
A recent generative adversarial network (GAN) produced more coherent images using modified transformers that replaced fully connected layers with convolutional layers. A new GAN achieved a similar end using transformers in their original form.
What’s new: Yifan Jiang and collaborators at the University of Texas at Austin and the MIT-IBM Watson AI Lab unveiled TransGAN, a transformer-based GAN that doesn’t use any convolutions.
Key insight: Traditionally, GANs rely on convolutional neural networks, which integrate information in pixels far away from one another only in the later layers. The upshot could be an image of a person with two different eye colors or mismatched earrings. A GAN based on transformers, which use self-attention to determine relationships among various parts of an input, would learn relationships between pixels across an entire image from the get-go. That should enable it to produce more realistic images.
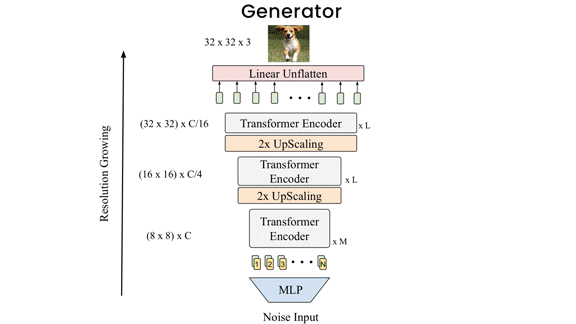
How it works: Like other GANs, TransGAN includes a generator (which, given a random input, generates a new image) and a discriminator (which, given an image, predicts whether or not it’s generated). Both components contain a sequence of transformer layers, each comprising a fully connected layer and a self-attention layer. The authors trained them simultaneously.
- Where a typical GAN’s generator uses convolutions to manipulate a two-dimensional representation, TransGAN uses transformers to manipulate a sequence and project it into a sequence of pixels. To cut the amount of computation required, the generator produces a small number of representations at the first layer and increases the number in subsequent layers.
- Convolutions typically focus on small, adjacent areas of an input to avoid unnaturally abrupt transitions. To encode similar smoothness without convolutions, TransGAN’s generator applied a mask during training that limited attention to neighboring parts of an image. The mask gradually enlarged until it covered the entire image.
- The discriminator receives an image divided into an 8x8 grid, which it converts into a sequence of 64 patches. The sequence passes through the transformer layers, ending with a linear layer that classifies the image.
Results: TransGAN set a new state of the art on the STL-10 dataset, which includes relatively few labeled examples and many unlabeled examples in a similar distribution. It achieved a Fréchet Inception Distance — a measure of the difference in distribution between generated images and training data (lower is better) — of 25.32 FID, compared to the previous state of the art’s 26.98 FID.
Yes, but: On the Celeb-A dataset of relatively high-res celebrity faces, TransGAN achieved a Fréchet Inception Distance of 12.23 FID versus HDCGAN, which is designed for higher-res output and scored 8.44 FID.
Why it matters: The transformer takeover continues! Meanwhile, TransGAN’s expanding training mask gives its output the smooth look of convolutions with better coherence across generated images. Maybe such purposeful training schedules can stand in for certain architectural choices.
We’re thinking: Transformers, with their roots in language processing, might answer the age-old question of how many words an image is worth.