
The technique known as dropout discourages neural networks from overfitting by deterring them from reliance on particular features. A new approach reorganizes the process to run efficiently on the chips that typically run neural network calculations.
What’s new: Pascal Notin and colleagues at Oxford and Cohere.ai introduced an alternative, SliceOut, that boosts neural network speed with little or no compromise to accuracy.
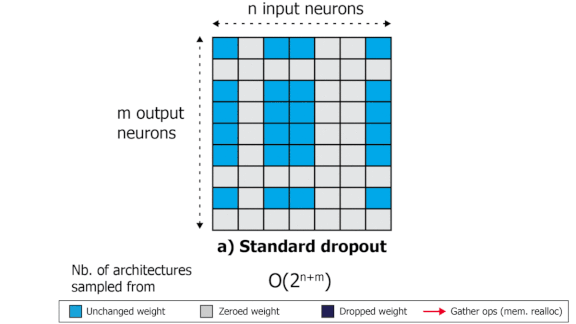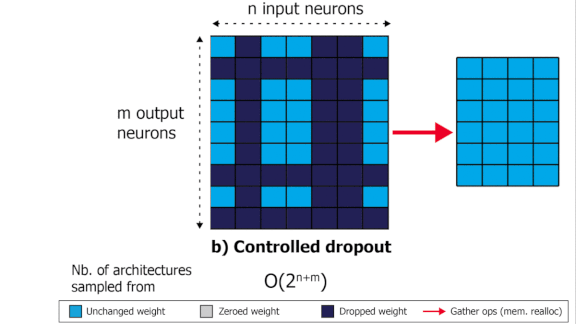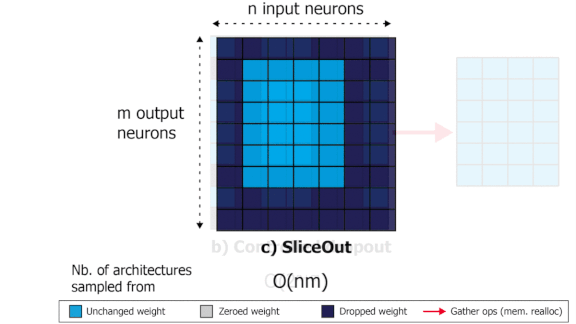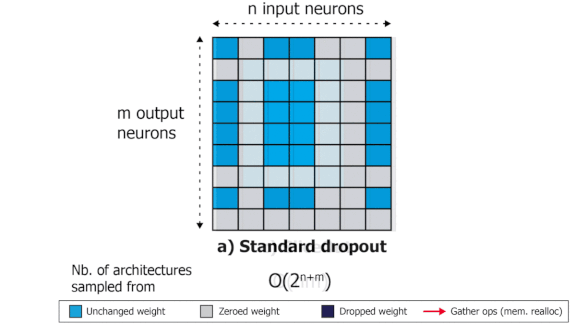
Key insight: Most operations in deep learning consist of multiplying a matrix of weights by a vector of activations or features. Deleting an input feature means a row of the weight matrix has no effect. Similarly, deleting an output feature means a column has no effect. But the resulting matrix forces the chip that’s processing the calculations to shuttle data in and out of memory, which takes time. By deleting — and keeping — only features that are contiguous in memory, the authors avoided time-consuming memory reallocations.
How it works: In its simplest form, dropout zeroes out a random selection of parameter values or, equivalently, by zeroing out the corresponding weights.
- Controlled dropout saves some processing power by collecting the remaining non-zero weights into a new, smaller weight matrix — but that still requires reallocating memory.
- SliceOut selects contiguous portions of the matrix and zeroes out everything else. This scheme is massively more efficient.
- By analyzing how GPUs compute convolutional and transformer layers, the authors developed SliceOut variants for those layers as well.
Results: The researchers evaluated SliceOut in an image-recognition task using CNNs trained on CIFAR-100, SliceOut matched dropout’s test accuracy but ran trained 33.3 percent faster and required 27.8 percent less memory. SliceOut achieved time savings of 8.4 percent and memory savings of 9 percent with transformer networks on the One Billion Word Benchmark and saved double-digit percentages in fully connected layers on MNIST.
Why it matters: Larger networks often achieve better results in a variety of tasks, but they require regularization techniques to avoid overfitting. SliceOut could enable gargantuan models to run faster than dropout allows without a hardware upgrade.
We’re thinking: As the organizers of Pie & AI, we’ll always try to make sure there’s a slice for you.