
Performance in language tasks rises with the size of the model — yet, as a model’s parameter count rises, so does the time it takes to render output. New work pumps up the number of parameters without slowing down the network.
What’s new: William Fedus, Barret Zoph, and Noam Shazeer at Google Brain developed the Switch Transformer, a large-scale architecture (the authors built a version comprising 1.6 trillion parameters) that’s nearly as fast as a much smaller model.
Key insight: The approach known as mixture-of-experts uses only a subset of a model’s parameters per input example. Like mixture-of-experts, Switch Transformer chooses which of many layers would best process a given input.
How it works: The authors trained Switch Transformer to predict words that had been removed at random from a large text dataset scraped from the web. The dataset was preprocessed to remove offensive language, placeholder text, and other issues.
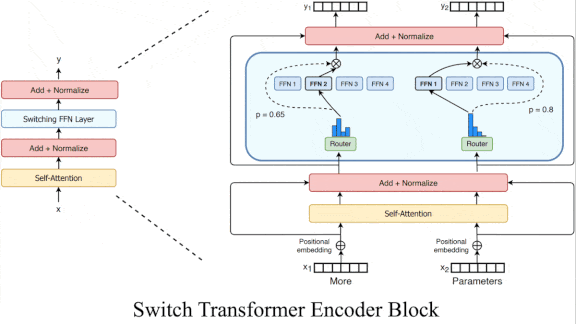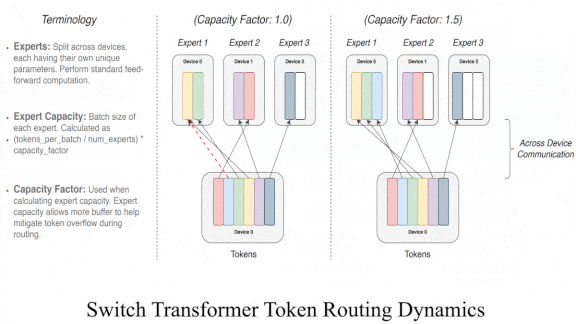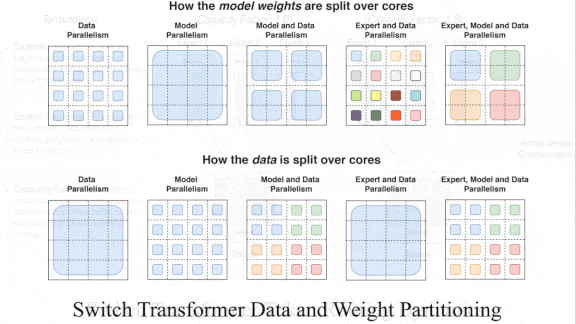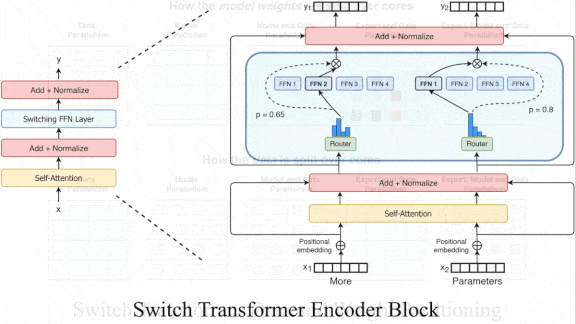
- A typical transformer extracts a representation from each input token, such as a word, and then uses self-attention to compare the representations before passing them to a fully connected layer. Switch Transformer replaces the fully connected layer with one of a number (determined by a hyperparameter) of fully connected layers.
- A softmax layer calculates the probability that any particular fully connected layer is best for processing a given token. Then it uses the chosen layer in the usual manner.
- The fully connected layers process tokens in parallel. The authors added a loss to encourage them to be equally active. On a hardware chip, a separate processor core handles each layer, so this loss encourages equal distribution of the load on each core.
Results: The authors compared Switch Transformer (7.4 billion parameters) to T5 (223 million parameters), a variant similar to the original transformer that was trained on the same dataset, using negative log perplexity, a measure of the model’s uncertainty (higher is better). The new model achieved -1.561 negative log perplexity compared to T5’s -1.731. Switch Transformer ran at two-thirds the speed of T5 — it executed 1,000 predictions per second compared to T5’s 1,600 — with 33 times the number of parameters. It beat a mixture-of-experts transformer, presumably of roughly the same size, on both counts.
Why it matters: In deep learning, bigger is better — but so is a manageable computation budget.
We’re thinking: Transformers come in an increasing variety of flavors. We hope this summary helps you remember which is switch.