
Dear friends,
Data-centric AI development is catching on! I first spoke about it publicly in March, drawing on Landing AI’s work on a data-centric platform for computer vision. Since then, great companies like Kili Technologies, Scale AI, and Snorkel have mentioned data-centric AI on their homepages.
Along with enthusiasm for data-centric AI, though, I’ve come across several misconceptions about it. Here are the top myths about data-centric AI:
Myth: Data-centric AI doesn’t address the critical problem of building responsible AI.
Reality: Data-centric AI offers powerful ways to make AI more fair. If we audit a loan-making system and find that its decisions are biased against a particular group, how can we fix the problem? Adjusting the algorithm may help, but any substantial improvement risks degrading performance on other slices, or subsets, of the data. With a data-centric approach, we can engineer training and test data associated with the slice for which we want the algorithm’s behavior to change — a valuable tool in building responsible AI.
Myth: Data-centric AI is just a rebranding of applied machine learning.
Reality: While practitioners have engineered data for years, we’ve done it in ways that are often ad hoc, cumbersome, and overly dependent on an individual’s skill or luck. Data-centric AI is a shift toward developing systematic engineering practices for improving data in ways that are reliable, efficient, and systematic.
Myth: Data-centric AI just means paying more attention to data.
Reality: This is like saying, “Writing good code just means paying more attention to code quality.” It oversimplifies the concept to the point of trivializing it. Yes, paying attention is important, but that barely scratches the surface. We need to develop better methods, techniques, and tools for measuring and improving data quality.
Myth: Data-centric AI just means doing a better job of preprocessing data.
Reality: Improving the data isn't something you do only once as a preprocessing step. It should be a core part of the iterative process of model training as well as deployment and maintenance. For example, after training a model to classify cells in microscope slides, if error analysis shows that it performs poorly on a subset of cells, you can use data-centric methods to improve performance on that subset.
Myth: Data-centric AI is only about labeling (or data augmentation, data cleaning, metadata, data storage, model monitoring . . . ).
Reality: Data-centric AI development is about the systematic engineering of data to ensure successful AI applications. All of the above are important, and no single one is sufficient.
Myth: Data-centric AI works only for unstructured data such as images and audio, but doesn’t work for structured (e.g., tabular) data.
Reality: Data-centric AI is valuable whether you’re working with unstructured or structured data, although the best practices differ in either case. With unstructured data, it’s typically easier to get humans to provide labels and to collect or synthesize more data. With structured data, I’ve found that data-centric approaches lean more toward cleaning up existing data and creating additional features.
Keep learning!
Andrew
P.S. What do you say when someone asks you to define data-centric AI? Our community doesn’t yet have a widely agreed-upon definition. Want to help me come up with one? Please let me know what you think on LinkedIn or Twitter.
News
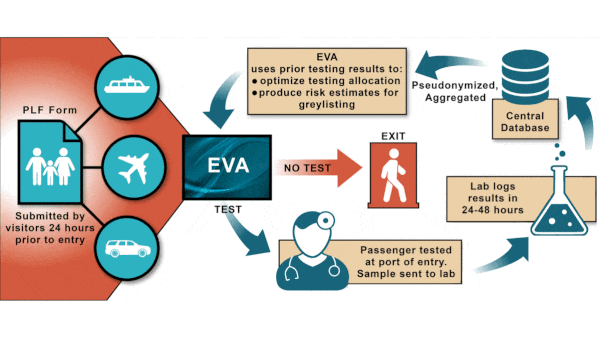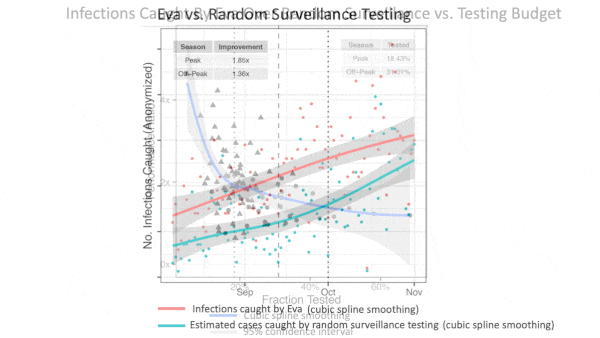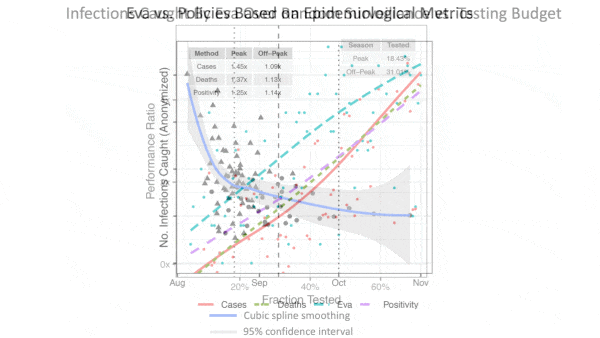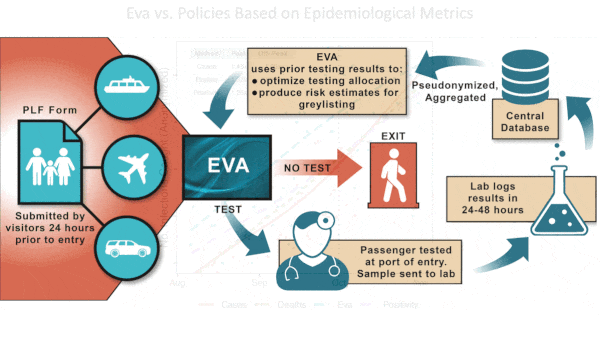
Who Needs a Covid Test? AI Decides
Greece’s border agents last year had enough Covid tests to swab only 17 percent of people who sought to enter the country. They managed the shortage by using an AI system to flag high-risk visitors.
What’s new: Between July and November, 2020, Greece deployed a reinforcement learning system to help border agents decide which travelers to test before admitting them to the country. A recent analysis confirmed that it was more effective than other methods.
How it works: Eva, a system developed by Attikon University Hospital and the Universities of Athens, Pennsylvania, Southern California, and Thessaly, was used at all 40 of the country’s entry points.
- Eva aimed to allocate available tests at each point of entry in a way that balanced estimated risk of infection for certain groups (based on data from immigration forms including age, sex, country of origin, and region within the country) against uncertainty in the estimation of risk. In this way, it focused on the highest-risk visitors while distributing tests more broadly.
- The system provided a list of visitors to test. Test results came back 48 hours later.
- The algorithm adjusted its estimates of risk and uncertainty daily based on the latest test results. In addition, it allowed officials to update the number of tests available daily.
Results: Eva identified between 1.25 and 1.45 more infected travelers than testing travelers strictly based on their country of origin. Compared to random testing, Eva identified four times more infected travelers during the peak travel season (August and September) and 1.85 times more outside the peak season. As vaccines came into use and tests became more available, one of the researchers told The Batch, Greek authorities set Eva aside. The country now simply requires every visitor to provide either proof of vaccination or a negative test.
Behind the news: Many countries, seeking to contain the spread of Covid, barred visitors based on where they came from, relying on population-level factors such as the volume of Covid cases and deaths per capita in the visitor’s home country. Since then, several studies have shown that such methods are flawed due to the medical community’s early missteps in understanding how Covid spreads.
Why it matters: The pandemic so far has taken millions of lives and livelihoods. Assuming they don’t disadvantage any group unfairly, models like this can help countries keep their borders open and while mitigating the risk of international spread.
We’re thinking: Greek authorities installed this model in a pre-existing bureaucracy that manages thousands of visitors daily. Its success offers hope for projects in fields like healthcare that interoperate with similarly complex and messy human systems.

Too Fabulous for Face Recognition
Drop off your adversarial hats, eyeglasses, and tee shirts to the second-hand store. The latest fashion statement is adversarial makeup.
What’s new: Researchers at Ben-Gurion University and NEC developed a system for applying natural-looking makeup that makes people unrecognizable to face recognition models.
How it works: Working with 20 volunteers, the researchers used FaceNet, which learns a mapping from face images to a compact Euclidean space, to produce heat maps that showed which face regions were most important for identification.
- They used the consumer-grade virtual makeover app YouCam Makeup to adapt the heatmaps into digital makeup patterns overlaid on each volunteer’s image.
- They fed iterations of these digitally done-up face shots to FaceNet until the subject was unrecognizable.
- Then a makeup artist physically applied the patterns to actual faces in neutral tones.
- The volunteers walked down a hallway, first without and then with makeup, while being filmed by a pair of cameras that streamed their output to the ArcFace face recognizer.
Results: ArcFace recognized participants wearing adversarial makeup in 1.2 percent of frames. It recognized those wearing no makeup in 47.6 percent of video frames, and those wearing random makeup patterns in 33.7 percent of frames.
Why it matters: This new technique requires only ordinary, unobtrusive makeup, doing away with accessories that might raise security officers’ suspicions. It offers perhaps the easiest way yet for ordinary people to thwart face recognition — at least until the algorithms catch on.
We’re thinking: You can’t make up this stuff. Or can you?
A MESSAGE FROM QUANTUMSCAPE

QuantumScape is accelerating mass-market adoption of electric vehicles by using deep learning to improve next-generation, solid-state batteries. And it’s hiring! Check out open positions at QuantumScape.

More Thinking Solves Harder Problems
In machine learning, an easy task and a more difficult version of the same task — say, a maze that covers a smaller or larger area — often are learned separately. A new study shows that recurrent neural networks can generalize from one to the other.
What’s new: Avi Schwarzschild and colleagues at the University of Maryland showed that, at inference, boosting recurrence to a neural network — sending the output of a portion of the network back through the same block repeatedly before allowing it to move through the rest of the network — can enable it to perform well on a harder version of a task it was trained to do.
Key insight: A network’s internal representation of input data should improve incrementally each time it passes through a recurrent block. With more passes, the network should be able to solve more difficult versions of the task at hand.
How it works: The authors added recurrence to ResNets prior to training by duplicating the first residual block and sharing its weights among all residual blocks. (As non-recurrent baselines, they used ResNets of equivalent or greater depth without shared weights.) They trained and tested separate networks on each of three tasks:
- Mazes: The network received an image of a two-dimensional maze and generated an image that highlighted the path from start to finish. The authors trained a network with 20 residual blocks on 9x9 grids and tested it on 13x13 grids.
- Chess: The network received an image of chess pieces on a board and generated an image that showed the origin and destination squares of the best move. The authors trained a network with 20 residual blocks on chess puzzles with standardized difficulty ratings below 1,385, then tested it on those with ratings above that number.
- Prefix strings: The network received a binary string and generated a binary string of equal length in which each bit was the cumulative sum of the input, modulo two (for example, input 01011, output 01101). The authors trained a network with 10 residual blocks on 32-bit strings and tested it on 44-bit strings.
Results: In tests, the recurrent networks generally improved their performance on the more complex problems with each pass through the loop — up to a limit — and outperformed the corresponding nonrecurrent networks. The authors presented their results most precisely for prefix strings, in which the recurrent networks achieved 24.96 percent accuracy with 9 residual blocks, 31.02 percent with 10 residual blocks, and 35.22 percent with 11 residual blocks. The nonrecurrent networks of matching depth achieved 22.17 percent, 24.78 percent, and 22.79 percent accuracy respectively. The performance improvement was similar on mazes and chess.
Why it matters: Forcing a network to re-use blocks can enhance its performance on harder versions of a task. This work also opens an avenue for interpreting recurrent neural networks by increasing the number of passes through a given block and studying changes in the output.
We’re thinking: Many algorithms in computing use iteration to refine a representation, such as belief propagation in probabilistic graphical models. It’s exciting to find that this algorithm learns weights in a similarly iterative way, computing a better representation with each pass through the loop.
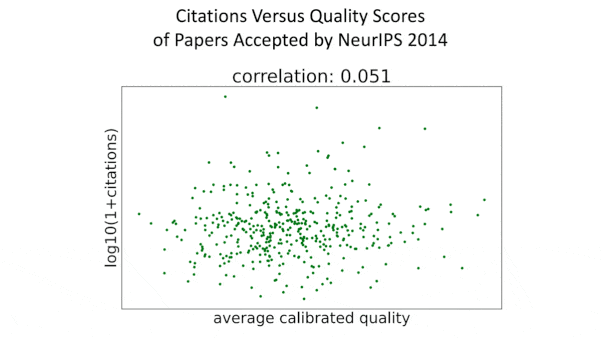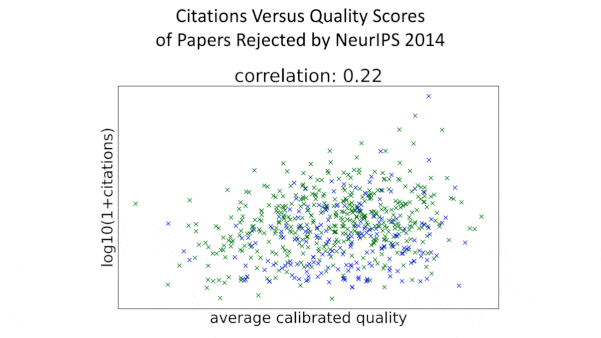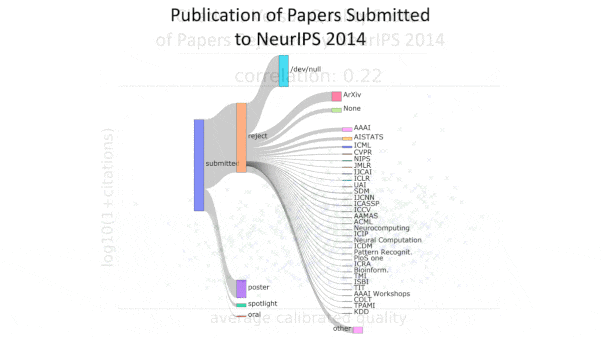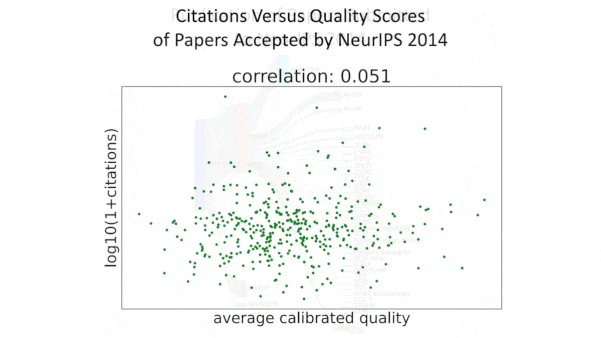
Conference Paper Choices Under Fire
A prestigious machine learning conference failed to highlight the highest-impact research, according to a new study.
What’s new: In a retrospective analysis, researchers found that papers accepted to NeurIPS 2014 showed little correlation between the conference’s assessment of their quality and their impact on machine learning to date.
How it works: The authors — who served as the program chairs of NeurIPS 2014 — compared quality scores assigned by the conference’s reviewers with numbers of citations tracked via Semantic Scholar.
- NeurIPS typically recruits at least three reviewers to score papers for quality, and it features those with high average scores. It accepts 23.5 percent of submitted papers on average.
- The authors examined roughly 400 papers that were accepted and a random selection of 680 papers that were rejected.
- The quality scores given to papers accepted by the conference didn't correspond to the numbers of citations the papers garnered, indicating that the reviewers were bad at recognizing papers likely to have a long-term impact. The lower scores of rejected papers showed a slight correlation with lower numbers of citations, indicating somewhat greater success at filtering out papers with low long-term impact.
Recommendations: The authors suggest that future conferences, rather than relying on a single quality score, evaluate papers on various dimensions such as clarity, rigor, significance, and originality. This would provide granular assessments that could be averaged or weighted to better identify significant work.
Behind the news: This study builds on an earlier experiment in which two separate committees reviewed the same random selection of 170 papers submitted to NeurIPS 2014. The committees accepted around half of the same papers, which suggests little consistency in their criteria. NeurIPS 2021 is repeating this experiment.
Why it matters: This study calls into question the AI community’s habit of using conference presentations and journal bylines as a barometer of a researcher’s worth. The evaluation process — for NeurIPS 2014, at least — was less than robust, and the reviewers failed to notice plenty of worthwhile work.
We’re thinking: If human annotators don’t provide 100-percent accurate labels for a relatively unambiguous dataset like ImageNet, it should come as no surprise that conference reviewers don't render consistent evaluations of cutting-edge research. Predicting which research has the greatest long-term value is a challenging problem, and designing a process in which thousands of reviewers vet thousands of papers is no less thorny. The NeurIPS program chairs deserve accolades for having the courage to question the conference’s judgements. Meanwhile, it should go without saying that machine learning researchers are not defined by their conference acceptances.