
Trained on a small dataset, generative adversarial networks (GANs) tend to generate either replicas of the training data or noisy output. A new method spurs them to produce satisfying variations.
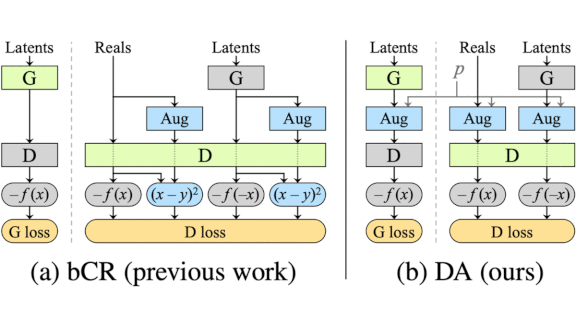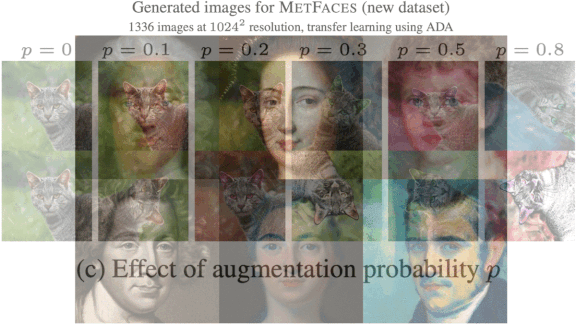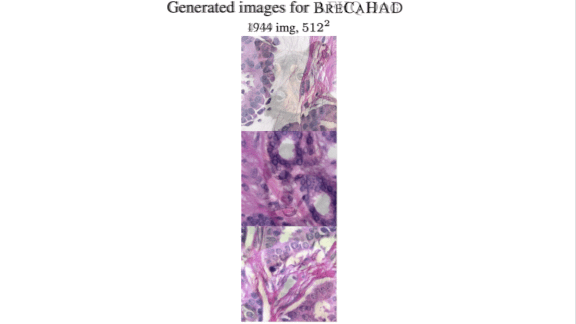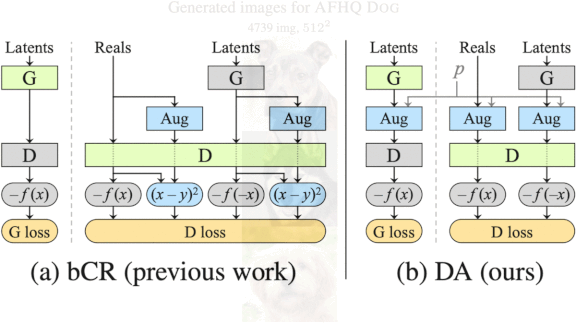
What’s new: Tero Karras and colleagues at Nvidia developed Adaptive Discriminator Augmentation (ADA). The process enables GANs to train on small datasets without overfitting, or memorizing the training set, by strategically adding training images that have been augmented via cropping, rotating, color filtering, and so on. The trick is to add augmentations in the right proportion.
Key insight: GANs learn to generate the most common types of training examples. Likewise, when trained on augmented training images, they learn to mimic the most common modifications. The authors dynamically controlled the proportion of 18 different modifications to nudge a GAN toward variety without allowing it to fixate on any particular one.
How it works: The researchers trained a StyleGAN2 on subsets of the Flickr Faces High Quality (FFHQ) dataset.
- As the model trained, ADA tracked the degree to which it was overfitting. Every fourth minibatch, it estimated the proportion of training data classified as real. The higher the proportion, the higher the indication of overfitting.
- If more than 60 percent of the training data was judged realistic, the system increased the probability that modifications would be applied. Below 60 percent, the system lowered the chance of modifications.
- Each modification was applied separately according to the same probability.
Results: Trained on 2,000 images, ADA achieved a 16.71 Fréchet Inception Distance (FID), a measure of the difference between the non-generated input and generated output in which lower is better. This score is less than a quarter that of the StyleGAN2 baseline after training on 2,000 images (78.58 FID). Furthermore, it’s roughly half the StyleGAN2 baseline using 10,000 images (30.74 FID).
Why it matters: Gathering tens of thousands of images to train a GAN is a costly chore, but gathering a few thousand is more manageable. By lightening the cost and work involved in assembling training datasets, ADA could widen the utility of GANs in tasks where data is especially scarce.
We’re thinking: Anybody else want to use this to generate a new generation of Pokémon, or is it just us?