
Dear friends,
I’m thrilled to announce the NeurIPS Data-Centric AI Workshop, which will be held on December 14, 2021. You may have heard me speak about data-centric AI, in which we systematically engineer the data that feeds learning algorithms. This workshop is a chance to delve more deeply into the subject.
Why a workshop? I’ve seen many subfields of AI emerge first by having practitioners advocate for them privately, after which they mature to a point where workshops bring together researchers and practitioners to develop and share ideas with each other. Eventually they become mainstream, and more of their work becomes incorporated into major AI conferences.
Indeed, even deep learning once was a niche topic at NeurIPS, and my friends and I organized workshops to share ideas and build momentum.
While data-centric AI is gaining momentum in practice, there’s still much research to be done. One common misconception is that data-centric AI is simply a matter of paying closer attention to engineering the data that algorithms learn from. While this mindset is important, we also need to develop general principles, algorithms, and tools that enable us to apply this mindset in a way that’s repeatable and systematic. Tools like TensorFlow and PyTorch made engineering of neural network architectures more systematic and less error-prone; likewise we need new tools for engineering data.

My team at Landing AI (which is hiring!) is inventing data-centric algorithms for image data as part of an MLOps platform for computer vision. I’d love to see hundreds or thousands more groups working on data-centric algorithms.
Open questions include:
- What algorithms or tools can accelerate the sourcing of high-quality data?
- What algorithms or tools can identify inconsistently labeled data?
- What general design principles can make improving data quality more systematic?
- What tools can help practitioners carry out error analysis more efficiently?
- How can data engineering advance responsible AI, for example, to ensure fairness and minimize bias in trained models?
The workshop is accepting research paper submissions that address such issues until September 30, 2021. Please check out the website for details.
Special thanks to my co-organizers Lora Aroyo, Cody Coleman, Greg Diamos, Vijay Janapa Reddi, Joaquin Vanschoren, and Sharon Zhou.
Keep learning!
Andrew
News
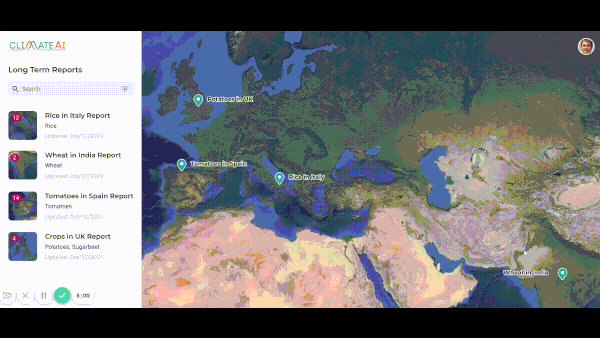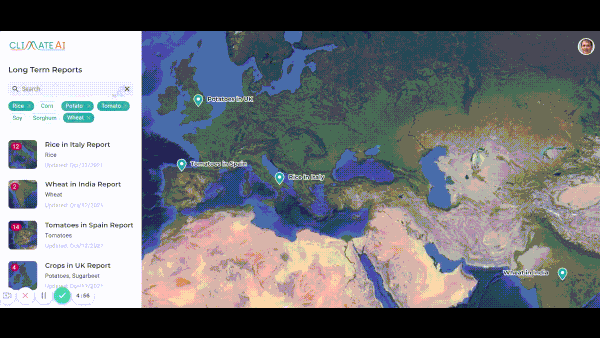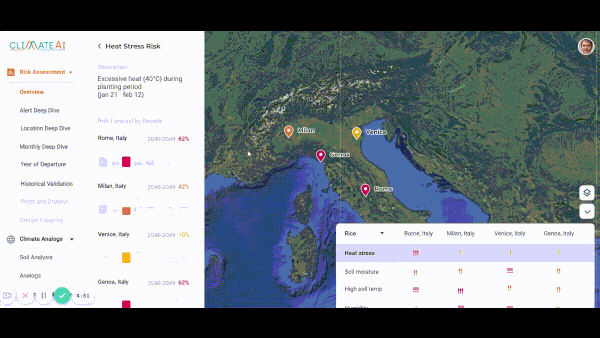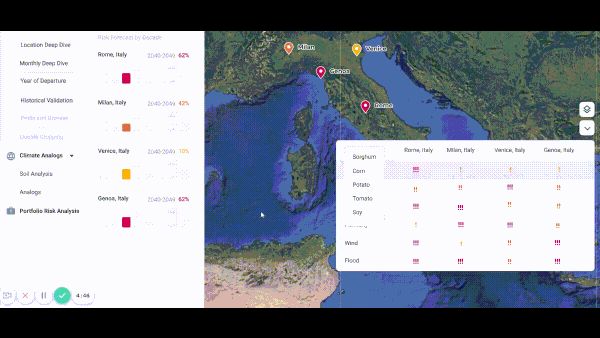
Getting a Jump on Climate Change
Startups are predicting how climate change will affect global commerce.
What’s new: Companies that specialize in climate analytics are training neural networks to help businesses manage risks posed by a warming globe, The Wall Street Journal reported.
Changes in the air: These young companies model interactions among environmental data and factors such as commodity prices, consumption patterns, and import/export data. They sell the resulting insights to corporate customers who are concerned about the impact of climate change on their ability to buy goods and raw materials.
- ClimateAI, founded in San Francisco in 2017, trained its model on the output of long-range climate simulations. The model generates short-term forecasts — useful for identifying risks in the coming year — and predicts how crops will fare in various regions well into the future. The company, which has raised $16 million, predicted that 2020 would bring higher-than-average rainfall in a part of Australia, helping a seed company increase its sales by 5 to 10 percent.
- Gro Intelligence, a New York company that has raised $115 million since 2014, analyzes over 40,000 data sources including satellite imagery and precipitation reports to forecast the severity of future droughts, floods, and other extreme weather events as well as their impacts on over 15,000 agricultural commodities. Its customers include consumer goods giant Unilever (Ben & Jerry’s, Lipton, Knorr), fast-food conglomerate Yum! Brands (KFC, Pizza Hut, Taco Bell), and European financial titan BNP Paribas.
- One Concern analyzes data sources including Google Street View and satellite imagery to help customers plan for and execute disaster response plans, including those caused by climate change, on buildings, roads, and other infrastructure. The Menlo Park, California, company has raised $119 million since its founding in 2015.
Behind the news: Corporations are waking up to the hazards posed by climate change to their own well-being.
- A 2021 survey of 8,098 companies throughout the world estimates that climate change, deforestation, and water scarcity will cost corporations $120 billion over the next five years.
- The U.S. Securities and Exchange Commission, which regulates publicly traded companies, plans to require corporations to disclose known climate risks to investors.
- Earlier this year, Exxon Mobil shareholders elected new board members who promised to redirect the oil and gas giant toward clean sources of energy.
Why it matters: This year’s run of record-breaking wildfires, floods, and freezes are a preview of what to expect in a warmer world, according to the latest International Panel on Climate Change report. AI-powered forecasts can help businesses protect assets and revenue — and the rest of us prepare for further impacts to come.
We’re thinking: By calculating the costs of climate disaster, AI can make the very real danger posed by atmospheric carbon emissions feel as urgent as it is.
AI Sales Closing In on $500 Billion
A new report projects a rosy future for the AI industry.
What’s new: A study from market research firm IDC estimates that global revenues for AI software, hardware, and services will reach $341.8 billion in 2021 — up from an estimated $156.5 billion last year — and will break $500 billion by 2024. The study reflects interviews, distribution statistics, financial reports, and other data from over 700 AI companies around the world.
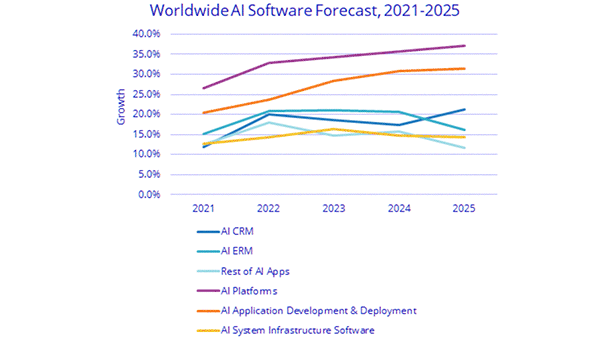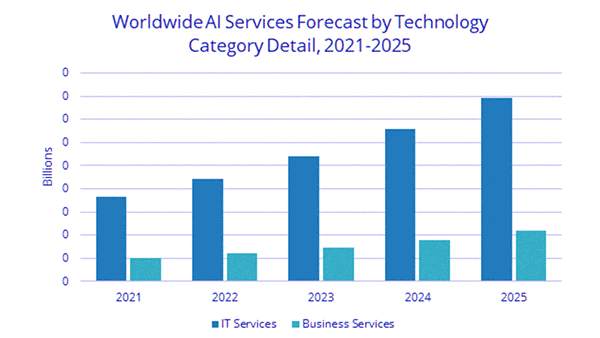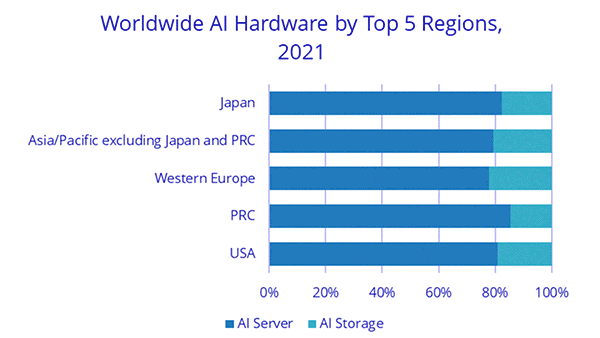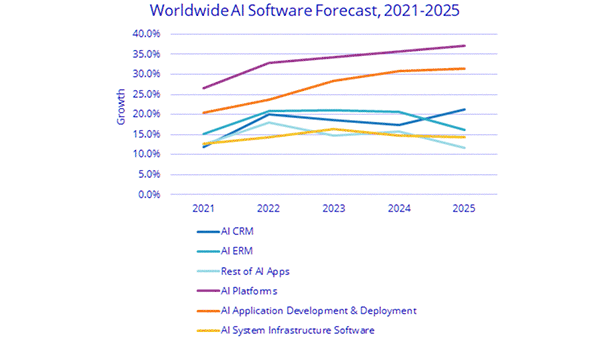
What they found: The AI industry’s annual growth rate is expected to exceed 18.8 percent next year. The analysis breaks up that growth into three broad categories. Some of the most important findings:
- Software: Software sales make up 88 percent of the overall AI market. AI platforms (the largest of six software subcategories) account for half of the total. However, AI applications are expected to grow most quickly, marking a five-year annual rate of 33.2 percent.
- Hardware: AI-focused hardware — mainly servers and storage — accounts for just 5 percent of the industry’s sales. However, it is projected to grow by 29.6 percent in 2021 and 2022, faster than software and services. Server sales account for 82 percent of hardware sales which are dominated by Dell, HPE, Huawei, IBM, Inspur, and Lenovo.
- Services: AI services generated 14 percent of total sales and are expected to grow at a 21 percent compound annual rate through 2025. IT services bring in 80 percent of sales in this area.
Behind the news: IDC’s most recent predictions are in line with their previous report, published in February, and jibe with research from MIT Technology Review.
Why it matters: In the AI world — as in other high-tech sectors — it’s often difficult to discern real growth potential from gossip-fueled hype. Research reports that provide granular insights are a crucial tool for business leaders and investors who aim to capitalize on this industry, not to mention machine learning engineers who are plotting a career.
We’re thinking: We’ve seen market research reports that later proved right and many that later proved dead wrong. We hope this is one of the former!
A MESSAGE FROM DEEPLEARNING.AI

Learn how to design machine learning production systems end-to-end in “Deploying Machine Learning Models in Production,” Course 4 of the Machine Learning Engineering for Production (MLOps) Specialization on Coursera! Enroll now

Perceptrons Are All You Need
The paper that introduced the transformer famously declared, “Attention is all you need.” To the contrary, new work shows you may not need transformer-style attention at all.
What’s new: Hanxiao Liu and colleagues at Google Brain developed the gated multi-layer perceptron (gMLP), a simple architecture that performed some language and vision tasks as well as transformers.
Key insight: A transformer processes input sequences using both a vanilla neural network, often called a multi-layer perceptron, and a self-attention mechanism. The vanilla neural network works on relationships between each element within the vector representation of a given token — say, a word in text or pixel in an image — while self-attention learns the relationships between each token in a sequence. However, the vanilla neural network also can do this job if the sequence length is fixed. The authors reassigned attention’s role to the vanilla neural network by fixing the sequence length and adding a gating unit to filter out the least important parts of the sequence.
How it works: To evaluate gMLP in a language application, the authors pretrained it to predict missing words in the English version of the text database C4 and fine-tuned it to classify positive and negative sentiment expressed by excerpts from movie reviews in SST-2. For vision, they trained it on ImageNet using image patches as tokens.
- The model passed input sequences to a series of gMLP blocks, each of which contained a vanilla neural network, followed by a gating unit and another vanilla neural network.
- The vanilla neural networks processed a 768-element vector representation of each token individually to find relationships among the elements.
- The gating unit effectively zeroed out parts of the input to ensure they would have little effect on the output. It did this by multiplying the input by a learned vector such that, if values in the vector were near zero, the corresponding input values would be near zero.
- Different softmax layers learned to predict the next word in C4, classify sentiment in SST-2, and classify ImageNet.
Results: In tests, gMLP performed roughly as well as the popular transformer-based language model BERT. The authors compared the performance on C4 of comparably sized, pretrained (but not fine-tuned) models. gMLP achieved 4.28 perplexity, which measures a model’s ability to predict words in a test set (smaller is better), while BERT achieved 4.17 perplexity. On SST-2, gMLP achieved 94.2 percent accuracy, while BERT achieved 93.8 percent accuracy. The authors’ approach performed similarly well in image classification after training on ImageNet. gMLP achieved 81.6 percent accuracy compared to a DeiT-B’s 81.8 percent accuracy.
Why it matters: This model, along with other recent work from Google Brain, bolsters the idea that alternatives based on old-school architectures can approach or exceed the performance of newfangled techniques like self-attention.
We’re thinking: When someone invents a model that does away with attention, we pay attention!

Solar System
Astronomers may use deep learning to keep the sun in focus.
What’s new: Researchers at the U.S. National Aeronautics and Space Administration (NASA), Catholic University of America, University of Oslo, and elsewhere developed a model that helps recalibrate a space telescope focused on the sun.
Key insight: Although the sun is a writhing ball of fiery plasma, patterns across its surface correlate with its brightness. A neural network can learn to associate these patterns with their characteristic brightness, so its output can be used to recalibrate equipment that monitors Earth’s nearest star.
How it works: The Solar Dynamics Observatory is a satellite that watches activity in the sun’s outer layers from orbit. Over time, light and space-borne particles degrade its lenses and sensors, dimming its output. NASA typically recalibrates the equipment by comparing the observatory’s images with similar pictures captured by instruments aboard small rockets — an expensive method carried out only periodically. The new model generates a calibration curve that can be used to adjust the observatory on an ongoing basis.
- The authors artificially dimmed solar images captured at various wavelength of light.
- They trained a convolutional neural network to predict how much they had dimmed the images.
- The predicted degradation can be used to calibrate the observatory.
Results: In tests using images taken by uncalibrated equipment, the model outperformed a baseline method that didn’t involve machine learning. Defining success as a prediction within 10 percent of the actual degree of dimming, the authors obtained 77 percent mean success across all wavelengths. The baseline achieved 43 percent mean success.
Why it matters: Recalibrating the observatory based on data from the rockets results in downtime as the equipment degrades between launches. Automated recalibration could keep the equipment operating continuously. This approach could also be a boon to probes that monitor faraway bodies, which can’t rely on rocket-assisted correction.
We’re thinking: Mother always told us not to stare at the sun, but she didn’t say anything about making a neural network do it for us.