
A prestigious machine learning conference failed to highlight the highest-impact research, according to a new study.
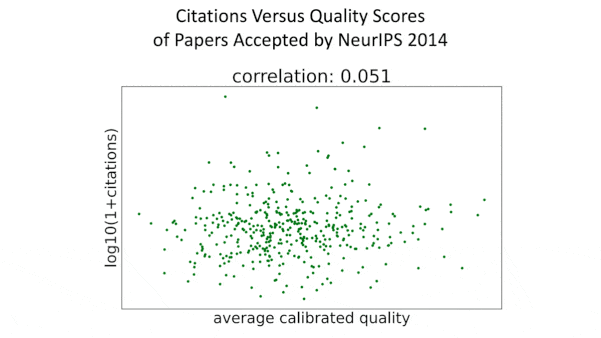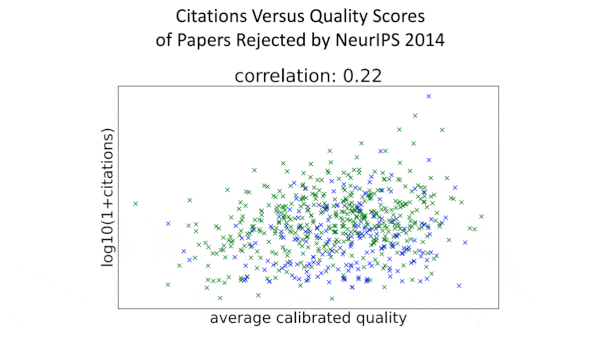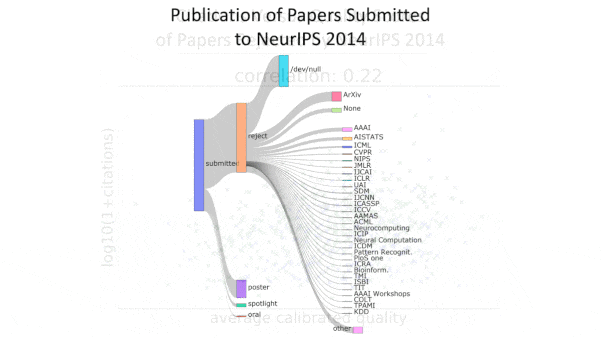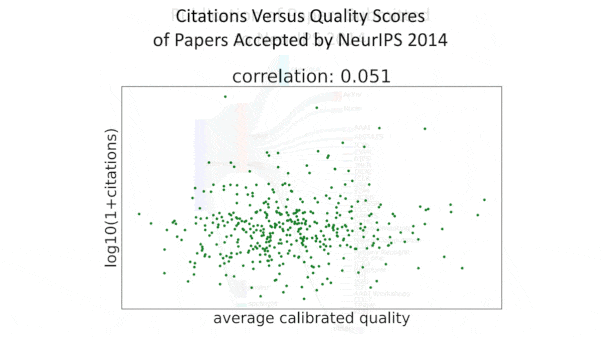
What’s new: In a retrospective analysis, researchers found that papers accepted to NeurIPS 2014 showed little correlation between the conference’s assessment of their quality and their impact on machine learning to date.
How it works: The authors — who served as the program chairs of NeurIPS 2014 — compared quality scores assigned by the conference’s reviewers with numbers of citations tracked via Semantic Scholar.
- NeurIPS typically recruits at least three reviewers to score papers for quality, and it features those with high average scores. It accepts 23.5 percent of submitted papers on average.
- The authors examined roughly 400 papers that were accepted and a random selection of 680 papers that were rejected.
- The quality scores given to papers accepted by the conference didn't correspond to the numbers of citations the papers garnered, indicating that the reviewers were bad at recognizing papers likely to have a long-term impact. The lower scores of rejected papers showed a slight correlation with lower numbers of citations, indicating somewhat greater success at filtering out papers with low long-term impact.
Recommendations: The authors suggest that future conferences, rather than relying on a single quality score, evaluate papers on various dimensions such as clarity, rigor, significance, and originality. This would provide granular assessments that could be averaged or weighted to better identify significant work.
Behind the news: This study builds on an earlier experiment in which two separate committees reviewed the same random selection of 170 papers submitted to NeurIPS 2014. The committees accepted around half of the same papers, which suggests little consistency in their criteria. NeurIPS 2021 is repeating this experiment.
Why it matters: This study calls into question the AI community’s habit of using conference presentations and journal bylines as a barometer of a researcher’s worth. The evaluation process — for NeurIPS 2014, at least — was less than robust, and the reviewers failed to notice plenty of worthwhile work.
We’re thinking: If human annotators don’t provide 100-percent accurate labels for a relatively unambiguous dataset like ImageNet, it should come as no surprise that conference reviewers don't render consistent evaluations of cutting-edge research. Predicting which research has the greatest long-term value is a challenging problem, and designing a process in which thousands of reviewers vet thousands of papers is no less thorny. The NeurIPS program chairs deserve accolades for having the courage to question the conference’s judgements. Meanwhile, it should go without saying that machine learning researchers are not defined by their conference acceptances.