
Neural networks have learned to play video games like Dota 2 via reinforcement learning by playing for the equivalent of thousands of years (compressed into far less time). In new work, an automated player learned not by playing for millennia but by watching a few days’ worth of recorded gameplay.
What’s new: Tim Pearce and Jun Zhu at Cambridge University trained an autonomous agent via supervised learning to play the first-person shooter Counter Strike: Global Offensive (CS:GO) by analyzing pixels. The model reached an intermediate level of skill. Check out a video presentation here.
Key insight: Reinforcement learning can be used to teach neural networks to play games that include a programming interface, which enables the model to explore all possible game states because gameplay proceeds much faster than real time. CS:GO lacks such an interface. An alternative is to learn from expert demonstrations, a technique known as behavioral cloning. Where such demonstrations are hard to collect, publicly broadcast matches can stand in.
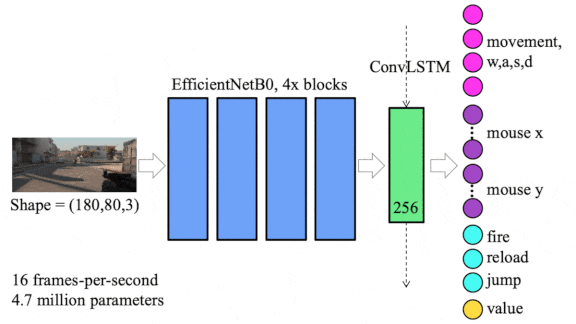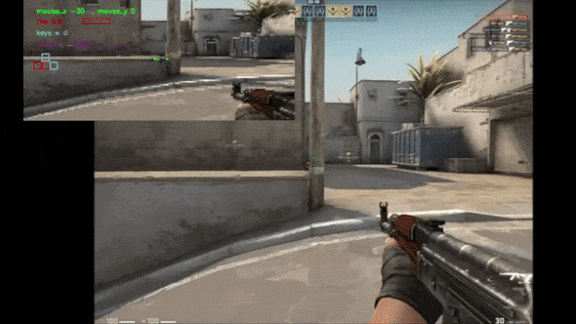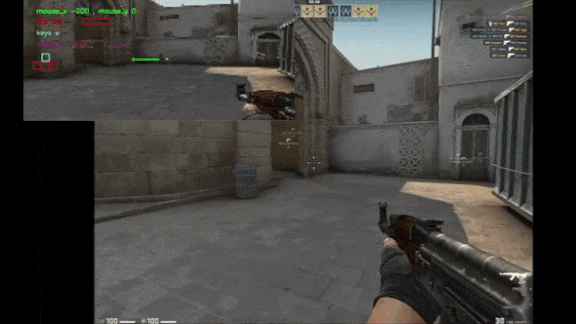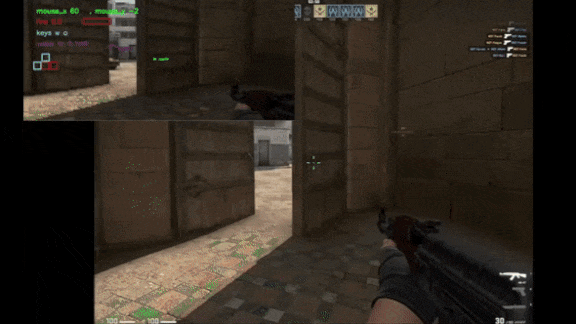
How it works: The system generated a representation of each video frame using a convolutional neural network and combined multiple representations using a convolutional LSTM. A linear layer decided what action to take per frame.
- The authors pretrained the system on 70 hours (4 million frames) of broadcast matches that pitted one team against another. They used handcrafted rules to label the frames with a player’s action: moving forward or backward, shooting, reloading, or changing the field of view.
- They fine-tuned the system on four hours (200,000 frames) of gameplay by a player who ranked in the Top 10 percent worldwide. They labeled this data using mouse and keyboard input to label the player’s action.
- During training, the system learned to minimize the difference between the predicted and recorded actions.
- At inference, the system chose how to move its onscreen character (for example, forward) and where to move the mouse cursor (which controls what the character can see) according to the model’s highest-probability prediction. It executed actions like shooting or reloading if the action’s probability was greater than a randomly generated number.
Results: Pitted against the game’s built-in medium-difficulty agent, which takes advantage of information that humans don’t have access to (such as the positions of all players), the author’s system came out on top. It achieved 2.67 kills per minute and 1.25 kills per death, compared to the built-in agent’s 1.97 kills per minute and 1.00 kills per death. Against human players in the top 10 percent, it didn’t fare so well. It achieved 0.5 kills per minute and 0.26 kills per death compared to the human average of 4.27 kills per minute and 2.34 kills per death
Why it matters: Behavioral cloning is a viable alternative to reinforcement learning — within the limits of available expert demonstrations. The authors’ system even learned the classic gamer swagger of jumping and spinning while it reloaded.
We’re thinking: We’re in the mood for a nonviolent round of Splatoon.