairer AI systems.
Keep engineering your data!
Andrew
News
 |
What Makes TikTok Tick
A leaked document gave reporters a glimpse of what makes TikTok’s renowned recommender algorithm so effective.
What’s new: An internal report produced by TikTok’s Beijing-based engineering team for nontechnical colleagues describes the short-form video streaming platform’s formula for recommending videos to particular users, according to The New York Times. The Times received the document from an employee who was disturbed by TikTok’s distribution of content that could encourage self-harm. The company confirmed its authenticity.
How it works: The company’s primary goal is to add daily active users. A flowchart (see above) indicates that the primary factors that determine daily active use are time spent with the app and repeated uses (“retention”), which in turn are driven largely by interactions such as likes and comments and video quality as determined by the creator’s rate of uploads and ability to make money from them. To that end, the recommender scores each video with respect to a given user and offers those with the highest scores.
- The ranking algorithm applies a formula that, in simplified form, goes like this: Plike x Vlike + Pcomment x Vcomment + Eplaytime x Vplaytime + Pplay x Vplay. The Times report didn't define its terms.
- A machine learning model predicts whether a given user will like a given video, comment on it, spend a particular amount of time watching it, or play it at all. This model apparently supplies the variables marked P (for predicted) and E (for estimated). Those marked V could be the value of that activity; that is, how much the company values a given user liking, commenting, watching for a certain amount of time, or watching at all. Thus the formula appears to compute an estimated value of showing the video to the user.
- The document suggests various ways in which TikTok can refine the recommendations. For instance, it might boost the rank of videos by producers whose works a user watched previously, on the theory that they’re more likely to engage with that producer’s output.
- Conversely, in a bid to avoid boredom, it might penalize videos in categories that the user watched earlier the same day. It also penalizes videos that aim to achieve a high score by asking viewers explicitly to like them.
- The document suggests that Douyin, Tiktok’s Chinese equivalent, relies on a similar recommender.
What they’re saying: “There seems to be some perception (by the media? or the public?) that they’ve cracked some magic code for recommendation, but most of what I’ve seen seems pretty normal.” — Julian McAuley, professor of computer science, University of California San Diego, quoted by The New York Times.
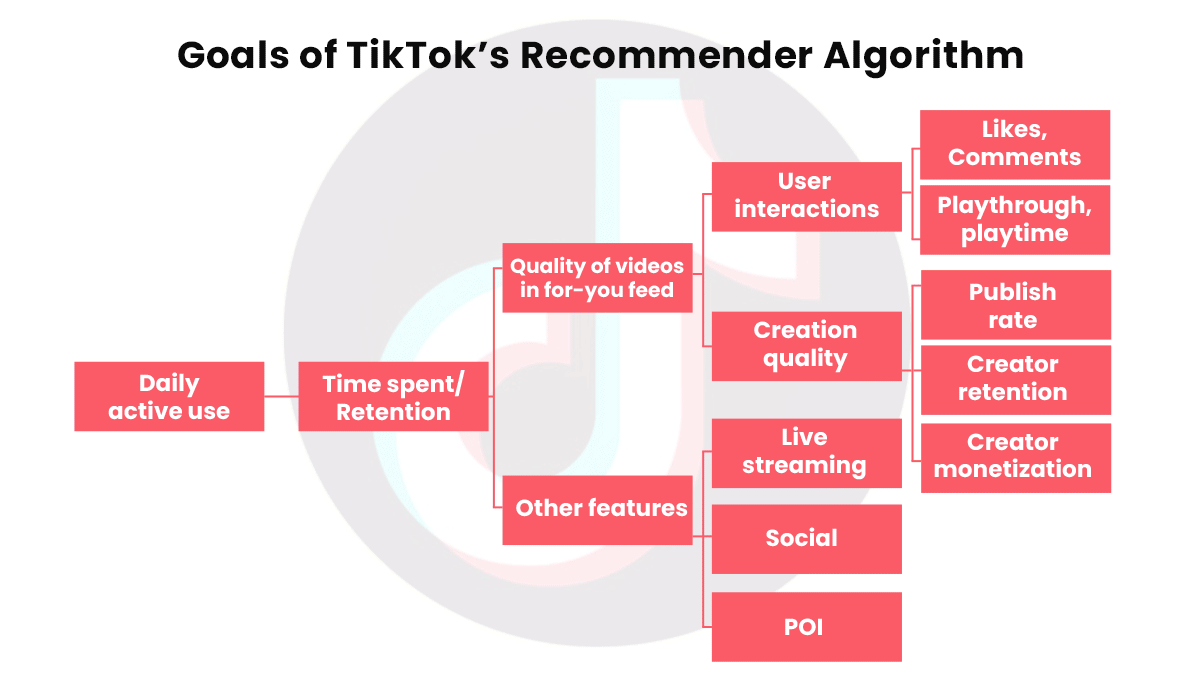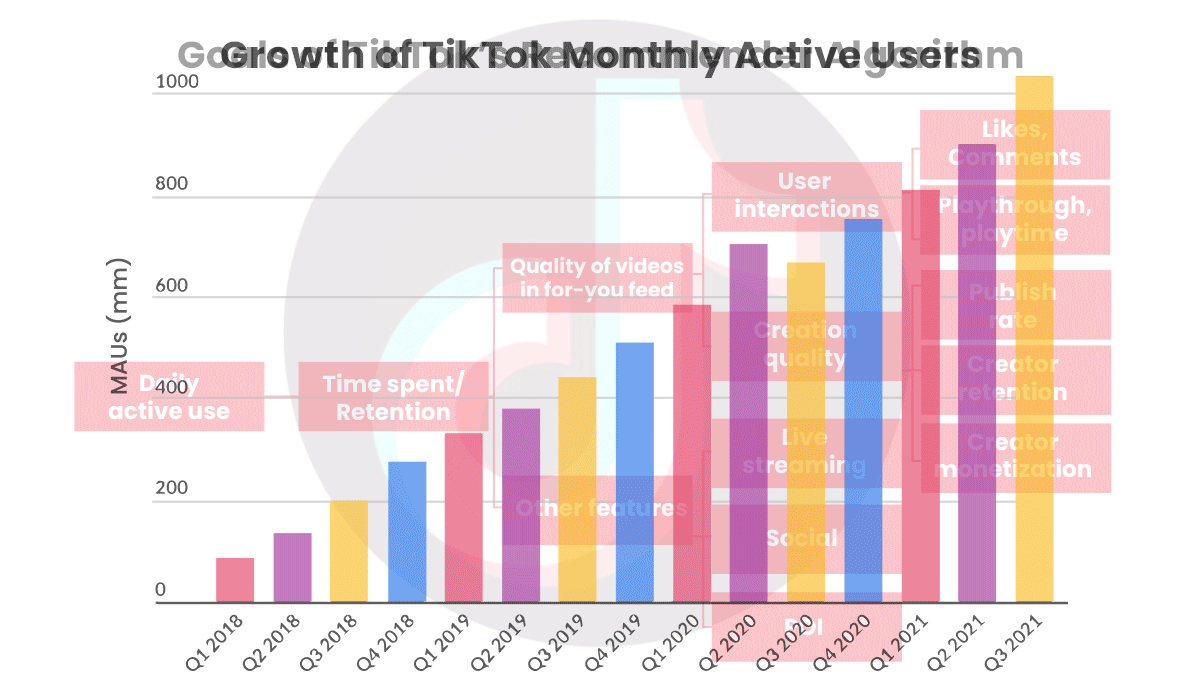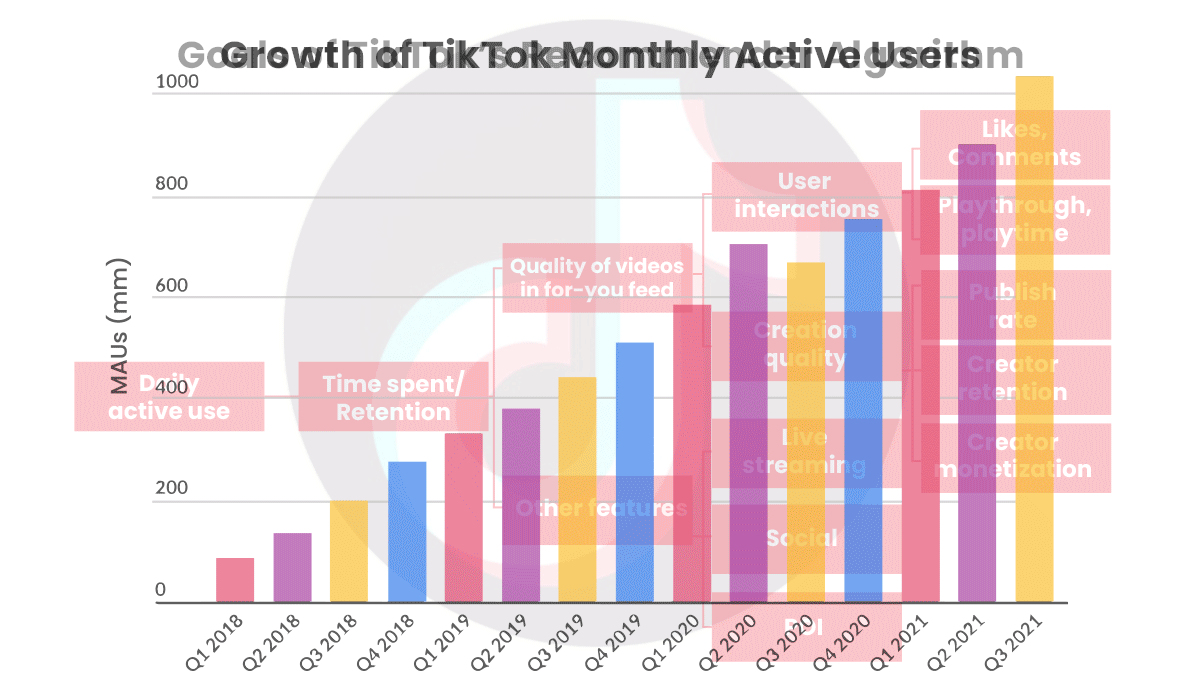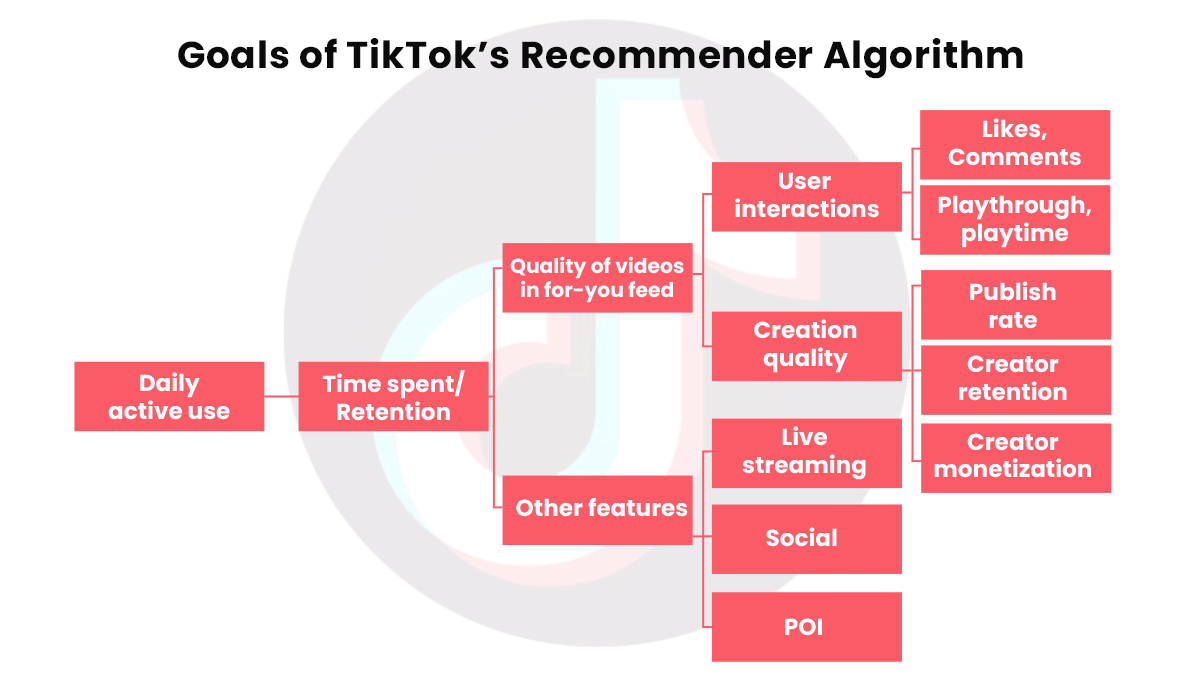
Behind the news: In July, The Wall Street Journal attempted to understand TikTok’s recommender by creating over 100 automated accounts, each with a fake date of birth, IP address, and interests such as yoga, forestry, or extreme sports. TikTok homed in on most of the bots’ interests in less than two hours. By analyzing the videos recommended to each account, the reporters determined that the algorithm gave the heaviest weights to time spent watching a video, number of repeat viewings, and whether the video was paused during playback.
Why it matters: TikTok has amassed over 1 billion monthly users since its founding in late 2016, and its recommender is an important part of the reason why. The secret sauce is clearly of interest to competitors and researchers, but as we learn more about social media’s worrisome social impacts — such as spreading misinformation, inciting violence, and degrading mental health — it becomes vital to understand the forces at play so we can minimize harms and maximize benefits.
We’re thinking: Compared to platforms that deliver longer videos, TikTok’s short format enables it to show more clips per hour of engagement and thus to acquire more data about what a user does and doesn’t like. This makes it easier to customize a habit-forming feed for each audience member.
 |
Large Language Models Shrink
DeepMind released three papers that push the boundaries — and examine the issues — of large language models.
What’s new: The UK-based subsidiary of Alphabet, Google’s parent company, unveiled a pair of transformer models that take different approaches to achieving state-of-the-art performance in a variety of language tasks. The company also pinpointed risks that are likely to intensify as such models continue to improve.
How it works: The company detailed its findings in three papers.
- Gopher is based on OpenAI’s GPT-2. The 280-billion-parameter model was trained on a 10.5-terabytes corpus, called MassiveText, of news, books, Wikipedia articles, and other web pages. Tested on 152 tasks including the BIG-bench and MMLU benchmarks, it set a new state of the art in 80 percent of them.
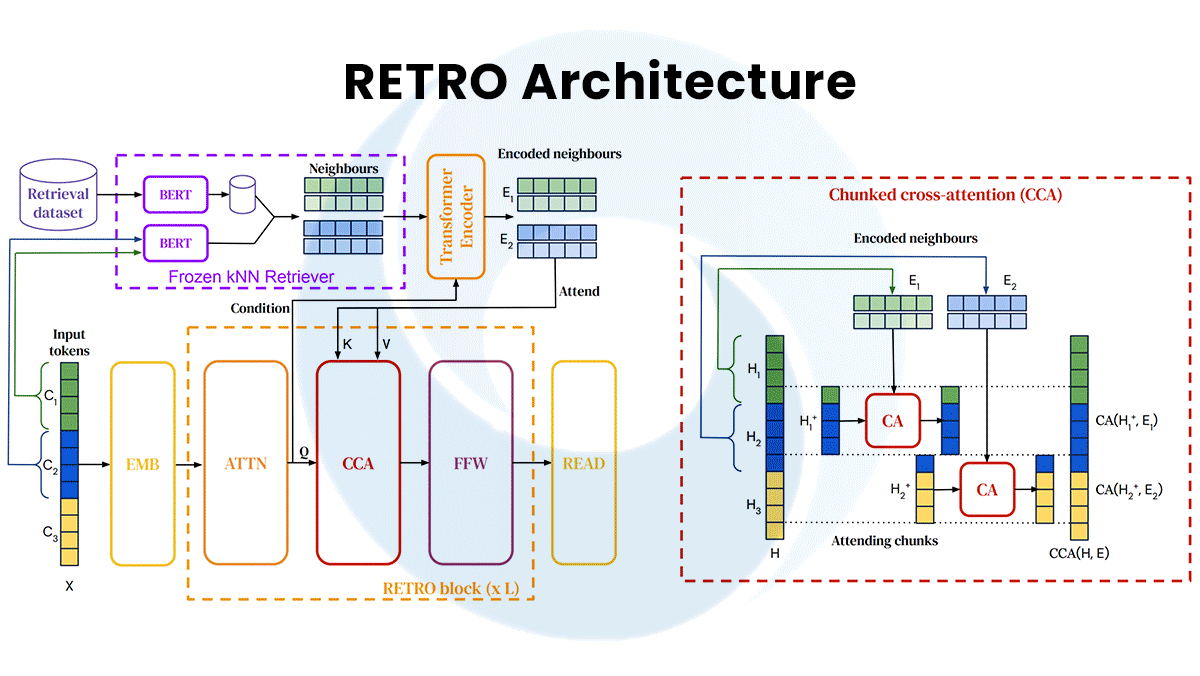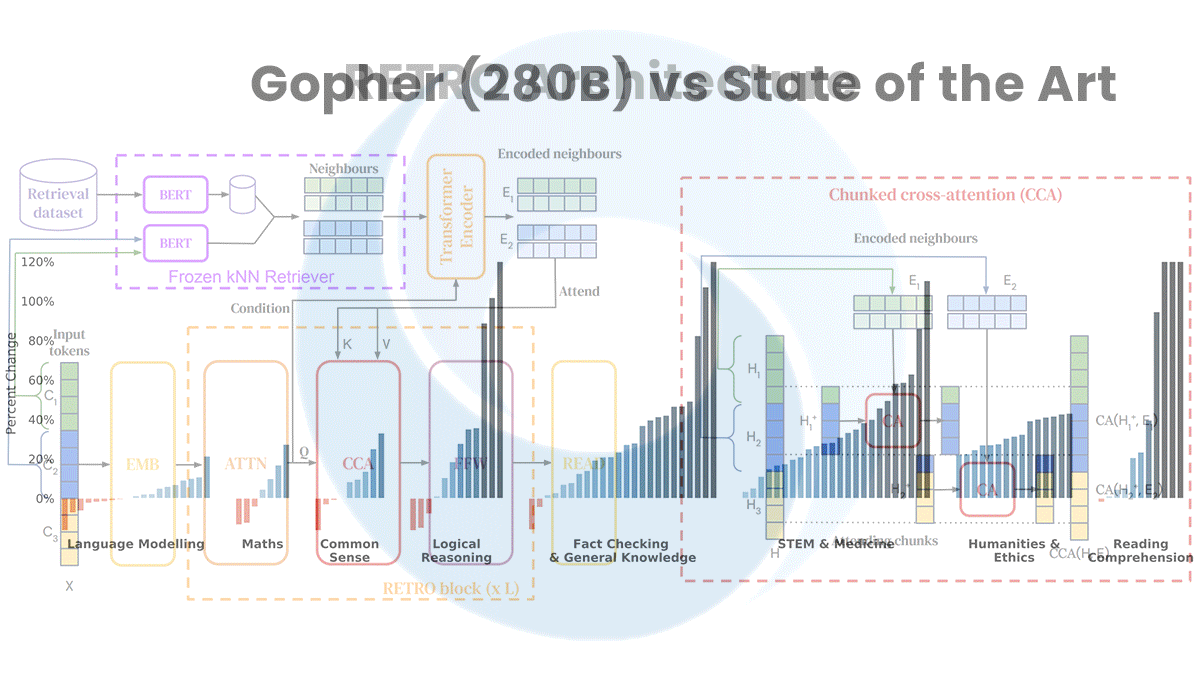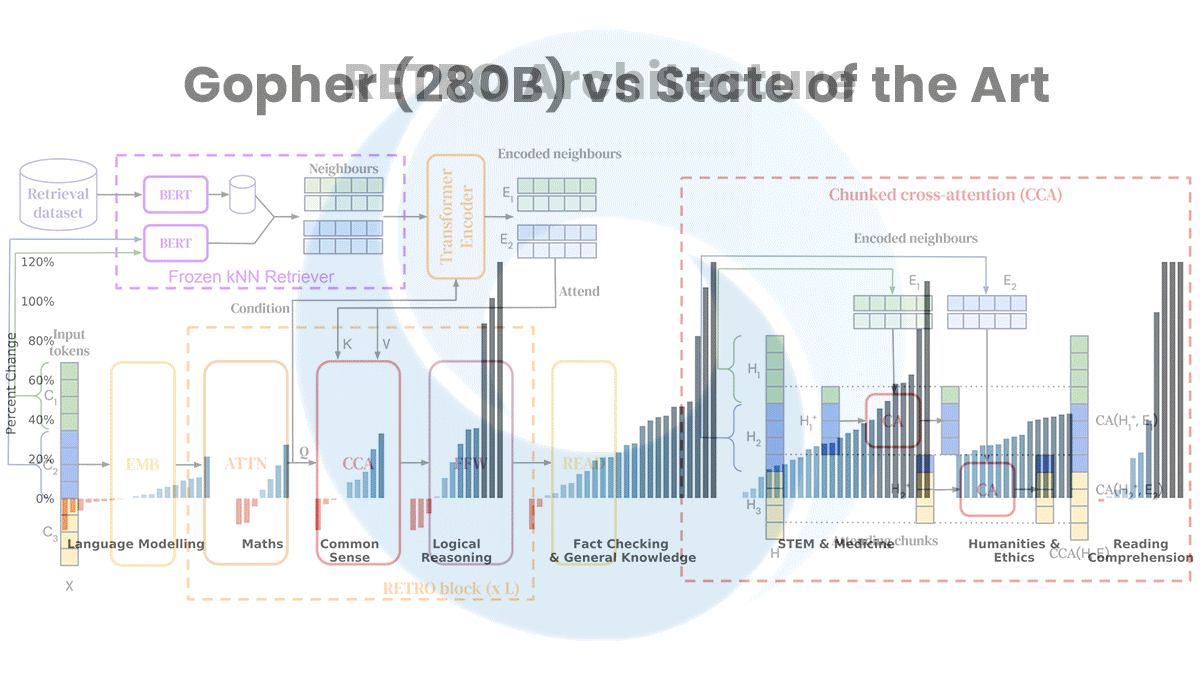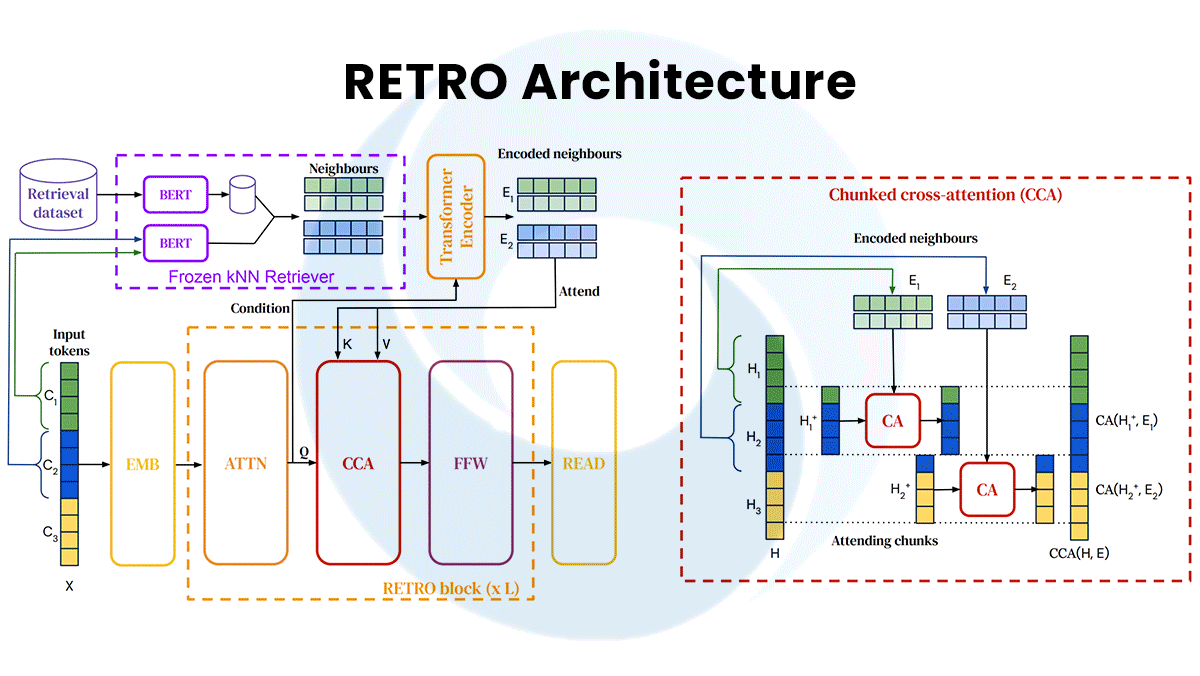
- Retrieval Enhanced Transformer (RETRO) achieved results similar to those of Gopher in 7 billion parameters. It makes up for its smaller size by retrieving passages from MassiveText and integrating them through what DeepMind calls chunked cross-attention, which finds relationships between the input and retrieved data.
- A third paper offers a taxonomy of 21 social and ethical risks that such models pose. For instance, they could inadvertently perpetuate stereotypes and toxic language, spread harmful misinformation, disclose sensitive information, and create an undue environmental burden from energy use. The paper lists strategies to alleviate such risks, including developing better datasets and building more transparent models.
Behind the news: Gopher and RETRO run counter the trend toward ever-larger language models. On the other hand, RETRO’s querying strategy extends recent research into connecting language models with external sources of knowledge.
- Considering its performance, Gopher’s 280-billion parameter count is conservative compared to that of Microsoft-Nvidia’s Megatron (530 billion) and Beijing Academy of Artificial Intelligence’s Wu Dao 2.0 (1.75 trillion).
- RETRO’s ability to gather external information is similar to that of Facebook’s RAG and Google’s REALM. An additional benefit: The database can be updated, giving the model access to newer or more accurate information without retraining.
Why it matters: Natural language models have made great strides in recent years, but much work remains to be done to make them reliable and compact enough for a wide variety of applications. With this triad of papers, DeepMind offers a multifaceted approach to delivering on this promise.
We’re thinking: The idea that machine learning models don’t need to learn everything but can query external sources during inference could be a key to building more efficient systems.
A MESSAGE FROM ML COMMONS
 |
MLCommons, an open engineering consortium dedicated to improving machine learning for everyone, released the People’s Speech Dataset and the Multilingual Spoken Words Corpus (MSWC) to democratize access to speech technology. Download the datasets today!
 |
Troll Recognition
A prominent online streaming service is using a machine learning model to identify trolls who try to get around being banned.
What’s new: Twitch, a crowdsourced streaming platform used primarily by video game enthusiasts, unveiled Suspicious User Detection. The new feature alerts when it recognizes a banned user who has logged in under a new name.
How it works: Twitch users deliver content through a channel, while the audience can watch, listen, and chat. Users who experience harassment can ban offenders from their channels. However, a ban doesn’t prevent aggressors from signing in under a new account and resuming the harassment.
- The model behind Suspicious User Detection scans the platform for signals that may indicate aggression. When it spots them, it compares information about the offender, including chat behavior and account details, with that of banned accounts.
- It classifies offenders as either possible or likely ban evaders. It blocks likely evaders from everyone except streamers and moderators, who can choose to ban them. It allows possible evaders to continue chatting, but it flags them to streamers and moderators so they can keep tabs and ban them if their activity warrants.
- Suspicious User Detection is active by default, but streamers can disable it in their channels.
Behind the news: Trolls are inevitable on any online platform. Twitch isn’t the only one that uses machine learning to combat them.
- Facebook’s hate speech detector in the fourth quarter of 2020 caught 49 percent of comments that contained harassment or bullying, including in non-English languages like Arabic and Spanish.
- Built by Intel and Spirit AI, Bleep monitors voice chat. It uses speech recognition to classify offensive language into one of 10 categories and lets users choose how much of each category to filter out.
- YouTube developed a model that recognizes titles, comments, and other signals associated with videos that spread conspiracy theories and disinformation. The model cut time spent watching such content by 70 percent across its platform.
Why it matters: Twitch is one of the world’s largest streaming platforms, but many of its contributors build their own anti-harassment tools in the face of what they feel is a lack of attention from the company. AI moderation tools can protect audience members looking to enjoy themselves, content creators aiming to deliver a great experience, and publishers who want to maximize valuable engagement metrics.
We’re thinking: Moderating online content is a game of cat and mouse but, as social media balloons, there simply aren’t enough paws to keep the vermin in check. AI tools can’t yet catch every instance of harassment, but they can extend the reach of human mods.
 |
Image Transformations Unmasked
If you change an image by moving its subject within the frame, a well trained convolutional neural network may not recognize the fundamental similarity between the two versions. New research aims to make CNN wise to such alterations.
What's new: Jin Xu and colleagues at DeepMind modified the input to particular CNN layers so translations and rotations of the input had the appropriate effect on the output.
Key insight: Given an image and a translated version of it, a model that’s robust to translation, for instance, should produce nearly identical representations, the only difference being that one is offset by the amount of the translation. Typical CNNs use alternating layers of convolution and downsampling, specifically pooling. They aren’t robust to such transformations because shifting the image changes the relative position of pixels within the pooling window, producing disparate representations. Maintaining relative pixel positions can preserve the representation despite translation, rotation, and reflection.
How it works: The authors trained a five-layer convolutional encoder/decoder to reconstruct a dataset of images of 2D shapes against plain backgrounds. In each training example, the shape was located at the upper left of the image and oriented at an angle between 0 and 90 degrees. The following steps describe how the network handled translation (it managed rotation and reflection in an analogous way):
- A convolution layer generated a representation of an image.
- Before each downsampling layer, the network found the position in the pooling window of the largest value in the representation. Then it shifted the representation by that integer. Subsequently it performed pooling normally and concatenated the size of the shift to the representation.
- The encoder repeated the convolution-and-pooling operation five times, collecting the shift amounts into a list. Thus the encoded representation had two parts: the typical convolutional representation and a list of translation amounts at each pooling layer.
- The decoder alternated the convolution and upsampling layers five times to reconstruct the original input. The upsampling layers took into account the amount of translation before the corresponding downsampling layers before increasing the size of the representation.
Results: In qualitative tests, the authors’ modified CNN reconstructed test images outside of the training distribution, such as shapes located at the right side of the image or rotated more than 90 degrees, more accurately than a baseline model that used normal pooling. It reconstructed 3,200 images from the grayscale Fashion-MNIST dataset of images of clothes and accessories with a mean reconstruction error of 0.0033, a decrease from the baseline architecture’s 0.0055.
Why it matters: The world is full of objects, placed willy-nilly. A CNN that can recognize items regardless of their orientation and position is likely to perform better on real-world images and other examples outside its training set.
We're thinking: This model would recognize a picture of Andrew if his head were shifted to one side. But would it recognize him if he were wearing something other than a blue shirt?